




双深度学习模型实现结直肠癌检测(论文复现)
本文所涉及所有资源均在传知代码平台可获取
Table of Contents
研究背景和意义
背景
结直肠癌是一种全球范围内常见的恶性肿瘤,其发病率和死亡率呈上升趋势。
早期发现对提高治疗效果和患者生存率至关重要,但传统诊断方法存在主观性和时间成本高的问题。
结直肠癌组织切片图像具有复杂结构,需要精确的图像处理技术来辅助诊断。
意义
开发基于深度学习的结直肠癌识别系统,旨在提高诊断效率,减少传统方法的局限性。
利用深度学习技术自动分类结直肠癌图像,为医生提供可靠的辅助工具,提升临床决策质量。
该系统通过自动化图像识别,有助于改善患者的治疗结果,提高生存率,同时为医学图像处理和深度学习在肿瘤诊断领域的应用提供新思路和实践基础
ResNet模型结构
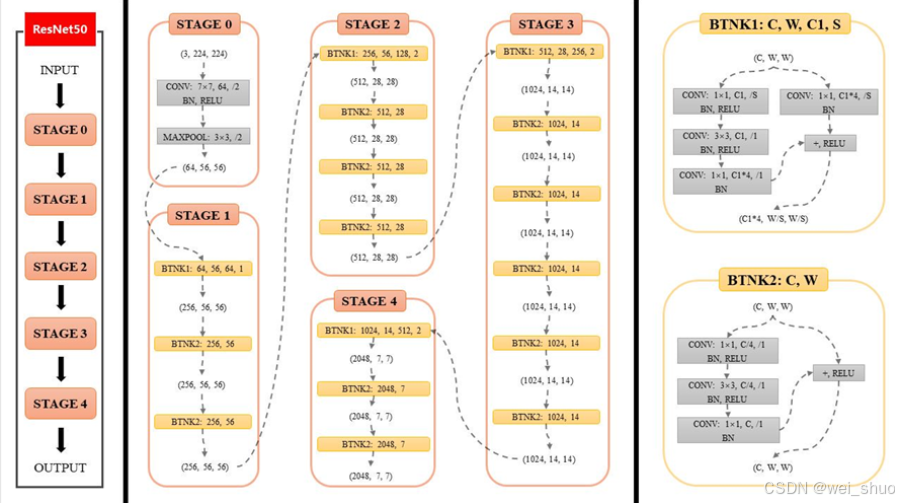
ResNet34是残差网络(Residual Networks)的一个变种,由微软研究院提出,属于深度卷积神经网络(CNN)的一种。残差网络的设计初衷是为了解决深度网络训练中的退化问题,即随着网络层数的增加,网络的性能反而下降。ResNet通过引入“残差学习”来解决这个问题,允许训练更深的网络。
ResNet34包含34个残差块,每个残差块由两个卷积层组成,中间通过跳跃连接(skip connection)连接。这种结构允许网络中的信号绕过一些层直接传递,从而缓解了梯度消失和梯度爆炸的问题
ResNet34的关键特性
1.残差学习:每个残差块学习的是层间的差异(即残差),而不是直接学习未加工的特征。这使得网络可以通过跳跃连接直接传递信息,即使网络非常深。
2.跳跃连接:跳跃连接允许网络中的信号绕过一些层直接传递,有助于梯度在训练过程中更有效地反向传播。
3.批量归一化:ResNet34在每个残差块的卷积层之后使用批量归一化,有助于加快训练速度并提高训练稳定性。
4.ReLU激活函数:在卷积层之后使用ReLU激活函数,引入非线性,增强网络的表达能力。
5.初始卷积层:在输入图像进入第一个残差块之前,首先通过一个7x7的卷积层进行特征提取,然后通过一个最大池化层进行下采样。
6.分类层:在网络的最后,使用一个全连接层(通常称为分类层)来进行图像分类
4ViT模型结构
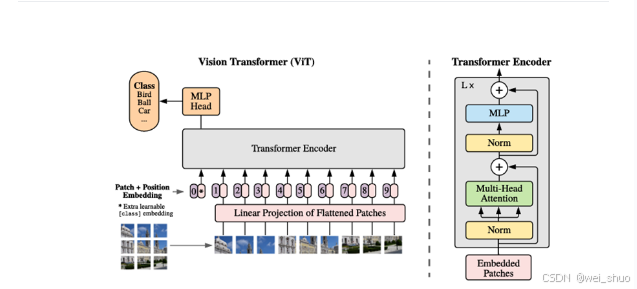
Vision Transformer(ViT)是一种用于图像识别任务的深度学习模型,由Google Research在2017年提出。ViT模型是Transformer模型在计算机视觉领域的应用,它与传统的卷积神经网络(CNN)不同,主要依赖于自注意力机制来处理图像数据
ViT模型的关键特性
自注意力机制:ViT模型的核心是自注意力机制,它允许模型在处理图像时考虑全局依赖关系,而不是仅依赖局部感受野。
无卷积操作:与CNN不同,ViT模型不使用卷积层。它将图像分割成大小相同的小块(patches),然后将这些小块线性嵌入到一个序列中,再应用标准的Transformer结构。
位置编码:由于Transformer模型本身不具备捕捉序列顺序的能力,ViT为图像块添加了位置编码,以保持图像的空间结构信息。
分类任务的头部:ViT模型通常在Transformer结构的顶部添加一个全连接层,用于图像分类任务
ViT模型的工作流程
1.图像分割:将输入图像分割成大小为(16x16)像素的小块,例如,对于一个(224x224)像素的图像,会得到(14x14)个小块。
2.线性嵌入:每个小块通过一个线性层进行嵌入,将小块的像素值映射到一个高维空间。
3.位置编码:为每个嵌入后的小块添加位置编码,以保持其在原始图像中的位置信息。
4.Transformer编码器:将编码后的序列输入到一个或多个Transformer编码器层中,每层都包括自注意力机制和前馈网络。
5.分类头部:在Transformer编码器的输出上应用一个全连接层,将特征映射到类别标签上
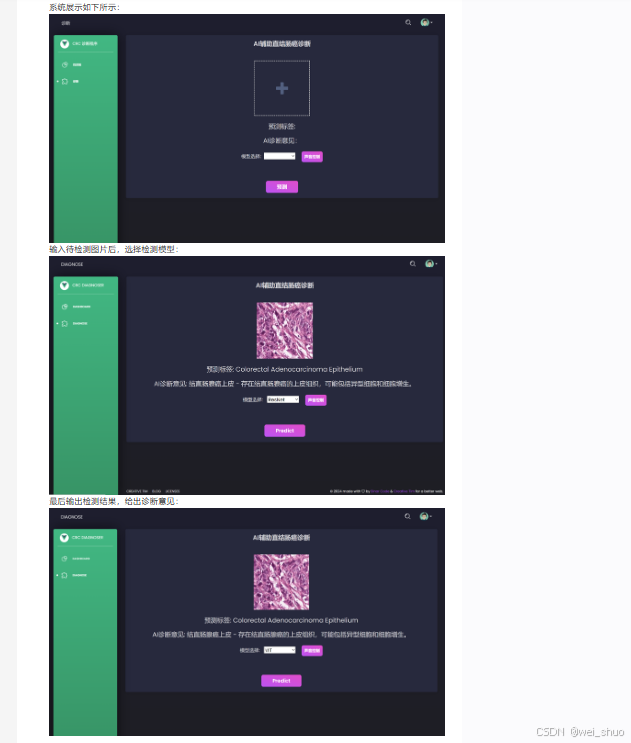
演示效果
acc可视化结果如下图所示


loss可视化结果如下图所示
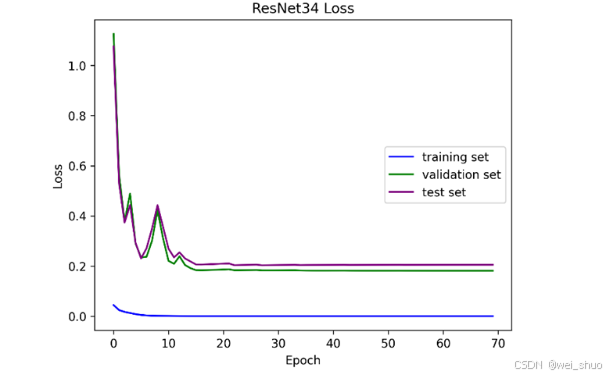
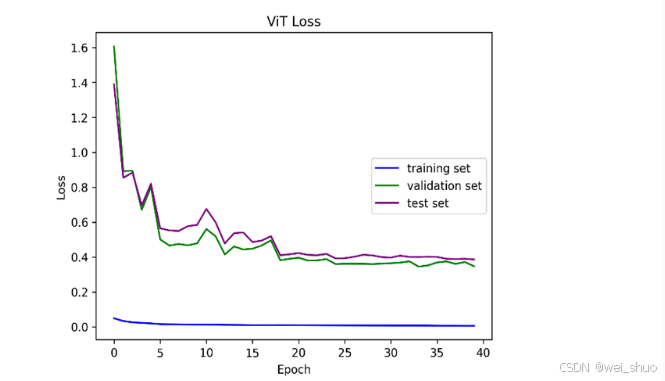
核心逻辑
ResNet部分代码如下
class ResNet(nn.Module):
def __init__(self, block, layers, nums, num_classes, type) -> None:
super(ResNet,self).__init__()
self.arch = type
self.conv1 = nn.Conv2d(in_channels=3, out_channels=layers[0], kernel_size=7, stride=2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(layers[0])
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.in_channels = layers[0]
self.layers = torch.nn.Sequential(
self._make_layers(block, layers[0], nums[0]),
self._make_layers(block, layers[1], nums[1], stride=2),
self._make_layers(block, layers[2], nums[2], stride=2),
self._make_layers(block, layers[3], nums[3], stride=2)
)
self.size = layers
self.avg = nn.AvgPool2d(kernel_size=7)
self.linear = nn.Linear(layers[3]*block.expension, num_classes)
self.relu = nn.ReLU(inplace=True)
ViT模型部分实现代码如下
class ViT(nn.Module):
def __init__(self, embed_dim=768, n_head=12, num_classes=9, depth=6,
in_chans=3, input_size=224, patch_size=16, drop_rate=0.2,
ffn_radio=4) -> None:
super().__init__()
self.encoder = nn.ModuleList([EncoderLayer(embed_dim=embed_dim, n_head=n_head, ffn_radio=ffn_radio, dropout=drop_rate) for _ in range(depth)])
self.norm = nn.LayerNorm(embed_dim)
self.cls = nn.Linear(embed_dim, num_classes)
self.patch = PatchEmbedded(in_chans, input_size, patch_size, drop_rate)
def forward(self, x):
x = self.patch(x)
for layer in self.encoder:
x = layer(x)
x = self.norm(x)
x = self.cls(x[:,0])
return x
部署方式
所有数据文件以及训练模型在附件的下载链接中,根据解压后的文件readme的指令即可完成部署与运行
创新之处
通过上述内容,本研究在以下几个方面具有原创性和创新点:
1.深度学习模型的选择与应用:结合ResNet和ViT两种不同的深度学习模型,充分利用了卷积神经网络和Transformer的优势,提高了图像分类的准确性和效率。
2.自动化图像识别系统:开发了一个自动化的结直肠癌识别系统,为临床医生提供了一个高效、准确的辅助诊断工具,减少了传统方法的主观性和时间成本。
3.可视化效果展示:通过详细的可视化结果展示了模型的性能,增强了研究的直观性和说服力。
4.具有语音操作的功能,可以通过语音来实现对系统的操作,同时可以给出专业的AI诊断意见
文章代码资源点击附件获取
