




背景:
前两天上午突然收到告警,observer进程不存在。赶紧检查集群,发现告警集群的三台server处于inactive的状态,该集群架构为3-3-3。平时业务的primary_zone是zone3,sys租户的primary_zone在zone1,inactive的是zone1的两台机器。zone2的一台机器,zone1是一个机房,zone2和zone3在另外的机房,万幸的是业务反馈告警时候断连了一批业务,重新拉起来就好了。
现象和排查过程:
因为生产环境比较重要,问题一出,我们就找原厂同学提工单,透传研发紧急分析了。
因为我们监控告警有显示端口不通,检查当时的网络有丢包,怀疑是网络问题触发的诱因。
登录主机检查发现inactive的机器上observer进程还在,通过2881连接inactive的节点也可以登录。
检查时钟正常
clockdiff -o xx.xx.xx.xx归档也卡在了问题时间点,位点不再推进

按照研发老师的指导,分别对各个rs节点进行了队列积压的检查,并未发现异常。
grep 'dump tenant info' observer.log |grep -v 'total_size=0'检查各rs节点的rootservice有没有切主上任日志,发现有4019的WARN日志。
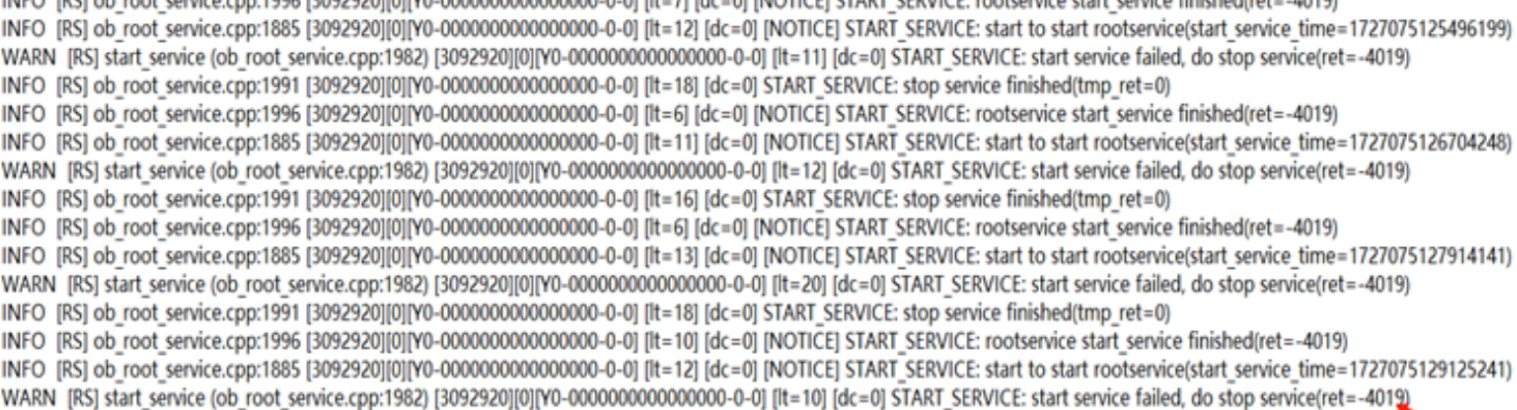
通过2881分别连接rs节点的sys租户,查询以下sql报错timout。
select * from __all_virtual_clog_stat where svr_port=2882 and table_id=1099511627777;测试了下。zone3的rs节点可以查询到另外两个节点的信息,zone2的rs节点查询zone1节点的信息就报错,zone1的rs节点查询zone2的rs节点信息报错。sql如下案例。

这时候还发现一个现象,在__all_server视图中查询到的rs主是zone1的rs节点,但是从__all_virtual_clog_stat视图查到的leader是zone2的rs节点。
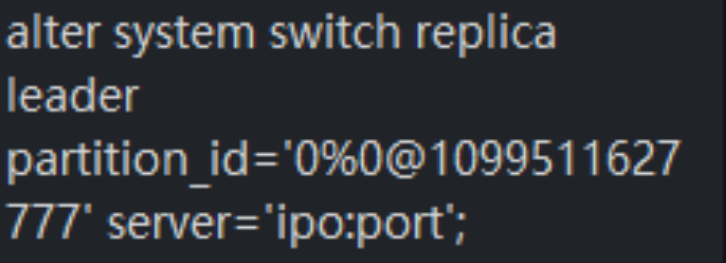
alter system switch rootservice leader zone 'zone1';执行上面两个切主命令,报错"rootserver is not the master"。
尝试重启下zone1的已经inactive的rs节点,重启时发现无法启动,也会报"rootserver is not the master"。
研发同学根据4019的报错,确定是一个已知问题,建议对zone2的rs节点进行线程数调整的动作。
./ob_admin -h xx.xxx.1xx.xx -p 2882 set_server_config _ob_max_thread_num=8192
##observer的线程数上限制 默认是4096修改完zone2的rs节点的线程数限制后,再次重启zone1的rs节点,成功启动了,这时候再去库里检查__all_virtual_clog_stat,leader切回了zone1的rs节点,与__all_server显示的rs一致,其他inactive的节点也依次拉起了。
后续研发老师建议窗口期将所有的rs节点轮转重启一下。
其实在同一网络波动时间,还有另外一套集群发生问题,但是现象不太一样,该集群的所有节点状态正常,但是归档位点不推进了,__all_virtual_clog_stat和__all_server的rs信息也不一致。
但是检查该集群的zone2的rs日志,有ERROR的4019报错
[root@xxxxxxxxxxx /home/admin/oceanbase/log]$ grep 'START_SERVICE' rootservice.log | tail -50 [2024-09-23 11:09:06.362722] INFO [RS] ob_root_service.cpp:1885 [2664061][0][Y0-0000000000000000-0-0] [lt=21] [dc=0] [NOTICE] START_SERVICE: start to start rootservice(start_service_time=1727060946361374) [root@xxxxxxxxxxx /home/admin/oceanbase/log]$ grep '2664061' rootservice.log | tail -50 [2024-09-23 11:09:06.362698] INFO [SHARE] ob_event_history_table_operator.h:258 [2664061][0][Y0-0000000000000000-0-0] [lt=0] [dc=0] event table add task(ret=0, event_table_name="__all_rootservice_event_history", sql=INSERT INTO __all_rootservice_event_history (gmt_create, module, event, name1, value1, rs_svr_ip, rs_svr_port) VALUES (usec_to_time(1727060946362644), 'root_service', 'start_rootservice', 'self_addr', '"11.111.111.11:2882"', '11.111.111.11', 2882)) [2024-09-23 11:09:06.362722] INFO [RS] ob_root_service.cpp:1885 [2664061][0][Y0-0000000000000000-0-0] [lt=21] [dc=0] [NOTICE] START_SERVICE: start to start rootservice(start_service_time=1727060946361374) [2024-09-23 11:09:06.365854] WARN log_user_error_and_warn (ob_rpc_proxy.cpp:326) [2664061][0][YB420A66E12D-00061BD6AB07C75E-0-0] [lt=6] [dc=0] [2024-09-23 11:09:06.369627] WARN [SHARE] do_detect_master_rs_v3 (ob_rs_mgr.cpp:572) [2664061][0][YB420A66E12D-00061BD6AB07C760-0-0] [lt=11] [dc=0] ObTaskType::GENERIC REACH SYSLOG RATE LIMIT [2024-09-23 11:09:06.384256] INFO [LIB] co_protected_stack_allocator.cpp:84 [2664061][0][Y0-0000000000000000-0-0] [lt=14] [dc=1] stack memory allocated(tenant_id=500, stack_size=2113536, ptr=0xff5c2184b000) [2024-09-23 11:09:06.385728] INFO [LIB] co_protected_stack_allocator.cpp:84 [2664061][0][Y0-0000000000000000-0-0] [lt=13] [dc=0] stack memory allocated(tenant_id=500, stack_size=2113536, ptr=0xff5c20a4b000) [2024-09-23 11:09:06.386173] ERROR [LIB] start (thread.cpp:99) [2664061][0][Y0-0000000000000000-0-0] [lt=9] [dc=0] thread count reach limit(ret=-4019, current count=3968) BACKTRACE:0xeed8e58 0xabcb168 0x494bf18 0x494bafc 0x494b9d0 0xabd28d0 0xedadd5c 0xedad958 0xedad15c 0xedad598 0xf02ea3c 0xf02e4c0 0x6124870 0x83bc0e4 0xb33404c 0xb33313c 0xb332e1c 0x4a54d00 0xedb4018 0xedb3e5c 0xf05165c
在这个集群上修改zone2的rs节点的线程数限制,并没有恢复,研发老师怀疑ERROR后没有其他日志信息输出,可能是rs线程僵死了,需要重启该节点,果然重启zone2的rs后整个集群恢复正常。但是仍然建议把所有rs节点轮流重启一下。
总结:
至于为什么第一个集群有inactive节点,第二个集群没有inactive,怀疑是网络波动影响程度不同,也有偶发原因,可能正好observer回传心跳信息丢失导致rs认为节点inactive。
从其中现象来看,是因为网络波动,rs的主从zone1切到了zone2,但是触发了observer的bug导致线程满了,网络恢复后,zone2的rs没有正常卸任,造成rs无主的情况,但是第二套集群因为4019报的ERROR可能是线程僵死,所以调大线程限制后也没有恢复,重启后才恢复。
至于归档时间,是归档完后,需要汇报给RS,但是这里rs没有上任成功,就无法推进备份时间,这里就显示卡住。
最后研发建议升级到3.2.3 BP10 hotfix7之后版本,会有该问题的修复。
