




刻骨铭心的报错3.x版本下“failed to check macro block(ret=4034”
 2024-10-08
2024-10-08
场景描述:
某套集群架构为1-1-1,备集群有个单节点,在这里描述为ABC三个节点吧,业务租户指定了primary_zone在一个zone称为C节点。巡检过程中发现业务主zone节点的vgs不显示日志盘了,这时候因为集群还正常运行,所以规划等版本停业务,修复该机器,也预留了空闲机器,以防万一进行替换。
版本期间手工进行业务租户切主到B节点,通过ocp停止该节点进程后尝试修复日志盘,未成功,使用空闲机器D进行该主机的替换,但是数据一直不同步,因为问题机器进程也无法启动了,通过调整server_permanent_offline_time和replica_safe_remove_time参数使问题节点下线。
观察数据同步情况,发现磁盘使用涨一点过会就回退了,原厂老师分析发现从A,B节点同步副本到新的D节点时因为B节点的数据损坏导致失败了,日志中存在“failed to check macro block(ret=4034”的报错。
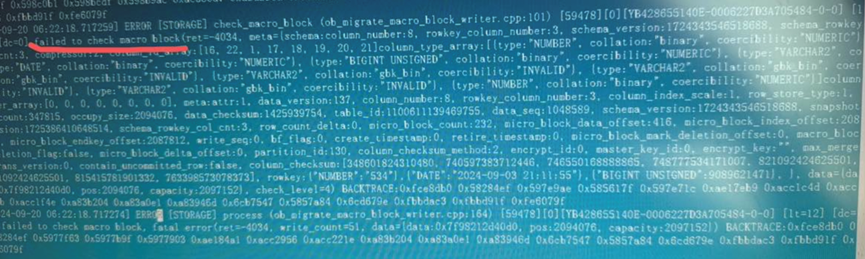
deserialize error通常表示源端的宏块损坏 failed to check macro block也能说明,确实宏块损坏 #我在后来回查官网资料的时候发现有内部视图也会记录 select * from __all_virtual_bad_block_table;
通过select sum或者max的方式查询该表,确实会报错

原厂同事测试了下可以从A节点复制表到D,但是因为集群的builtin_db_data_verify_cycle坏块自检参数默认是20天,所以不知道有哪些表数据损坏,手工复制处理效率会很低,可以使用下面SQL查找所有缺副本的分区。
select concat('alter system copy replica partition_id = "', partition_id, '%', partition_cnt, '@', table_id, 'source = "ip:2882" destination = "ip:2882" force;') from ( select table_id,partition_id,partition_cnt from __all_virtual_meta_table group by 1,2,3 having count(*) = 2 );
确认业务没有访问到坏块数据,还没有发生有损,确认备集群的数据没有问题,对B节点有坏块的表进行抽样校验没有问题。抓紧时间扩容备集群成1-1-1的架构,因为备集群其他节点是从第一个节点复制的,不会对主集群有明显影响。
等晚上低峰期进行switchover,调整业务连接到新主库。
运行几天无异常后,铲除备集群(原主集群),先用D节点搭建单节点备库。搭建没有问题,延迟正常后,将A以及B节点加入集群。
后续问题:
后续巡检时发现B节点的主机message日志中有数据盘的error信息


怀疑B节点是磁盘坏块,A节点当时可能是有逻辑坏块。联系主机侧同事将当时踢出集群的C节点进行系统和raid重装,重装后重新分盘格式化,主机初始化。
将C节点进行主机替换替换B节点,后续巡检,没有发现IO报错。
其他整理:
1.该集群的clog比较大,导致初始搭建备集群时,延迟追不上,开启主库归档,会把日志盘io打满,导致归档延迟增大。
备集群搭建:调整rebuild_replica_data_lag_threshold参数,及时进行副本重建。
根本原因及解决:业务分区数比较多,存在频繁的update,但是未指定分区键,因为CLOG分redo log/prepare log/commit log/clear log 等,被更改的分区有这所有类型的log;未更改的分区除了缺少redo,其它的log都会有,而且OB默认采用了"binlog_row_image=FULL"的模式否则OMS无法正常工作,导致CLOG放大很多倍。
进行业务调整后,clog日志从每小时将近300G下降到10G。
2.排查分区复制失败
>在__all_virtual_rebalance_task_stat中寻找当前正在复制的分区,并判断是否已经卡住多时
>基于上述分区信息(table_id与partition_id),在目标端的observer日志中,搜索包括"ob_partition_mig"关键字的信息,并获取对应的trace_id
grep "ob_partition_mig" observer.log |grep "tid:xxx, partition_id:xxx"
>基于上述trace_id,在目标端observer.log中搜索
grep "trace_id" observer.log > trace_id.log
>基于该trace_id.log,查看其中的WARN与ERROR内容,并定位最终原因
__all_virtual_sys_task_status:系统任务状态表。该表中有task_id,可以kill,使用命令all system cancel task 'task_id' __all_virtual_rebalance_task_stat:如果有rebalance操作(比如说复制副本),该表中会有正在运行作业的记录。另外该表中,is_scheduled字段如果值Yes,代表当前运行任务;如果值是No,代表等会要运行任务 __all_rootservice_event_history:是否有正在执行的负载均衡任务,该表对于历史作业依然会记录。另外,对这张表而言,查看副本复制作业完成与否情况(不能完全精准,有可能这里显示成功实际日志查看失败,可以作为参考) select * from __all_rootservice_event_history where event like 'finish%replica%' and value3 != 0 order by gmt_create desc limit 10\g; -- 不为0代表失败;等于0一般代表成功(仅作参考,需要结合实际分区是否复制成功并结合日志确认) __all_rootservice_job:如果ocp中替换操作,或者黑屏进行alter tenant的locality操作等会在此记录 __all_virtual_meta_table:系统分区的元数据表,可查看各个分区副本所在节点以及副本大小等 grep -E 'print band limit|succeed to init_bandwidth_throttle' observer.log -- 查看复制时候带宽情况
3.如果在添加副本时,要添加的主机发生hang机导致任务失败的话,可能需要手工回退
1.5副本回到3副本,修改locality ALTER TENANT `xxxxx` LOCALITY = 'FULL{1}@zone1, FULL{1}@zone2,FULL@zone3'; 该步骤运行之后,检查__all_rootservice_job select * from __all_rootservice_job order by gmt_create desc limit 1\G 预计25分钟可能运行结束 注:此时检查__all_virtual_rebalance_task_stat中是否还有残留(之前新增节点导致的副本复制),如果有,运行如下步骤 alter system switch rootservice leader zone 'zone3'; -- 改到新的可用zone上 alter system set balancer_idle_time = '10s'; -- 后续要改回去 2.租户缩减resource pool list(resource_pool_list个数从5到4再到3) ALTER TENANT `xxxxx` RESOURCE_POOL_LIST=('__resource_pool_1001','pool_xxxxx_zone3_fsb','pool_xxxxx_zone2_svr','pool_xxxxx_zone4_bzc') ALTER TENANT `xxxxx` RESOURCE_POOL_LIST=('__resource_pool_1001','pool_xxxxx_zone3_fsb','pool_xxxxx_zone2_svr'); 3.删除resource pool与unit drop resource pool pool_xxxxx_zone4_bzc; drop resource pool pool_xxxxx_zone5_evu; drop resource unit config_xxxxx_zone4_yy6_bzc; drop resource unit config_xxxxx_zone5_yy6_evu; 4.删除observer alter system delete observer '111.11.11.35:2882'; alter system delete observer '111.11.11.36:2882'; 此时故障节点111.11.11.35在__all_server表中会持续deleting状态,修改如下参数 server_permanent_offline_time -> 30m -- 后续改回去 replica_safe_remove_time -> 30m -- 后续改回去 5.删除zone alter system stop zone zone4; alter system delete zone zone4; alter system stop zone zone5; alter system delete zone zone5; 6.检查 select * from __all_virtual_replica_task; -- 结果为0 select table_id,partition_id,partition_cnt from __all_virtual_meta_table group by 1,2,3 having count(*) != 3; -- 结果为0(回到3副本)
总结:
这次遇到的情况,现在回想也是心有余悸,回头整理下也确实涨了不少经验,生产环境一定要做好巡检和容灾备份,这次场景的集群,没有近期成功的归档备份,3副本主集群,变更后只有两个完整副本了,还都出现了坏块,幸好有个完好的备集群节点,要不然后果不可想象。我深刻认识到可能任何一份冗余的手段,都会是最后拯救自己职业生涯的救生圈。
行之所向,莫问远方。
