




引言:
诗经有言“不敢暴虎,不敢冯河。人知其一,莫知其他。 战战兢兢,如临深渊,如履薄冰。“
可是就算事先做好再多的预防和准备,也都会有可能发生问题,当然提前准备的越充分越全面,出问题的概率会更低,更安全。
现象:
某套数据库从oracle环境进行国产化替换到OB后第二天,大量业务报错4013。

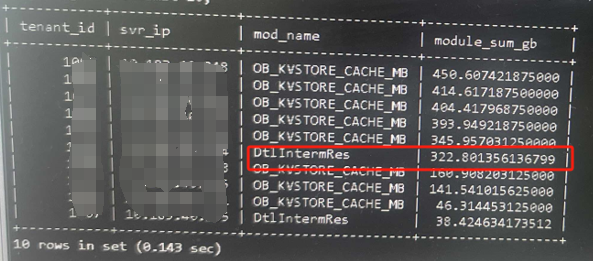
通过sql检查内存模块。
select now(),tenant_id,svr_ip,mod_name,hold/1024/1024/1024 hold_G
from __all_virtual_memory_info
order by hold desc limit 10;
检查问题节点日志
grep “\[OOPS\]” observer.log
grep “\[MEMORY\]” observer.log
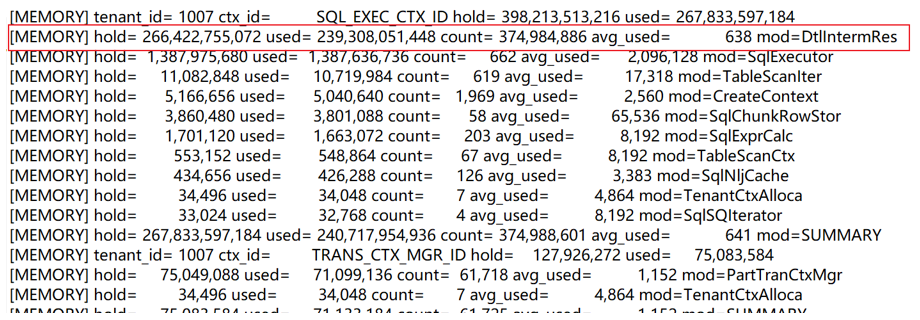
很明确就是dtl内存模块出问题了,占用了大量的内存,还未释放或者说未及时释放。
再根据grep “clear dtl” observer.log来查询dtl的释放情况。
上述日志中,expire_keys表示当时超时了的中间结果,数量如果不为0,也能说明可能有内存不释放问题。
排查过程:
其实官网知识库有该问题的一个记录,链接为 https://www.oceanbase.com/knowledge-base/oceanbase-database-1000000000426769?back=kb
有明确的影响版本,基本也能确定是一个问题。
| OceanBase 数据库 V2.2.77 BP18(oceanbase-2.2.77-118000012023052520)、V3.1.2 BP11(oceanbase-3.1.2-111000052023010412)、V3.2.3 BP10(oceanbase-3.2.3.3-110000092023091219)、V3.2.4 BP5(oceanbase-3.2.4.5-105000012023081513)、V4.1.0 BP2(oceanbase-4.1.0.1-102000042023061309)及之前的 BP 版本。 |
|---|
那么临时规避方法也可以采用这篇文章的方法。
| 对于存在这样问题的 SQL,可以使用 hint /*+ parallel(2) */ 开启并行,并行度大于 1 时是流式执行,不会写中间结果。 |
|---|
但是怎么去找到问题sql就是重中之重了,毕竟这个系统是个核心tp系统,库里有大量的sql,很难定位到是哪一条语句导致的。
其实官网介绍中也有写也可以通过__all_virtual_dtl_interm_result_monitor视图找到对应的trace_id,但是真正dtl模块占用很高的时候,这个视图会变得很大,对该视图的查询会打爆sys租户的内存。所以也无法通过这个途径定位。
Select trace_id,hold_memory/1024/1024/1024 hold_memory_G From __all_virtual_dtl_interm_result_monitor Where svr_ip = ‘xxx’ Order by hold_memory desc Limit 20; 再通过trace_id结合gv$sql_audit查找对应的SQL_ID
那实际排查起来就需要通过一些关键条件来广撒网了。
首先,我们要时刻注意dtl模块占用,如果到了危险值,及时与业务沟通手动切主,减少影响。
SELECT tenant_id,svr_ip,mod_name,sum(hold/1024/1024/1024) module_sum_gb FROM __all_virtual_memory_info WHERE tenant_id >1000 and tenant_id <2000 AND hold <> 0 and mod_name='DtlIntermRes' AND mod_name not in('OB_KVSTORE_CACHE_MB','OB_MEMSTORE','OB_KVSTORE_CACHE') GROUP BY tenant_id,svr_ip,mod_name ORDER BY module_sum_gb desc;
其次我根据研发提供的一些触发条件对关键算子来进行匹配,找到一些怀疑sql(等内存模块变化之后马上抓一部分sql)。
select SQL_ID,count(*) from gv$sql_audit where tenant_id=1999 and USER_NAME='xxxx' and TRACE_ID in ( select distinct a.TRACE_ID from (select TRACE_ID ,PLAN_OPERATION from gv$sql_plan_monitor where PLAN_OPERATION ='PHY_SUBPLAN_FILTER' and FIRST_REFRESH_TIME >= now() - interval '600' second) a inner join (select TRACE_ID ,PLAN_OPERATION from gv$sql_plan_monitor where PLAN_OPERATION like '%PX_FIFO_COORD%' and FIRST_REFRESH_TIME >= now() - interval '600' second) b on a.TRACE_ID=b.TRACE_ID ) and request_time > time_to_usec(now() - interval 600 second) and sql_id<>'' group by SQL_ID order by 2 desc limit 20;
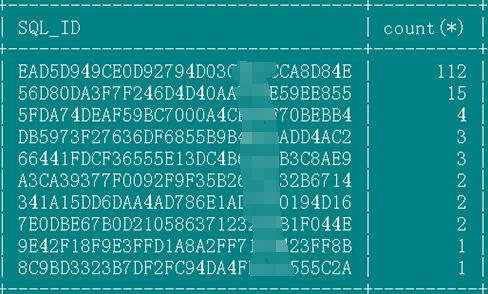
这次通过上述sql就抓到了问题sql,但后来复盘问题发现上述sql的信息有可能会漏掉一些情况,所以又完善了下。
select SQL_ID,count(*) from gv$sql_audit where tenant_id=1999 and USER_NAME='XXXX' and TRACE_ID in ( select distinct a.TRACE_ID from (select TRACE_ID ,PLAN_OPERATION from gv$sql_plan_monitor where PLAN_OPERATION ='PHY_SUBPLAN_FILTER' and FIRST_REFRESH_TIME >= now() - interval '600' second) a inner join (select TRACE_ID ,PLAN_OPERATION from gv$sql_plan_monitor where PLAN_OPERATION like '%PX_FIFO_COORD%' and FIRST_REFRESH_TIME >= now() - interval '600' second) b on a.TRACE_ID=b.TRACE_ID union select distinct c.TRACE_ID from (select TRACE_ID ,PLAN_OPERATION from gv$sql_plan_monitor where PLAN_OPERATION ='PHY_NESTED_LOOP_JOIN' and FIRST_REFRESH_TIME >= now() - interval '600' second) c inner join (select TRACE_ID ,PLAN_OPERATION from gv$sql_plan_monitor where PLAN_OPERATION like '%PX_FIFO_COORD%' and FIRST_REFRESH_TIME >= now() - interval '600' second) d on c.TRACE_ID=d.TRACE_ID ) and request_time > time_to_usec(now() - interval 600 second) and sql_id<>'' group by SQL_ID order by 2 desc limit 20;
最后,抓到的这部分的sqlid是问题sql的概率最大,我们可以都绑定/*+parallel(2)*/的outline,这部分sql_id也可以分为两种,一种以前没有outline,另一种就是已经有outline了。
对于没有outline的直接绑定/*+parallel(2)*/就可以了,已经有outline的sql在原有outlinedata的基础上加上/*+parallel(2)*/就可以了。
当上述OUTLINE绑定后,观察内存增长情况。本次案例中,DTL内存被控制住,所以怀疑点在上述的SQL_ID中,后续只要逐步放开OUTLINE,即可定位问题SQL。(如果还未控制,可以排除已经绑定/*+parallel(2)*/的sqlid再多次抓一下)
复盘:
后来与ob同学沟通复盘了下该问题,原因是batch rescan优化的过程中,如果上一个batch的数据没读完,比如上方有limit, 或者nested semi/anti join, 并且batch大小会变(batch本身固定大小是8192行,除非没有那么多行可以读),会就导致上一个batch尾部有一些中间结果没释放。我的简单理解如下。
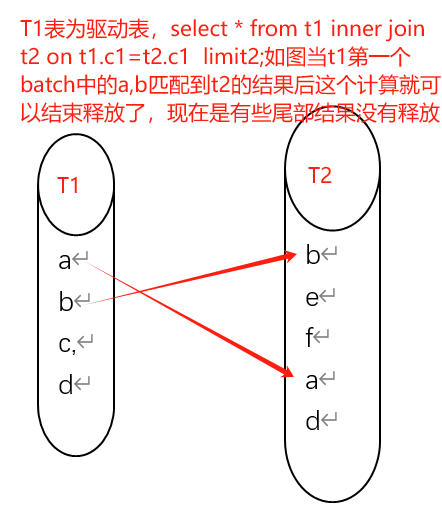
对于该问题的触发条件,与研发同学的交流中也基本确定了三个条件(第二条中的两个是或的关系)。
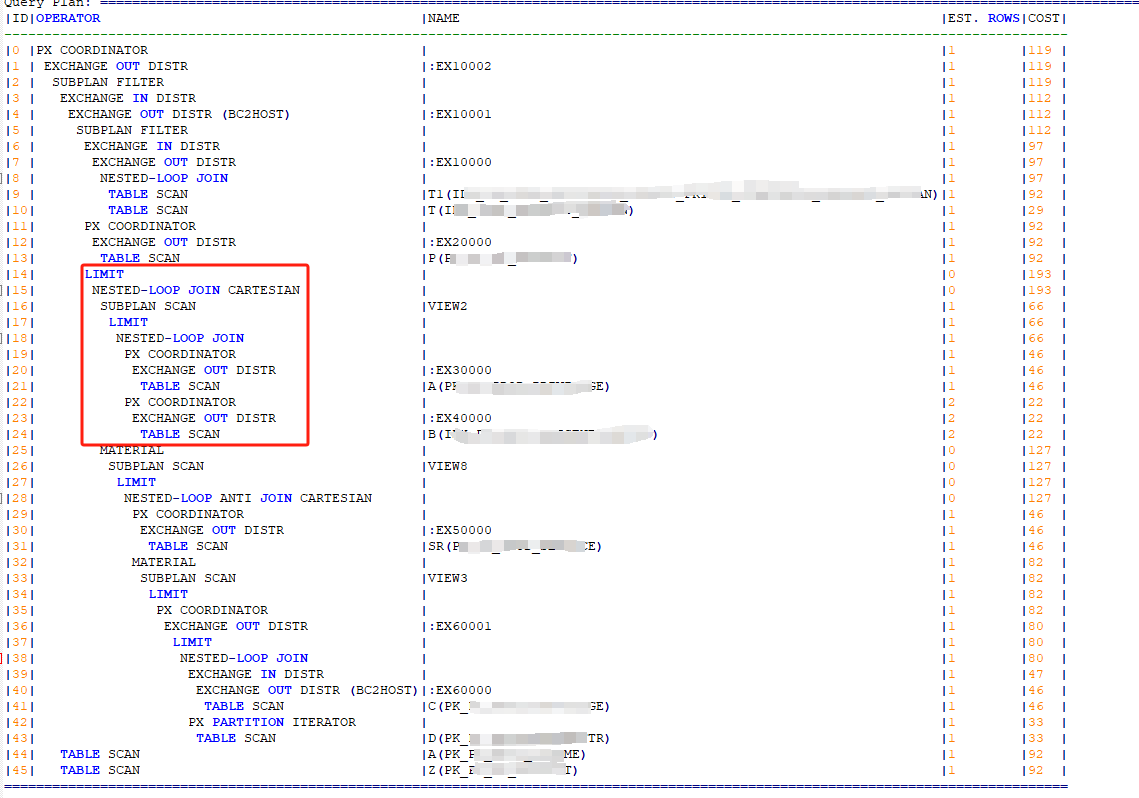
- nestedloop join或者subplan filter走了px batch rescan (这个算子我们先称为a算子) 所以一定有px和batch rescan,执行计划的Outputs & filters中一般体现为px_batch_rescan
- >第一个条件中的算子处于subplan filter或者nestedloop semi/anti join的右支
>第一个条件中的算子处于nestedloop join (这个算子我们标记为b算子)右支并且这个b算子上方存在limit
- nestedloop join中的左支数据来自nl外部,计划的算子的Outputs & filters中有range_cond([? = A.xxxx(0xff4fe085edc0)(0xff4fe085f750)])的标记
所以我们通过排除的方式确定问题sql后再回看计划确实符合上述的条件。


结论:
到这里基本这次问题的影响版本,原因,规避方式,都很清楚了,研发也在新版本path上修复了该问题。
这次的排查和复盘过程也是受益良多,记录下细细回味。
行之所向,莫问远方。
