




前言
不管数据库在性能上有多么的优秀,在使用一段时间后性能都会有所下降。引起性能下降的原因有很多,如数据量大,SQL复杂、缺少索引等等方面。
前面有文章介绍过《Halo数据库性能诊断工具—HWR》,里面用到了pg_stat_statements扩展,这次仍然是通过这个扩展,可以直接查询出最消耗CPU、内存、执行时间等各种资源的SQL语句。
1、
安装pg_stat_statements扩展
pg_stat_statements是一个扩展插件,用于收集和记录SQL语句的执行统计信息。它可以帮助DBA分析数据库中最常执行的查询、最耗时的查询以及其他可能影响性能的查询模式。通过这些信息,DBA可以对数据库性能进行深入分析,从而优化查询、调整索引策略、改进数据库配置等。
1.1 增加pg_stat_statements采样参数
修改postgresql.conf文件 :
##
PG_STAT_STATEMENTS OPTIONS
shared_preload_libraries='pg_stat_statements' # (change requires restart)
pg_stat_statements.max= 10000 #pg_stat_statements中记录的最大的SQL条目数,默认为5000
pg_stat_statements.track=
all #记录pg_stat_statements中的
pg_stat_satements.save=on
#用来控制数据库在关闭的时候,是否将SQL信息保存到文件中。默认打开
pg_stat_satements.track_utility=on
#追踪SQL命令:DQLDDL 以及DQL,DDL以外的其他SQL命令(off只记录DQLDDL)

变更配置后需要重启数据库

1.2 安装pg_stat_statements扩展
create extension pg_stat_statements;

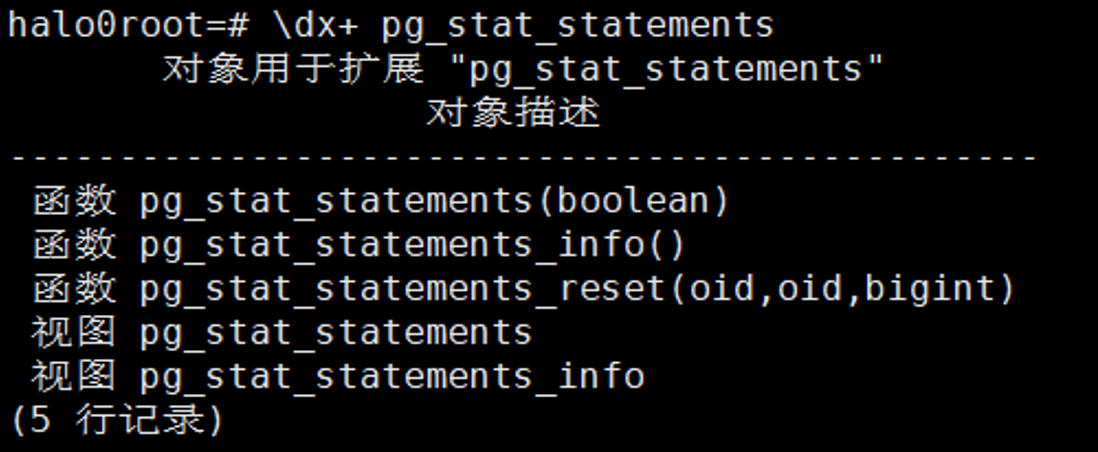
1.3 查看pg_stat_statements扩展对象
\dx+
pg_stat_statements
1.4 pg_stat_statements视图详情
pg_stat_statements的统计信息存储在一个与插件同名的pg_stat_statement视图中,可以通过查询该视图来获取各种SQL统计数据。以下是pg_stat_statements视图的属性字段名称以及字段说明:
|
列名 |
类型 |
说明 |
|
userid |
oid (参考 pg_authid.oid) |
执行SQL语句的用户ID |
|
dbid |
oid (参考
pg_database.oid) |
执行SQL语句的数据库ID |
|
toplevel |
bool |
如果查询作为顶层语句执行则为true(如果
pg_stat_statements.track 设置为 top,则始终为true) |
|
queryid |
bigint |
标识相同归一化查询的哈希码 |
|
query |
text |
代表性语句的文本 |
|
plans |
bigint |
语句被规划的次数(如果启用了 pg_stat_statements.track_planning,否则为0) |
|
total_plan_time |
double precision |
语句规划总耗时,以毫秒为单位(如果启用了
pg_stat_statements.track_planning,否则为0) |
|
min_plan_time |
double precision |
语句规划的最短时间,以毫秒为单位(如果启用了
pg_stat_statements.track_planning,否则为0) |
|
max_plan_time |
double precision |
语句规划的最长时间,以毫秒为单位(如果启用了
pg_stat_statements.track_planning,否则为0) |
|
mean_plan_time |
double precision |
语句规划的平均时间,以毫秒为单位(如果启用了
pg_stat_statements.track_planning,否则为0) |
|
stddev_plan_time |
double precision |
语句规划时间的总体标准差,以毫秒为单位(如果启用了 pg_stat_statements.track_planning,否则为0) |
|
calls |
bigint |
语句被执行的次数 |
|
total_exec_time |
语句执行的总时间,以毫秒为单位 |
|
|
min_exec_time |
double precision |
语句执行的最短时间,以毫秒为单位 |
|
max_exec_time |
double precision |
语句执行的最长时间,以毫秒为单位 |
|
mean_exec_time |
double precision |
语句执行的平均时间,以毫秒为单位 |
|
stddev_exec_time |
double precision |
语句执行时间的总体标准差,以毫秒为单位 |
|
rows |
bigint |
语句检索或影响的总行数 |
|
shared_blks_hit |
bigint |
语句命中的共享块缓存总数 |
|
shared_blks_read |
bigint |
语句从磁盘读取到共享缓冲区的块数 |
|
shared_blks_dirtied |
bigint |
语句执行期间脏化的共享块数 |
|
shared_blks_written |
bigint |
语句执行期间写回磁盘的共享块数 |
|
local_blks_hit |
bigint |
语句命中的本地块缓存总数(仅适用于临时表) |
|
local_blks_read |
bigint |
语句从磁盘读取到本地缓冲区的块数(仅适用于临时表) |
|
local_blks_dirtied |
bigint |
语句执行期间脏化的本地块数(仅适用于临时表) |
|
local_blks_written |
bigint |
语句执行期间写回磁盘的本地块数(仅适用于临时表) |
|
temp_blks_read |
bigint |
语句执行期间从临时文件中读取的块数 |
|
temp_blks_written |
bigint |
语句执行期间写入临时文件的块数 |
|
blk_read_time |
double precision |
语句在读取数据文件块上花费的总时间,以毫秒为单位(如果启用了
track_io_timing,否则为0) |
|
blk_write_time |
double precision |
语句在写入数据文件块上花费的总时间,以毫秒为单位(如果启用了
track_io_timing,否则为0) |
|
temp_blk_read_time |
double precision |
语句在读取临时文件块上花费的总时间,以毫秒为单位(如果启用了
track_io_timing,否则为0) |
|
temp_blk_write_time |
double precision |
语句在写入临时文件块上花费的总时间,以毫秒为单位(如果启用了
track_io_timing,否则为0) |
|
wal_records |
bigint |
语句生成的WAL记录总数 |
|
wal_fpi |
bigint |
语句生成的WAL全页图像总数 |
|
wal_bytes |
numeric |
语句生成的WAL总量,以字节为单位 |
2、装载测试数据并压测
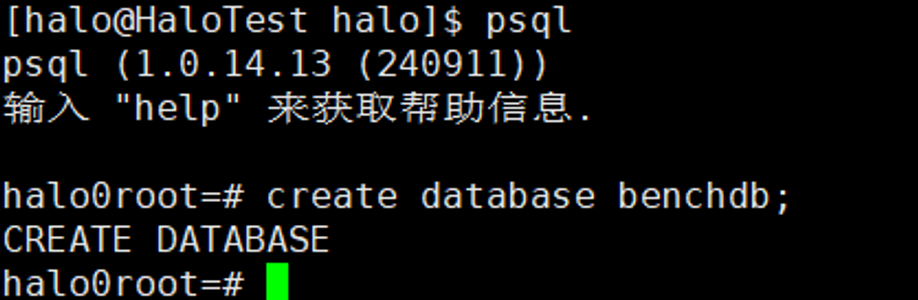
2.1数据库创建
create
database benchdb;
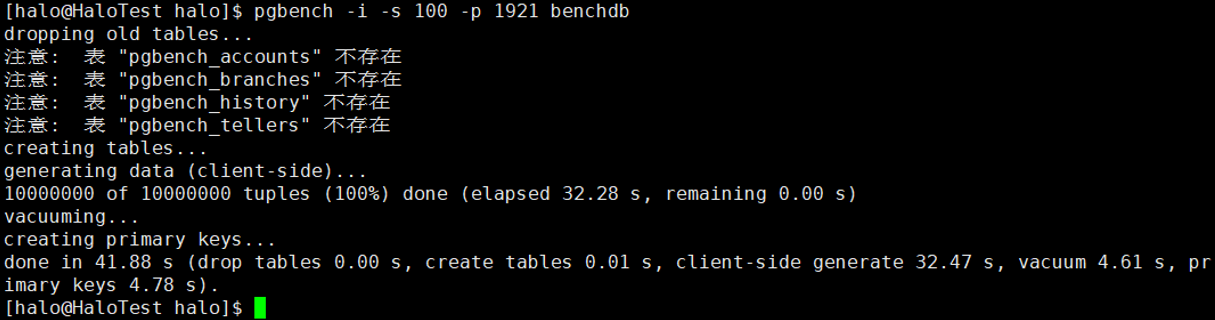
2.2 初始化100仓
pgbench
-i -s 100 -p 1921 benchdb
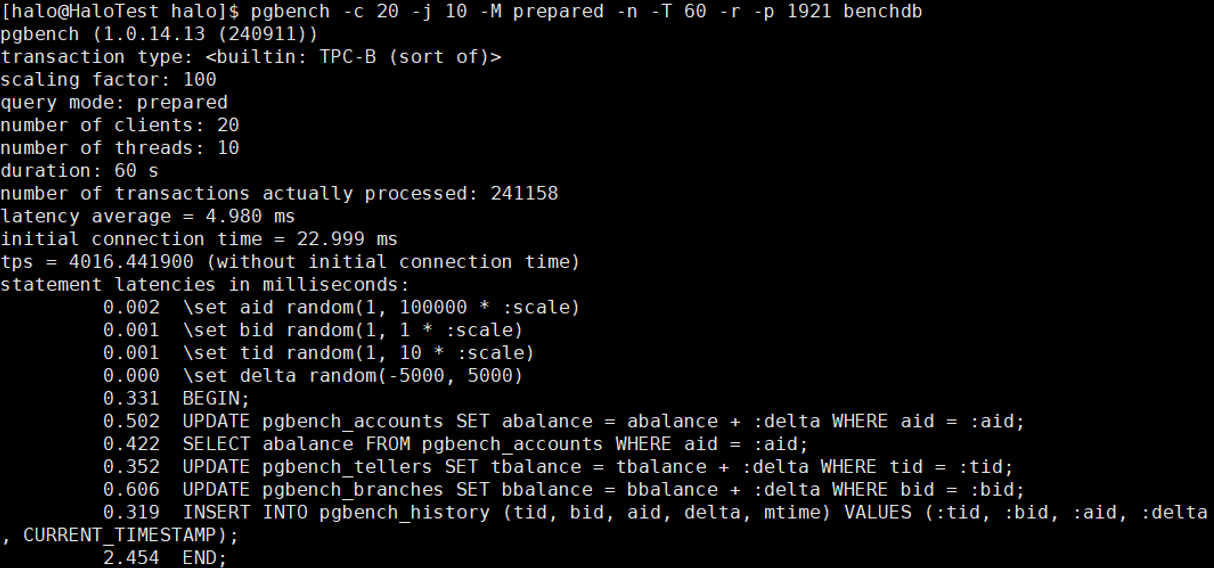
2.3 压测20连接,prepared 查询协议,运行 60s
pgbench
-c 20 -j 10 -M prepared -n -T 60 -r -p 1921 benchdb
3、找出最耗资源的SQL语句
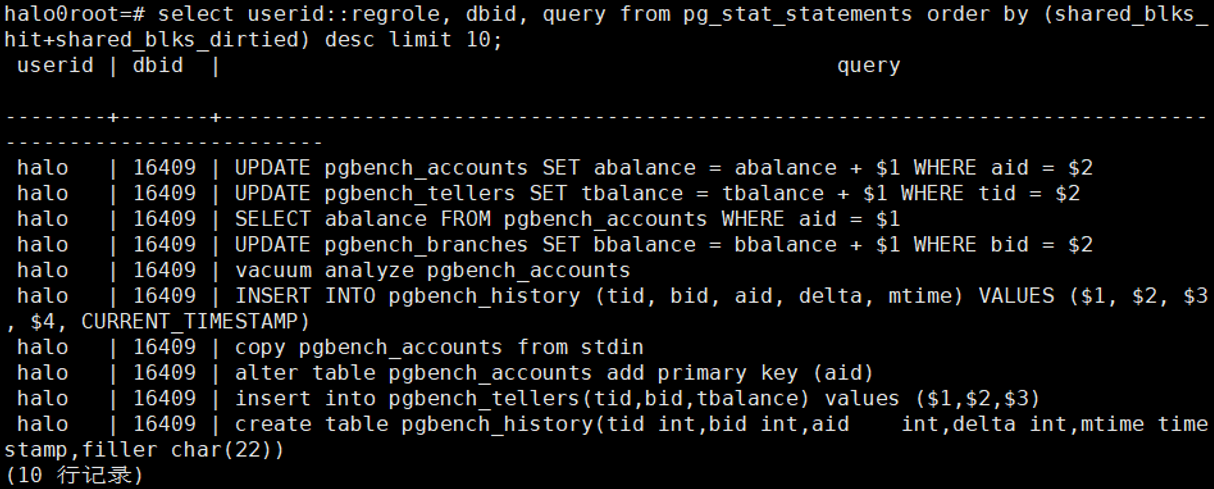
3.1 找出最耗内存的10条SQL
select userid::regrole, dbid, query from pg_stat_statements order
by (shared_blks_hit+shared_blks_dirtied) desc limit 10;
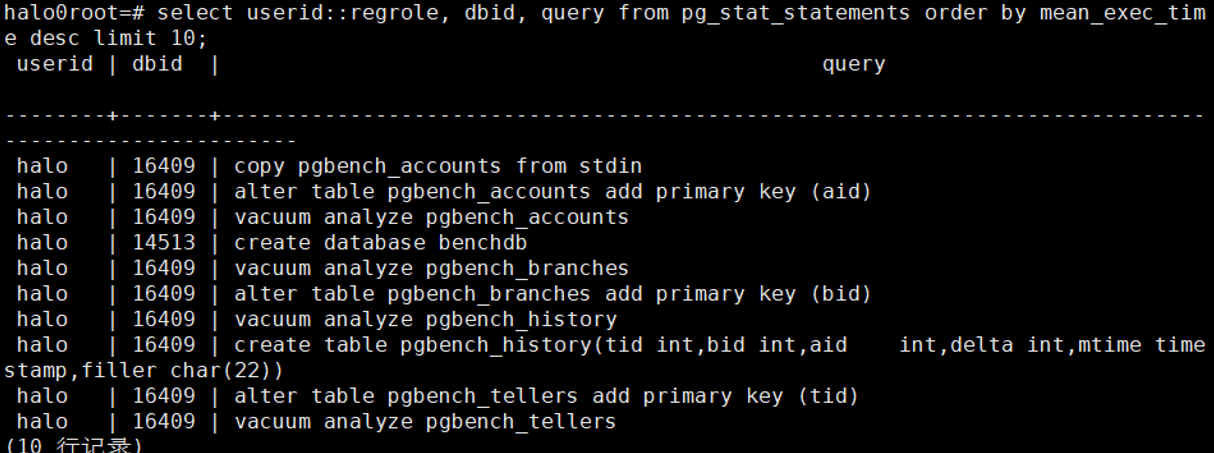
3.2 找出最耗CPU的10条SQL
select userid::regrole, dbid, query from
pg_stat_statements order by mean_exec_time desc limit 10;
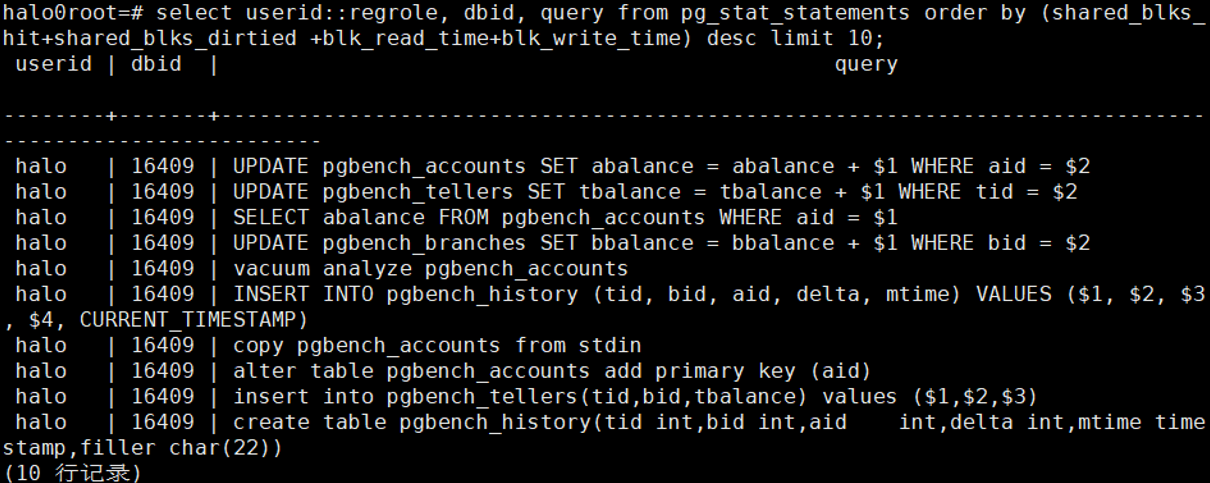
3.3 找出最耗SWAP的10条SQL
select
userid::regrole, dbid, query from pg_stat_statements order by
(shared_blks_hit+shared_blks_dirtied +blk_read_time+blk_write_time) desc limit
10;
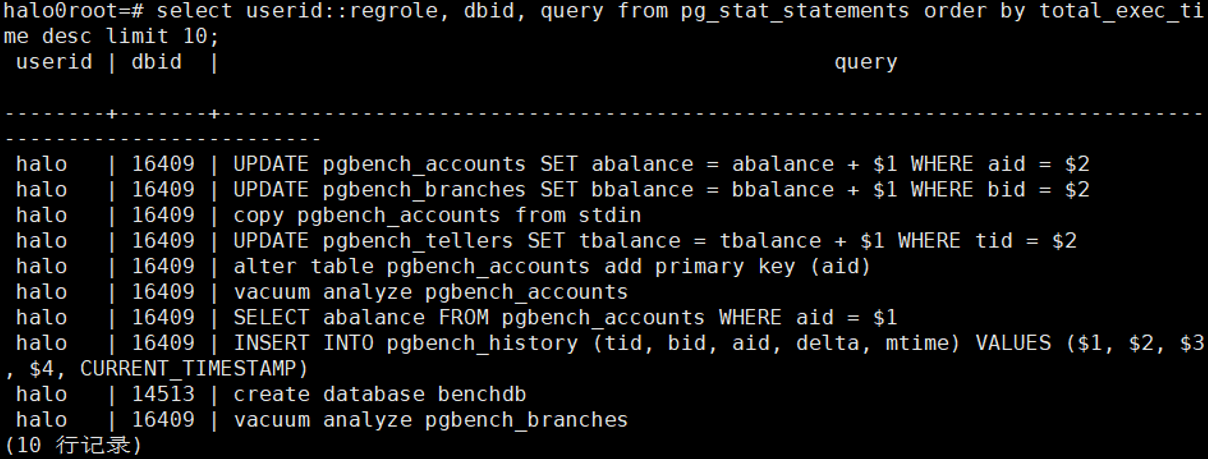
3.4找出总耗时的10条SQL
select
userid::regrole, dbid, query from pg_stat_statements order by total_exec_time
desc limit 10;
3.5找出总最耗IO的10条SQL
SELECT
userid::regrole, dbid, query FROM pg_stat_statements ORDER BY
(blk_read_time+blk_write_time) DESC LIMIT 10;
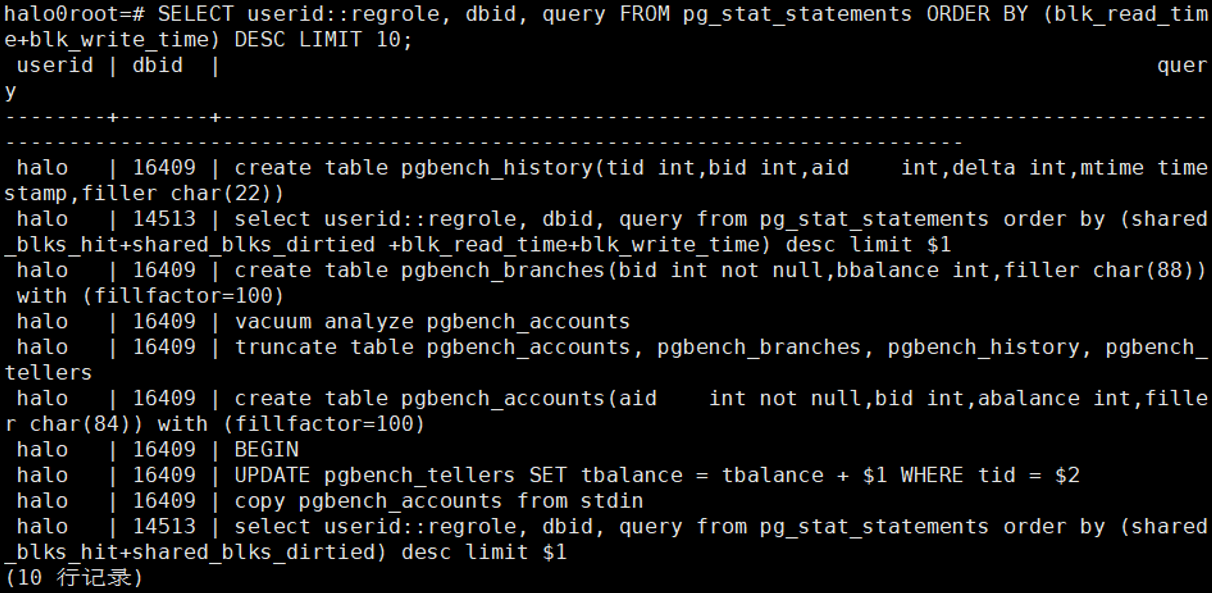
3.6 响应时间抖动最严重的10条SQL
select
userid::regrole, dbid, query from pg_stat_statements order by stddev_exec_time
desc limit 10;
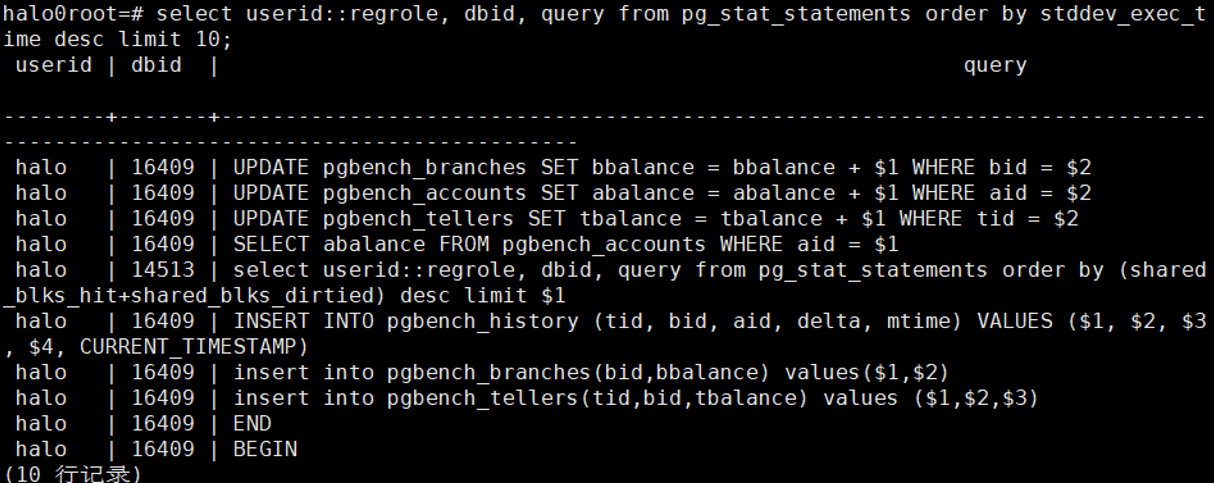
3.7 找出单次最耗时的10条SQL
select
userid::regrole, dbid, query from pg_stat_statements order by mean_exec_time
desc limit 10;
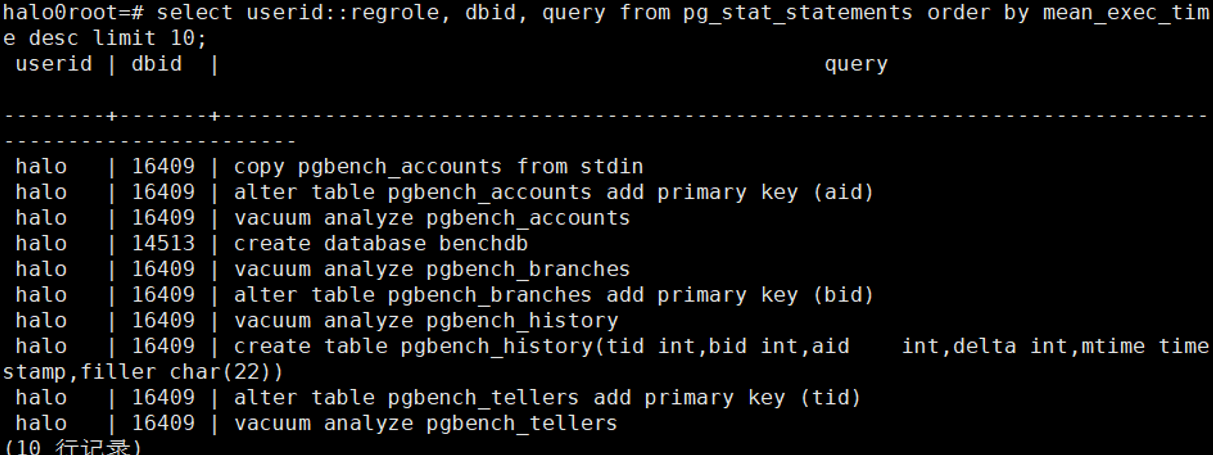
3.8 找出最耗临时空间的10条SQL
select
userid::regrole, dbid, query from pg_stat_statements order by temp_blks_written
desc limit 10;
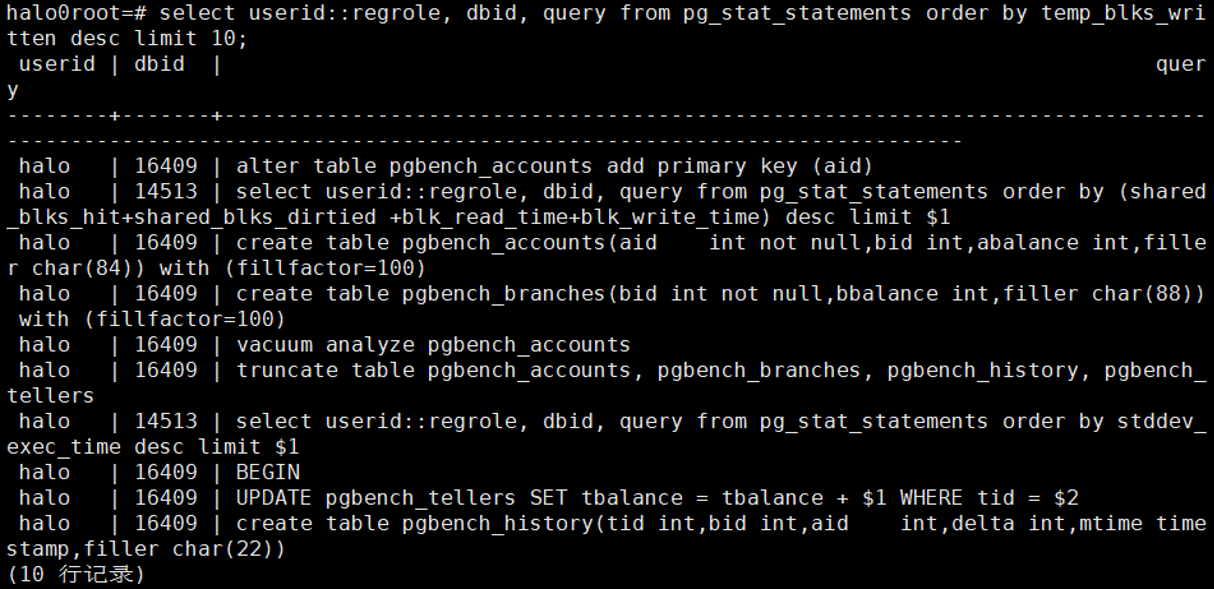
3.9 找出最耗共享内存的10条SQL
select
userid::regrole, dbid, query from pg_stat_statements order by
(shared_blks_hit+shared_blks_dirtied) desc limit 10;
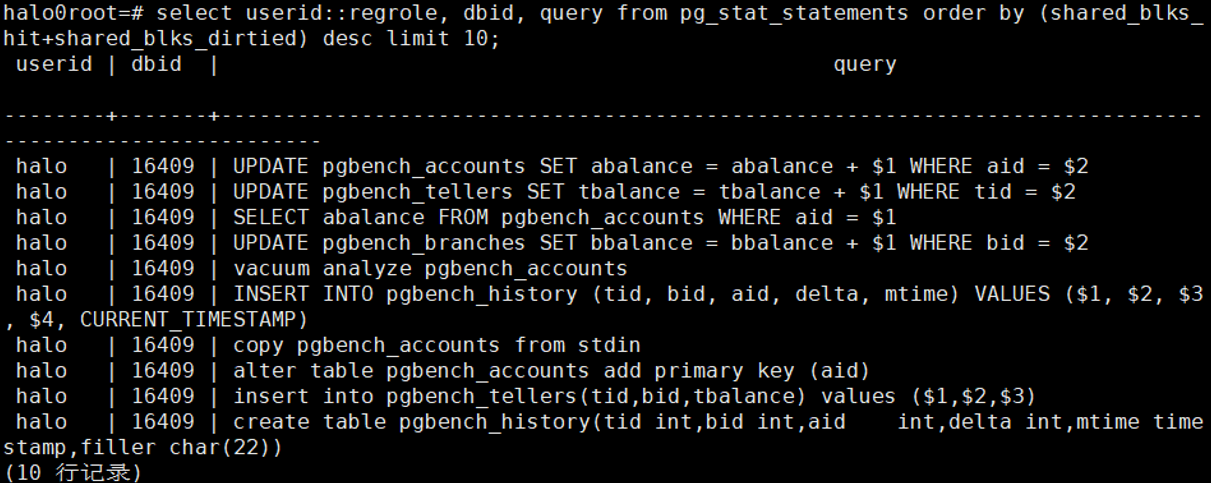
3.10 找出总最耗IO的10条SQL
select
userid::regrole, dbid, query from pg_stat_statements order by
(blk_read_time+blk_write_time) desc limit 10;
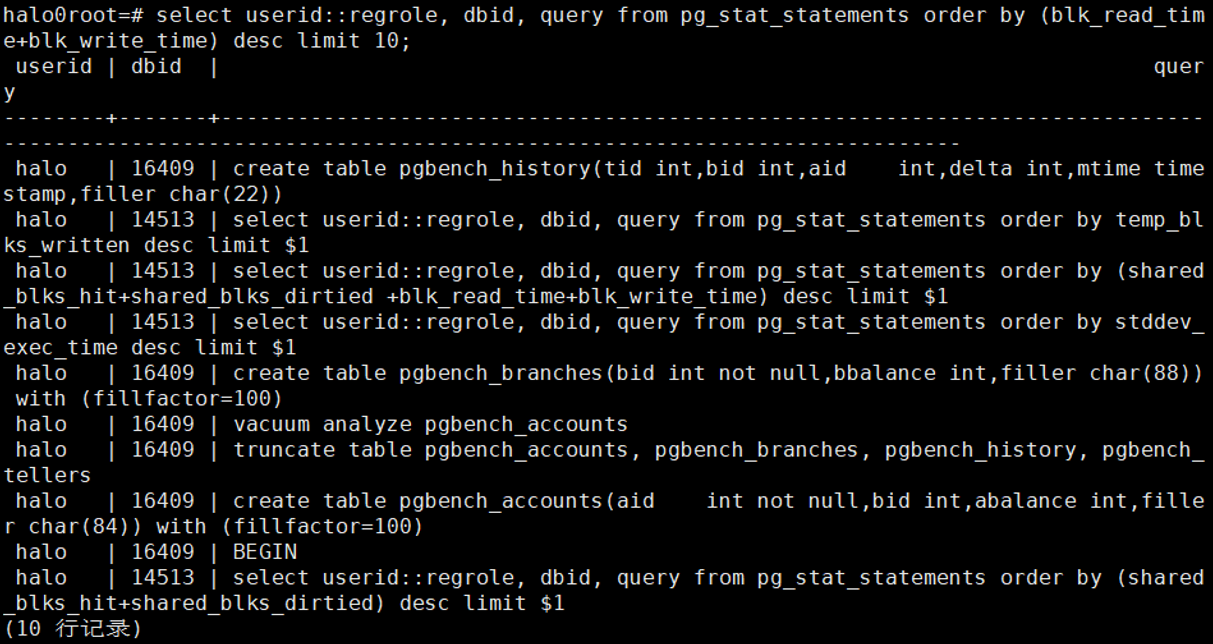
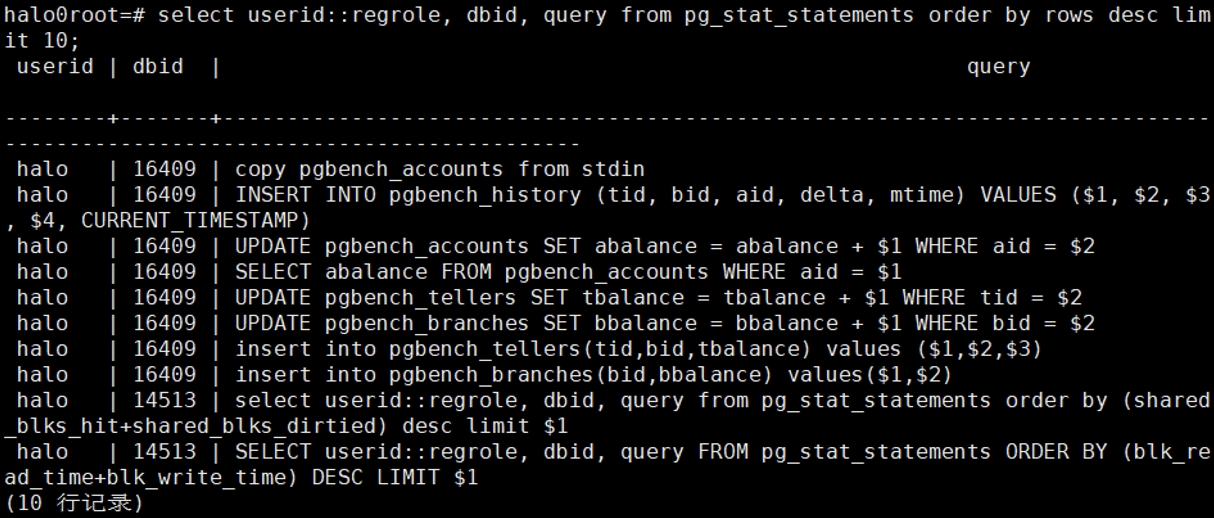
3.11影响行数最多的10条SQL
select
userid::regrole, dbid, query from pg_stat_statements order by rows desc limit 10;
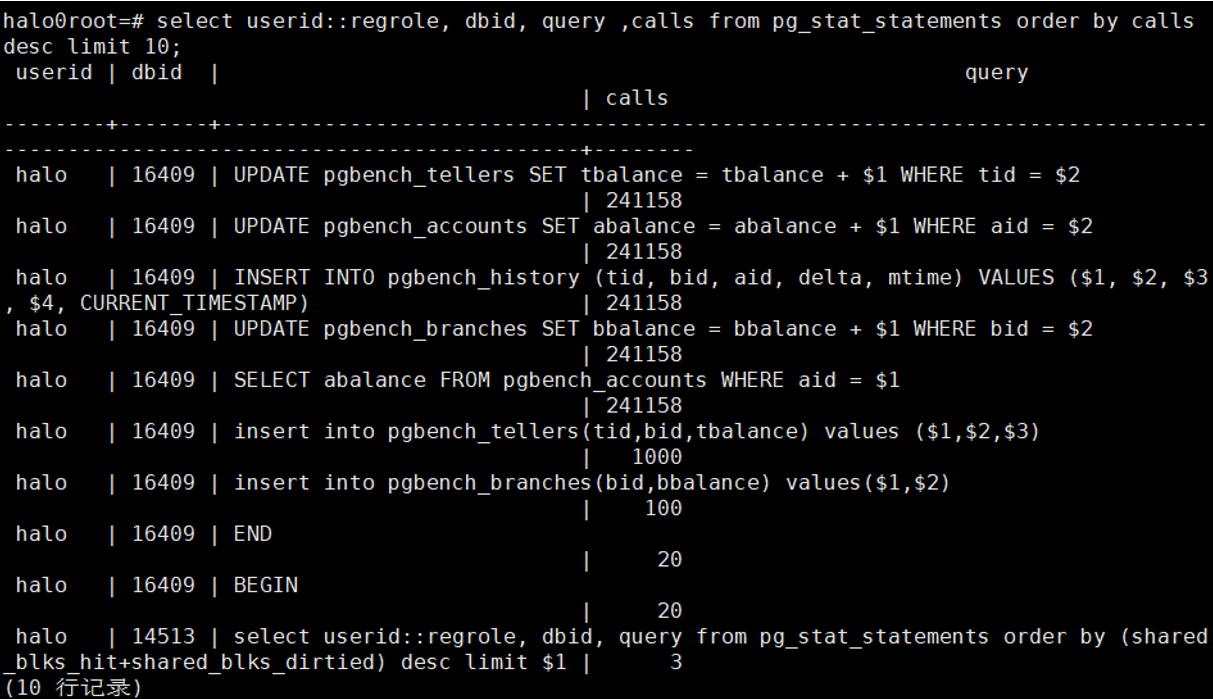
3.12调用次数最多的10条SQL
select
userid::regrole, dbid, query ,calls from pg_stat_statements order by calls desc
limit 10;
最后
本篇介绍了pg_stat_statements扩展的HaloDB中的详细使用方法,找出最耗资源的SQL语句后就可以进行有针对性的优化了。各位朋友们如有感兴趣的知识,也欢迎私聊我沟通。
