




点击上方【蓝色】字体 关注我们


01 场景描述
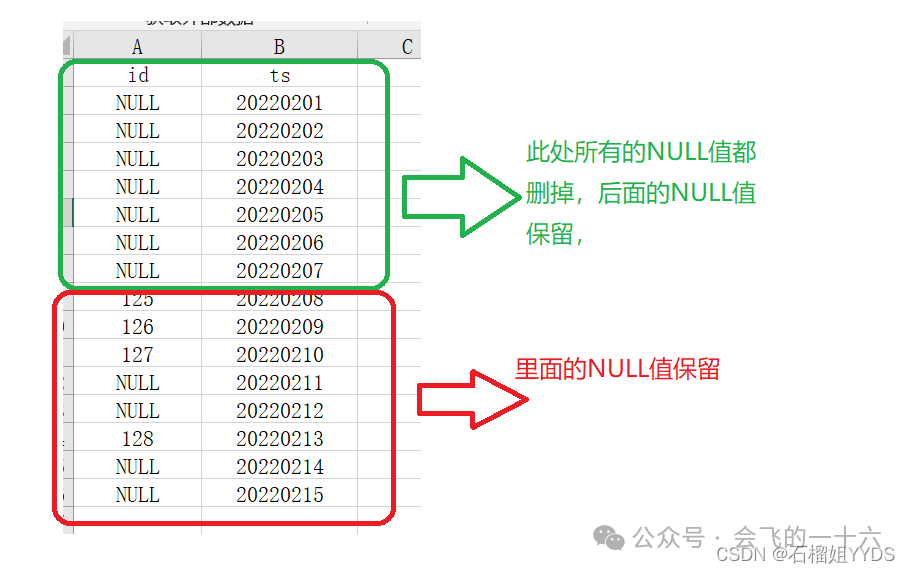
如何删除第2次、第3次连续出现NULL值得所有行?
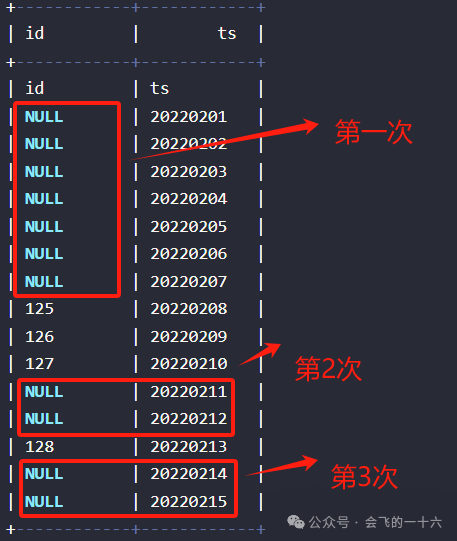
02 数据准备
create table null_del as(select stack(15,NULL, 20220201,NULL, 20220202,NULL, 20220203,NULL, 20220204,NULL, 20220205,NULL, 20220206,NULL, 20220207,125, 20220208,126, 20220209,127, 20220210,NULL, 20220211,NULL, 20220212,128, 20220213,NULL, 20220214,NULL, 20220215) as (id, dt))
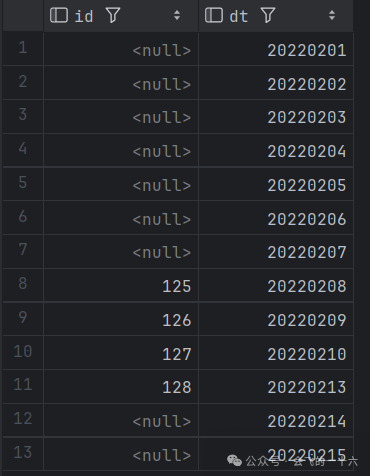
+------------+------------+| id | ts |+------------+------------+| id | ts || NULL | 20220201 || NULL | 20220202 || NULL | 20220203 || NULL | 20220204 || NULL | 20220205 || NULL | 20220206 || NULL | 20220207 || 125 | 20220208 || 126 | 20220209 || 127 | 20220210 || NULL | 20220211 || NULL | 20220212 || 128 | 20220213 || NULL | 20220214 || NULL | 20220215 |+------------+------------+

03 问题分析
问题分析:如果直接使用id is not null,则会将整个NULL值所在的行都删除掉,本题要求保留第一次出现不为NULL值的以下所有存在NULL值的行,也就是只删除id从表中第一行开始出现NULL到第一次出现非NULL之间的所有行,此时我们可以借助于窗口函数进行辅助计算。
第一步:利用last_value()函数ignore nulls特性构造删除标记
select id,dt,last_value(id, true) over (order by dt) del_flgfrom null_del
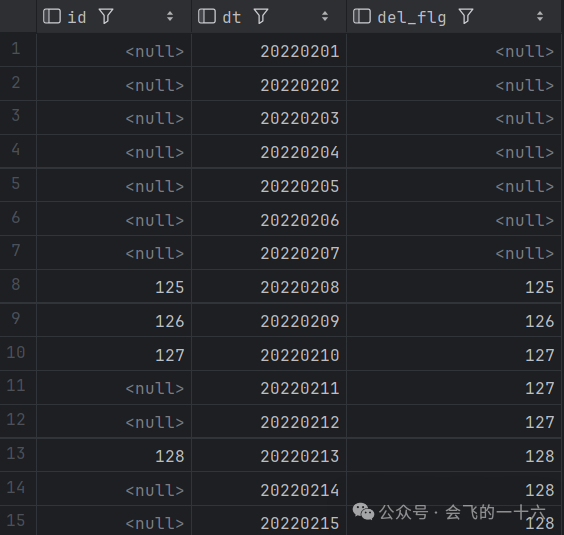
使用max(id) over(order by dt) 也可以达到相同的效果
select id,dt,--last_value(id, true) over (order by dt) del_flgmax(id) over (order by dt) del_flgfrom null_del
使用count(id) over(order by dt)也可以进行删除
select id,dt,--last_value(id, true) over (order by dt) del_flg--max(id) over (order by dt) del_flgcount(id) over (order by dt) del_flgfrom null_del
完整的SQL如下:
select id, dtfrom (select id,dt,last_value(id, true) over (order by dt) del_flgfrom null_del) twhere del_flg is not null
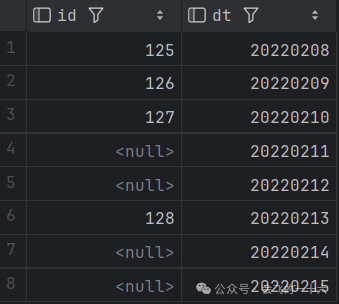
问题拓展:如何删除第2次、第3次、第N次连续出现NULL值所在的行?
select id,dt,--last_value(id, true) over (order by dt) del_flg--max(id) over (order by dt) del_flgcount(id) over (order by dt) del_flgfrom null_del
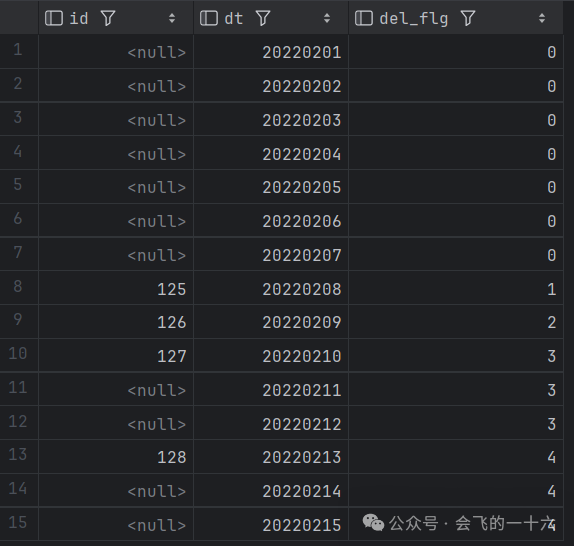
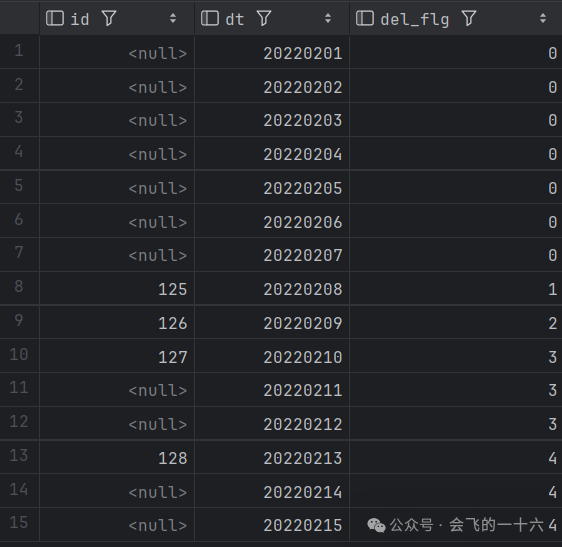
按照null值分组,使用dense_rank()进行等位排名(注意此处不能使用row_number()因为有重复值)
select id,dt,dense_rank() over (partition by id order by del_flg) rnfrom (select id,dt,count(id) over (order by dt) del_flgfrom null_del) t
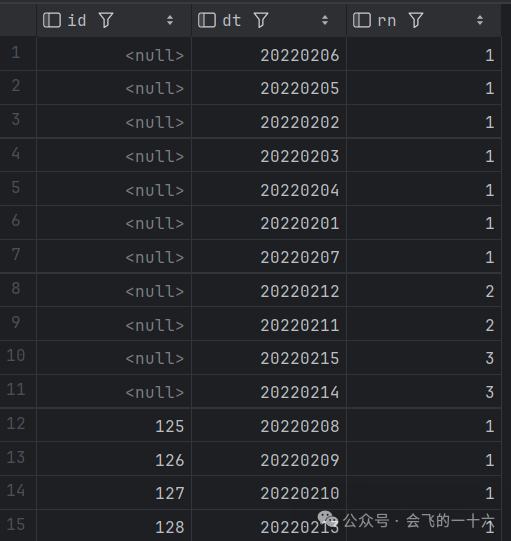
可以看出结果中id非NULL的分组中也进行了顺序编号,此时我们只需要将结果中id非NULL值的rn置为NULL即可。具体SQL如下:
select id,dt,case when id is null then dense_rank() over (partition by id order by del_flg) end rnfrom (select id,dt,count(id) over (order by dt) del_flgfrom null_del) t
注意:这样写一定要记住执行顺序,先执行窗口函数,再执行case when 语句
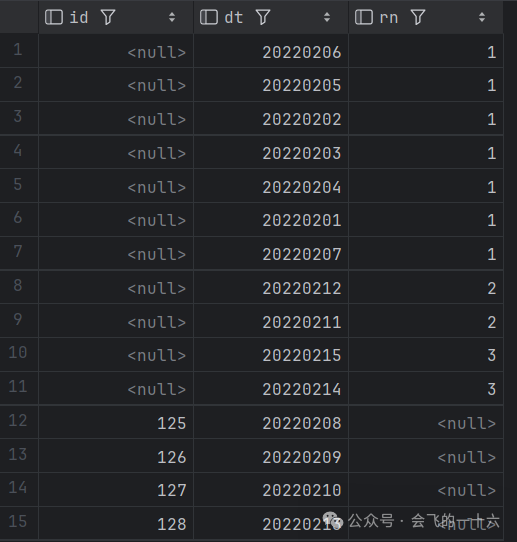
最终完整的SQL如下:
select id,dtfrom(select id,dt,case when id is null then dense_rank() over (partition by id order by del_flg) end rnfrom (select id,dt,count(id) over (order by dt) del_flgfrom null_del) t) twhere nvl(rn,-1) != 2order by dt;
由于rn中存在NULL值,所以此处在过滤时注意NULL值转换,否在会连rn 中 NULL值一起过滤掉。
04 小 结
本文基于SQL语言给出了一种删除第N次连续出现NULL值所存在行的通用解决方案,当然删除的不一定是NULL值,也可以是其他X值,其解决思路类似,本质上是断点分组思想的应用,在sql复杂场景中,往往利用该思想处理一些持续性、连续性、或在某一时刻点发生转折(变化)的问题,采用该方法可以提高处理问题的可扩展性和通用性,逻辑性更强,看待问题的观点更高一层。
往期精彩

会飞的一十六
扫描右侧二维码关注我们
点个【在看】 你最好看

文章转载自会飞的一十六,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
