





论文链接: https://arxiv.org/pdf/2410.08815
代码链接: https://github.com/Li-Z-Q/StructRAG
摘要
方法
框架
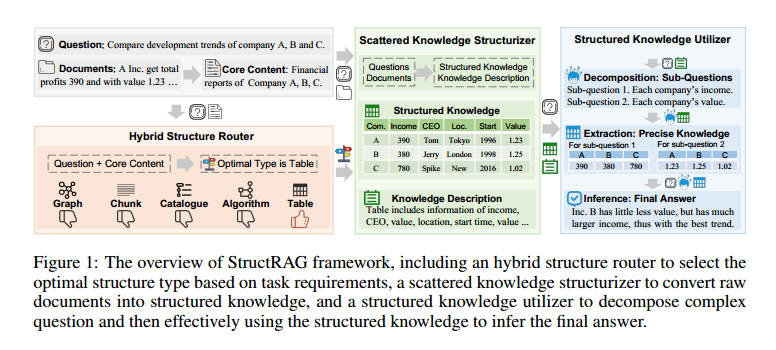
以下是StructRAG框架其主要组成部分及功能的详细说明:
1. 混合结构路由器(Hybrid Structure Router)
功能:该路由器负责根据输入问题(q)和文档的核心内容(C)选择最合适的知识结构类型(t),如表格、图形、算法、目录或文本块。
流程:通过分析任务要求,路由器识别不同结构类型的适用性,生成最佳结构类型(t)。这一过程是基于对相关文档核心内容的理解,使得后续的知识提取更加高效。
训练方法:使用基于 DPO(Direct Preference Optimization)的方法进行训练,确保路由器在知识类型选择上表现优异。
2. 分散知识结构化器(Scattered Knowledge Structurizer)
功能:在识别到最适合的结构类型(t)后,该模块提取原始文档中分散的知识并重构为结构化的知识()和知识描述()。 流程:利用 LLM 的强大理解和生成能力,将每个原始文档转换为选定结构类型的结构化知识。例如,表格通过 markdown 表示,图通过头-关系-尾三元组列表表示,块通过常规文本表示,算法通过伪代码表示,目录通过带有分层编号(例如,第一节,1.1,1.1.2)作为明确章节标识符的文本表示。然后将生成的结构化知识()和描述()汇总成整体知识结构()和结构化知识的总体描述(),为后续推理提供基础。
3. 结构化知识利用器(Structured Knowledge Utilizer)
功能:该模块负责将获得的结构化知识用于回答问题,通过分解复杂问题来提高推理的准确性。 流程: 问题分解(Decomposition: Sub-Questions):将原始问题(q)和结构化知识的描述()作为输入,将问题分解为多个简单的子问题()。 知识提取(Extraction: Precise Knowledge):从整体结构化知识()中提取每个子问题所需的精确知识()。 最终推理(Inference: Final Answer):整合所有子问题及其提取的知识,生成最终答案(a)。
混合结构路由器训练
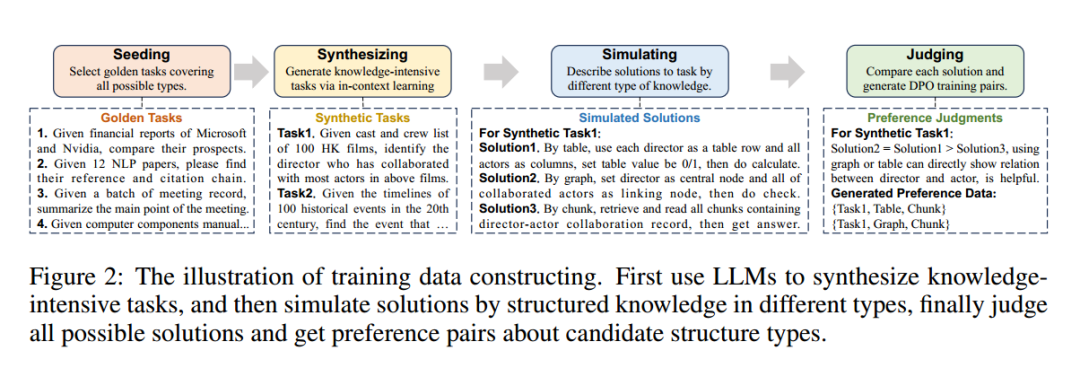
种子任务收集(Seeding): 首先,手动收集若干种子任务,这些任务覆盖可能的结构类型(如表格、图形等)。
合成新任务(Synthesizing): 利用 LLM 的上下文学习能力,基于这些种子任务合成一组新任务。每个合成任务包含一个问题及其对应文档的核心内容。
模拟解决方案(Simulating): 对于每个合成任务,使用 LLM 模拟不同类型结构化知识下的解决过程,从而生成多种模拟解决方案。
偏好判断(Judging): 最后,利用 LLM 对这些模拟解决方案进行比较,生成关于结构类型的偏好对。
总结
StructRAG 的创新之处在于其混合信息结构化机制,通过结构化知识高效整合分散信息,为每个任务量身定制最佳知识结构类型,有效地解决了知识密集型推理任务中常见的信息分散和噪音问题。与传统的 RAG 方法相比,StructRAG 显著提高了在复杂问题上的推理能力。

