




今天分享的是季逸超 (Yichao 'Peak' Ji) 的个人兴趣项目Steiner。自Openai o1发布,作者开始复现o1的技术路线,目前已经更新两篇阶段性技术分享。第一篇文章(https://zhuanlan.zhihu.com/p/720575010)以Qwen2 7B作为base model,用 8 张 A100 80GB 在 4096 的长度上训练得到 Peak-Reasoning-7B-preview。而本次,作者更新了其工作。公开了在Qwen2 32B的成果并分享一些经验。

背景
这篇文章的背景是对比传统的大规模语言模型(LLMs)与OpenAI发布的o1模型之间的差异,特别是关注于推理阶段的变化。传统的大规模语言模型通常在一个固定的上下文中生成文本,而OpenAI的o1模型引入了一个重要的新特性——推理令牌(reasoning tokens),这一特性允许模型在推理过程(thought)中分配更多的计算资源,从而提高模型的表现。
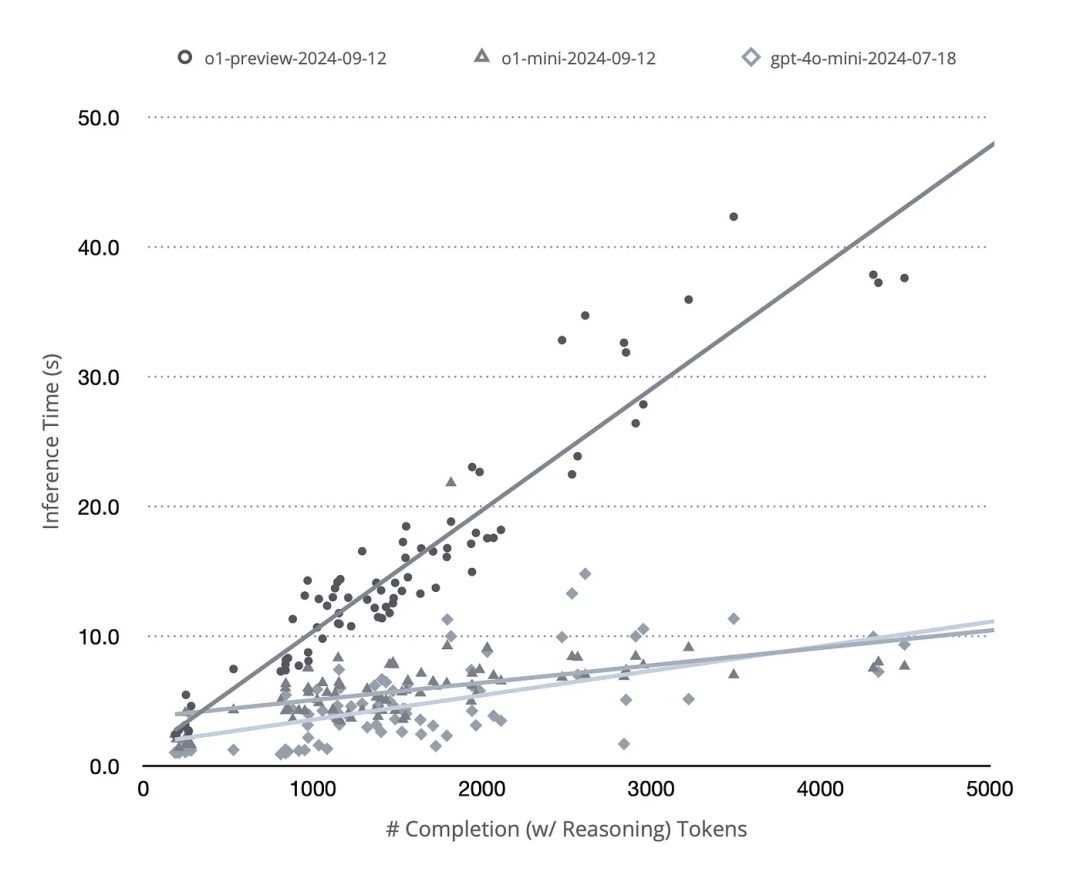
作者在技术报告中提到,在实现推理时间缩放(inference-time scaling)时,最直观的方法可能是引入树搜索或者代理框架(agentic framework)。然而,根据对o1有限的官方信息的研究,大部分基准测试都是基于pass@1和多数投票(majority voting)来进行的。同时,OpenAI团队指出o1实际上是一个单一模型,而不是一个系统。尽管推理令牌的具体内容尚未通过OpenAI的API向开发者公开,但Token的使用统计信息中包含了推理Token的数量(因为这关系到开发者的计费)。基于此,作者设计了一个简单的实验,通过调用o1的API来分析完成Token(包括推理Token)的数量与总请求时间之间的关系。如果使用了树搜索,则推理应尽可能并行,以缓存并最大化GPU利用率,这将导致次线性曲线。然而,实验结果呈现出一系列清晰的线性关系,其中o1-mini模型的表现甚至比GPT-4o-mini更为稳定。所以o1的推理过程,很有可能不是基于树结构并行推理得到的。o1可能仍是一个进行线性自回归解码的模型。也就是说,模型推理过程中自回归解码得到一条包含回溯、反思的推理路径。
主要方法
数据合成
为了得到具备线性推理能力且路径包含回溯、反思等能力。数据合成的方法必须进行改造。传统的CoT方式,通过将问题和答案同时给到模型,让模型拆解问题,并生成每一步的思考结果。因为这本身对于模型来说是一场“开卷考试”。模型在生成推理路径时是知道正确答案的,那么生成的路径虽然形式上包含反思、回溯等节点。但其这个过程并不一定有效,于是作者采用两种方法增强数据集。
这种方法的核心思想是通过人为制造不完整的推理路径,迫使模型去尝试补全缺失的部分,并在给出正确答案后形成回溯的实例。具体做法如下:
随机截断:首先,作者会对现有的推理路径进行随机截断,这意味着在某个点上,推理链条会被打断,从而产生一个不完整的推理路径。隐藏正确答案:在截断后,正确的答案会被暂时隐藏起来,此时模型并不知道完整的推理路径是什么样的。向前推理:让一个强大的语言模型基于这个被截断的前缀,尝试向前推理若干步。这一步骤模拟的是模型试图继续解决问题的过程。提供正确答案:最后,当模型尝试了一定步数后,再提供正确的答案,这样就可以获得那些需要回溯才能纠正的推理路径例子。
考虑到训练成本的问题,作者选择了那些推理Token数量低于4,096,并且提示(prompt)、推理(reasoning)和完成(completion)Token总数低于8,192的样本用于训练。这意味着,最终用于训练的数据集包含了那些既不过于简单也不过于复杂的推理路径示例,以确保模型能够在合理范围内学习到丰富的推理模式,同时又不至于因计算成本过高而难以训练。
训练过程
训练过程分为三个阶段,分别是持续预训练(Continual Pre-Training, CPT)、监督微调(Supervised Fine-Tuning, SFT)以及带有步骤级别奖励的强化学习(Reinforcement Learning with Step-Level Reward, RL)。
持续预训练(CPT):在这个阶段,模型会在普通文本语料库和推理路径的混合数据上进行训练。目的是让模型熟悉长推理输出,并初步训练新引入的14个特殊标记的嵌入层。尽管小参数模型的测试表明直接在SFT阶段使用大量推理数据也可以获得良好的表示,但由于32B的CPT已经提前完成,所以作者还是继续使用了经过CPT阶段训练的模型。
监督微调(SFT):在此阶段,使用聊天模板进行训练,目的是教会模型模仿推理格式:首先为每一步命名,然后输出完整的想法,接着总结想法,反思至今的推理过程,最后决定是否继续、回溯还是结束推理并正式回答问题。虽然开源模型不需要隐藏其推理过程,但生成类似o1那样的总结是为了未来支持多轮对话的Steiner模型做准备。理论上,训练完成后,可以替换之前的完整想法为总结,以减少前缀缓存未命中时的预填充开销。然而,目前Steiner还未针对多轮对话进行优化,仅保留总结可能会导致负面的少量样本学习效应。
带有步骤级别奖励的强化学习(RL):经过前两个阶段后,模型已经学会了生成和完成推理路径,但它还不知道哪些选择是正确和高效的。如果盲目奖励较短的推理路径,模型可能会退化为学习捷径,即内化思维链(CoT)。为此,设计了一个启发式的奖励机制:根据DAG中每个节点的入度( e_i ),出度( e_o ),离原问题的距离( d_s ),以及离正确答案的距离( d_e )来加权每个步骤和整个推理路径的奖励。这种方法指导模型学会如何平衡探索的广度和深度。
通过这三个阶段的训练,模型不仅能够生成推理路径,还能在推理过程中做出更合理的选择,避免单纯依赖捷径学习,从而提高其在解决复杂问题时的灵活性和有效性。
实验结论
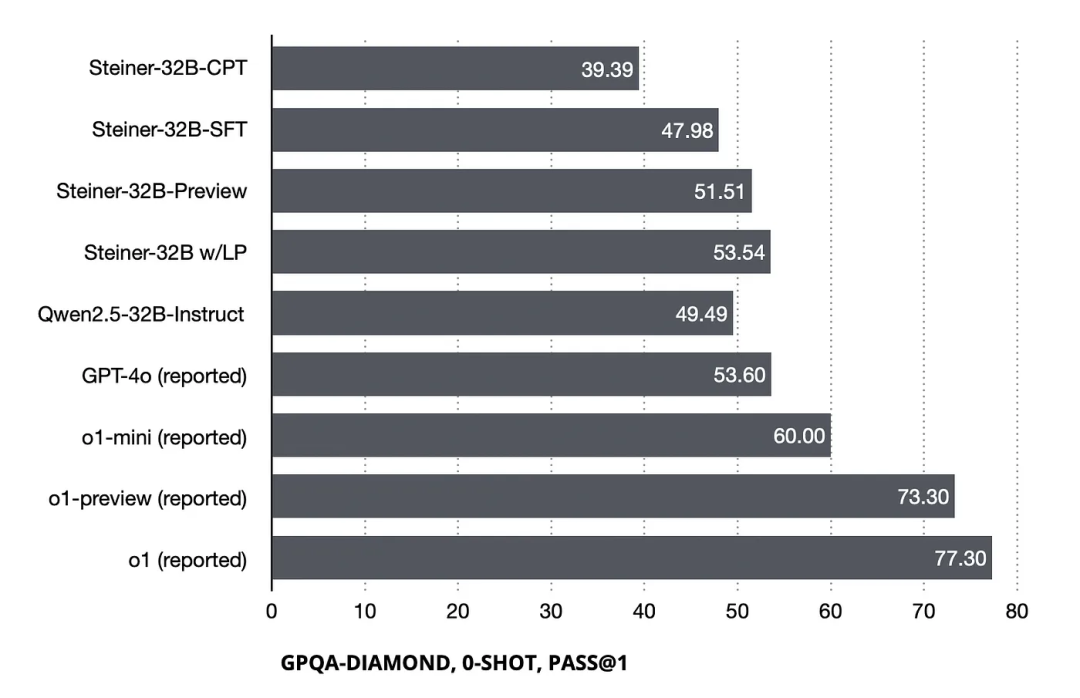

GPQA-Diamond 数据集上的表现:Steiner 模型在引入强化学习(RL)阶段后,在GPQA-Diamond数据集上的性能提升了+3.53。结合使用约束推理步骤数量的logits处理器,最佳配置可以带来+5.56的性能提升。
其他数据集上的表现:Steiner 在诸如MMLU等数据集上与基线相比没有显著差异,这与OpenAI关于o1-mini在其博客中的观察相符,可能反映出32B模型在预训练阶段获取的世界知识的局限性。
推理时间缩放实验:使用logits处理器增加推理步骤数量后,Steiner在几乎所有测试基准上的表现没有提升,在某些情况下甚至有所下降。根据作者提供的代码片段(https://gist.github.com/peakji/f81c032b6c24b358054ed763c426a46f), logits_processor
是一个用于推理时间缩放实验的逻辑处理器,其主要功能是对模型在生成推理步骤时的logits值进行调整,以确保推理步骤的数量落在指定的范围内。主要包含以下步骤:初始化推理:当 token_ids
为空时(即推理刚开始时),处理器会将所有logits值设置为一个极小的负数(-9999.999),并把表示推理开始的特殊标记<|reasoning_start|>
(其ID为151665)的logits值设置为一个极大的正数(9999.999)。这样做的目的是确保推理的第一步总是从启动推理标记开始。控制推理步骤数量:当最新的 token_ids
值为推理步骤结束标记(ID为151670)时,处理器会计算已完成的推理步骤数量(通过计数推理步骤结束标记的数量)。然后根据指定的最小和最大推理步骤范围来调整logits。如果已达到或超过最大推理步骤数(n >= max_steps
),则将结束推理标记(ID为151666)的logits值设为极大值,以确保推理结束。如果推理步骤数少于最小限制(n < min_steps
),则将继续推理(ID为151667)和回溯(ID为151668)标记的logits值恢复,鼓励模型继续推理或回溯。否则,根据实际情况,恢复继续推理、结束推理或回溯标记的logits值,给予模型选择的机会。强制启动新的推理步骤:如果最新的 token_ids
值为继续推理或回溯标记之一(ID分别为151667和151668),则处理器会将所有logits值设为极小的负数,并将启动新的推理步骤标记(ID为151669)的logits值设为极大值,确保在决定继续或回溯后,会开始一个新的推理步骤。
目前的缺陷
推理长度与性能的关系:增加推理步骤并没有带来性能上的提升,反而在某些情况下导致了性能下降。这表明当前模型在处理长推理输出时可能存在不足,或者强化学习阶段的设计未能帮助模型在推理的广度和深度之间找到合适的平衡。
多轮对话的支持:当前Steiner的训练后数据不包含多轮对话的例子。基于Qwen2.5–32B的Steiner模型最佳版本缺乏处理多轮对话的能力。虽然基于Qwen2.5–32B-Instruct的开源Steiner-preview模型兼容聊天格式,但仍不建议用于多轮对话。
定制系统提示和采样参数:类似于OpenAI的o1–2024–09–12,Steiner同样不推荐使用自定义系统提示或修改如温度等采样参数。这是因为Steiner还没有在多样化的系统提示上进行训练,改变其他参数可能导致推理Token格式上的错误。
语言构成:Steiner的训练后数据的语言构成大约为90%的英文和10%的中文,但在推理路径数据增强过程中几乎只使用了英文。因此,尽管模型的最终响应展示了某种程度的语言跟随能力,但推理Token主要以英文生成。
编者简介
李剑楠:华东师范大学硕士研究生,研究方向为向量检索。作为核心研发工程师参与向量数据库、RAG等产品的研发。代表公司参加DTCC、WAIM等会议进行主题分享。

