




摘要:
计算机指令就是指挥机器工作的指示和命令,程序就是一系列按一定顺序排列的指令,执行程序的过程就是计算机的工作过程。指令集,就是CPU中用来计算和控制计算机系统的一套指令的集合,每种新型的CPU在设计时就规定了一系列与其他硬件电路相配合的指令集
正文:
自己的工作和信创(信创即信息技术应用创新)工作相关,其中一部分工作涉及到信创操作系统。通常CPU芯片种类(鲲鹏、海光等多种采用不同指令集架构的 CPU )的不同,所对应的操作系统软件介质也不同。之前大家所熟知的操作系统linux基本均部署在x86类型的芯片下,但信创环境稍复杂些,通常还会涉及到arm类型的芯片。
这时候,大家通常碰到的第一个问题就是: 支持arm或X86的CPU芯片,1. 到底有啥区别?2. 各有什么优缺点?
回答这个问题前,遵循“第一性原理”,我们先来分析下什么是指令集。
计算机是一种高效的工具,首先让计算机如何理解人类的正确指令/命令?
计算机只认识电信号,而人们把低电平和高电平抽象成了0和1的数字——机器码。
在计算机的初期,人们就意识到:如果只有0和1的可供输入来代表高低电平,作为人类实在是太难写了,需要在旁边看着参照表输入。所以人们发明了汇编语言及其对应的汇编器(类似参照表),只要输入几个简单的字母,类似LDR(读),STR(写),ADD(加),汇编器就能把这些字符的电信号转换成机器码——也就是汇编语言到机器语言的过程。
但是汇编语言还是很麻烦:例如我要做一个加法,要先读取一个数值,再读取另一个数值,两个相加得出答案,把答案再写回去...
后来人们发明了高级语言,以上那么多的步骤可以直接简化为。只要把这个式子扔给对应的编译器,编译器就能把这些字符先转换成汇编语言,汇编器再转换成机器码(有些编译器支持直接转成机器码)。
每一次敲击键盘,其实都是在输入一次电信号——屏幕上显示的可读字符只是计算机通过“一系列的操作”,把电信号转换来提供给你看的,它们本质上还是各种高低电平。
编译器和汇编器的操作就是把这些对计算机无意义的电信号转换成对计算机有意义的电信号。
那怎样的电信号才是有意义的呢?
指令集就是那些有意义的电信号的合集,其中每个指令对应着一个电路——你给电路输入一些电信号,它就会返回一些电信号——意味着硬件电路是根据指令集来设计的。
指令集可以被分为两类:
复杂指令集CISC(Complex Instruction Set Computer)
精简指令集RISC(Reduced Instruction Set Computing)
CISC把能用上的电路都用上,一条指令就可以实现一个复杂的功能。例如用一个复杂的电路实现矩阵的乘法,只要给输入就能直接给输出。
RISC中的一条指令大多是“基本指令”,它是通过多条指令组合完成一个复杂的功能。同样是计算矩阵的乘法,它需要用到多个整数的加减乘的指令,通过一定的顺序执行得到输出。
一条指令由操作码和若干个地址码组成。

操作码告诉计算机要做什么:是去取/存一个数字,还是把两个数字相加、相减、相乘之类的计算动作。
地址码告诉计算机是对谁进行操作:你要取/存/算的那(几)个数字的地址是XXX…
指令可以根据操作码的长度、地址码数目、操作类型进行分类。
按照地址码的数目分类:
零地址指令:没有地址,适用于不需要操作数的指令,例如停机指令。
一地址指令:有一个地址,只对一个地址里的数字进行操作,例如对一个数字加一、取反、求补。
二地址指令:有两个地址,对两个地址里数字进行操作,例如两个数字相加、相减。
三地址指令:有三个地址,对前两个地址的数字进行操作,把他们两的计算结果放在第三个地址里。
四地址指令:有四个地址,它包含了和三地址一样的功能,第四个地址可以用来告诉计算机下一条将要执行指令的地址。
指令本身也是数据,它也是被存储在主存中的,所以想要执行一条指令就要知道这条指令的地址在哪。
CPU中有一个PC寄存器(Program Counter,程序计数器),它用来记录当前计算机所要执行的指令的地址。每当CPU从PC那拿了一条指令的地址,PC中的地址就会自动加“1”(这里的“1”指的是1个指令的宽度,而并非数值1),跳转到下一个指令的地址,而此时CPU是拿着PC刚刚所给的地址获取指令。
自动加“1”便是顺序寻址。
而有些时候我们需要更改PC存储的指令地址,让CPU先执行该指令——这是跳跃寻址。
顺序寻址和跳跃寻址都属于指令寻址,因为他们都是直接给出地址,相当于直接告诉计算机“你去地址5找数据”。
但是指令寻址太过死板,不会“变通”:
如果告诉计算机的地址不是5,而是一个比5大得多的数,地址码装不下怎么办?
地址5是相对于地址0来说的,而一段程序中的指令位置会随着程序的移动而移动。意味着如果该程序的起始指令地址变动为了100,那么你应该要找的地址是105而不是5。
指令和数据如果都存储在主存中,那么每次读取都要经过主存。可以把部分数据放在速度更快的寄存器中,以此来提升速度吗?
数据寻址可以解决以上问题。
数据寻址的指令格式由操作码、寻址特征、形式地址构成。

寻址特征类似“函数”,CPU只要把形式地址经过“函数”计算一下,就能得出有效地址。
以下列出十种数据寻址。由于只有十种,所以可以用四位二进制来表示不同的寻址特征,计算机看到这四位二进制便能知道要做怎样的操作:
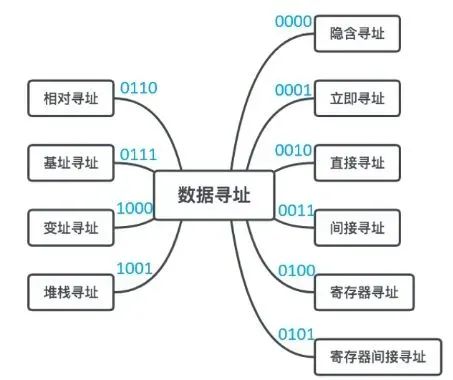
立即寻址:准确的说它并没有在寻址,而是把实际要操作的数据放在了形式地址中。
隐含寻址:加法计算需要两个数值相加,但这时计算机只给出了一个数值地址。在没有另一个数值地址的情况下,计算机会去一些默认的地方——例如累加寄存器(AC)中寻找另一个数值,这样就节省了一个地址的长度。
直接寻址:顾名思义,直接提供数值地址。
间接寻址:通过形式地址在主存中找到的数值还是一个地址——地址的地址,于是又去主存中找。由于主存所能存储的空间比单条指令要长的多,所以可以表示更大的范围,找到更远的数。(多次间接寻址是在一次间接寻址的基础上,再进行间接寻址。)
寄存器寻址:形式地址指向的是某个寄存器的地址。
寄存器间接寻址:与间接寻址相同,通过形式地址在寄存器中找到的数值还是一个地址,于是又去主存中找。
以下三种数据寻址方式属于数据寻址中的偏移寻址:偏移寻址的特点在于,都是基于一个基地址加上偏移量来得到有效地址。单是形式地址所提供的地址不够计算,需要额外的专用寄存器来帮忙。
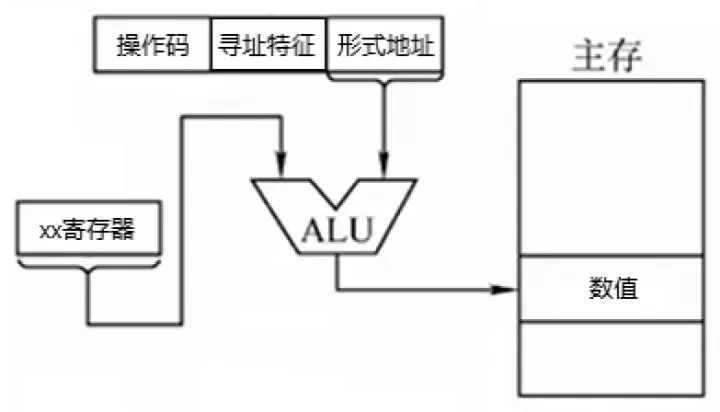
例如一个程序的初始地址为100,代码在程序中的次序为5,那么该指令的有效地址为105
基址寻址会在形式地址中给出5,BR寄存器(base address register)会给出100,然后ALU计算出105。
变址寻址会在形式地址中给出100,IX寄存器(index register)会给出5,然后ALU计算出105。
相对寻址会在形式地址中给出5,PC寄存器给出100,然后ALU计算出105。
他们有什么不同?这样倒来倒去有什么意义?
主要原因在于程序,或者程序中的代码会频繁变动,我们需要把其中频繁变动的变量,放在专属的寄存器中便于改动。
如果一个程序在主存中的位置频繁改变,那我们就应该把频繁改变的初始地址放在BR寄存器内修改——基址寻址。
如果一个代码在程序中的位置频繁改变(考虑对一个数组进行循环相加,我们只要将IX里的值不断加1,即可不断往后取到数组内的数值),那我们就应该把频繁改变的偏移量放在IX寄存器内修改——变址寻址。
如果这两个条件都占呢?——基址与变址复合寻址。
至于相对寻址,它是基址寻址的“变种”。它的基地址是当前指令的地址,根据形式地址给出的偏移量,PC可以直接跳到有效地址让计算机执行指令。
还有最后一种数据寻址——堆栈寻址。
简单来说就是用一个先入后出的栈往里面放地址,栈顶始终由SP寄存器(Stack Segment)来控制。当你想要拿地址或存地址时,只需要告诉计算机从SP那拿地址——至于SP怎么移动那是SP的事,不用给具体地址(很像隐含寻址)。
通过发出以上不同格式的指令,我们可以从多个角度、多个方面告诉计算机应该做什么事情,但是计算机又是如何将这些指令一步步落实的呢?
有了以上介绍,接下来让我们再简要总结下:
1.指令集是什么
2.指令集分类
3.指令集的作用
======
休息一下,接着聊。
一台计算机的指令集反映了该计算机的全部功能,机器类型不同,其指令集也不同,因而功能也不同。指令集的设置和机器的硬件结构密切相关,一台计算机要有较好的性能,必须设计功能齐全、通用性强、内含丰富的指令系统,这就需要复杂的硬件结构来支持。
常见的指令集有:Intel的x86,EM64T,MMX,SSE,SSE2,SSE3,SSSE3 (Super SSE3),SSE4A,SSE4.1,SSE4.2,AVX,AVX2,AVX-512,VMX等指令集;和AMD的x86,x86-64,3D-Now!指令集。
参考
https://zhuanlan.zhihu.com/p/402924801
https://www.eefocus.com/baike/511008.html
https://blog.csdn.net/hepiaopiao_wemedia/article/details/124762226
https://baike.baidu.com/item/ARM%E6%8C%87%E4%BB%A4%E9%9B%86/907786?fr=aladdin
