




DuckDB 性能揭秘:用纽约出租车数据集挑战 CSV 读取极限
作者: Pedro Holanda
原文: https://duckdb.org/2024/10/16/driving-csv-performance-benchmarking-duckdb-with-the-nyc-taxi-dataset.html

纽约出租车数据集[1] 记录了纽约市多年出租车行程,是一个在数据库基准测试[2]、机器学习[3]和数据可视化[4]等领域广泛使用的重要数据集。
2022 年,数据提供方决定将数据以 Parquet 文件代替 CSV 文件发布。就性能而言,这一决定非常明智。Parquet 文件更小,并且其列式存储格式支持高效读取。然而,这使得很多系统无法直接加载这些文件。
在Redshift 上的十亿出租车行程[5]的博客中,提出了一种新的数据库基准测试,用以评估在出租车数据集上执行聚合操作的性能。数据集还与天气、出租车类型以及上下车位置等其他数据集进行了连接,并且被存储为多个 gzip 压缩的 CSV 文件,每个文件约含 2000 万行数据。
作为 CSV 文件的出租车数据集
DuckDB 以其出色的 CSV 读取性能[6]闻名,我们希望通过这个基准测试的加载过程,探究是否能找到我们 CSV 读取器中的性能瓶颈。于是,我们着手生成这些数据集,并在 DuckDB 中进行性能分析。根据 AWS Redshift 的一项研究,CSV 文件是 S3 中使用最广泛的外部数据源[7],而且其中 99% 的文件都是 gzip 压缩的。因此,基准测试采用拆分后的 gzip 文件这一点引起了我们的兴趣。
本文将为您详细介绍如何在 DuckDB 中运行该基准测试,并总结我们从中学到的一些经验与未来可能的改进方向。该基准测试使用的数据集是公开提供的[8]。这个数据集被分成 65 个 gzip 压缩的 CSV 文件,每个文件包含 2000 万行数据,单个文件大小约为 1.8 GB。整个数据集压缩后为 111 GB,解压后为 518 GB。我们还提供了数据集生成的更多细节,并指出了我们分发的数据集与Redshift 上的十亿出租车行程[9]描述的原始数据集之间的差异。
复现基准测试
进行公平的基准测试是个相当复杂的问题[10],尤其是当基准测试所需的数据、查询和结果难以获取或运行时。为了简化操作,我们在 taxi-benchmark GitHub 仓库[11] 中提供了相关脚本。
仓库包含三个主要的 Python 脚本:
1.
generate_prepare_data.py
:下载所需文件并准备基准测试数据。2.
benchmark.py
:执行基准测试并验证结果。3.
analyse.py
:分析基准测试结果,并生成本文中讨论的部分见解。
这个基准测试并非完全完美——实际上,任何基准测试都不可能完美。但我们相信分享这些脚本是个积极的开端,我们也欢迎任何对脚本进行优化的贡献。
仓库中还包含详细的 README 文件,说明如何使用这些脚本。
这个仓库将成为本文实验的基础。
准备数据集
首先,您需要通过执行 python generate_prepare_data.py[12] 下载并准备所有文件。脚本会将 65 个文件下载到 ./data
文件夹中,并将它们解压缩合并为一个大文件。
最终,./data
文件夹中将有 65 个 gzip 压缩的 CSV 文件(文件名从 trips_xaa.csv.gz
到 trips_xcm.csv.gz
)和一个包含完整数据的未压缩 CSV 文件(文件名为 decompressed.csv
)。
我们将基准测试分为以下两种场景进行:
1. 加载 65 个压缩文件。
2. 加载一个未压缩的大文件。
当文件准备就绪后,您可以通过运行 python benchmark.py[13] 来启动基准测试。
加载过程
基准测试的加载阶段会针对每个场景运行六次。前五次运行中,我们记录并取其加载时间的中位数。在第六次运行时,收集资源使用数据(例如 CPU 使用率、磁盘读写情况)。
所有加载操作都在内存中的 DuckDB 实例中执行,数据不会被持久存储到 DuckDB,而是仅在连接期间存在。由于数据集无法完全装入内存,部分数据会被写入磁盘上的临时空间。由于未持久化存储,加载过程会明显更快,但查询速度可能略慢,因为 DuckDB 使用了未压缩的格式[14]。在此次基准测试中,我们主要关注 CSV 读取器的性能,而非查询性能,因此选择不对数据进行持久化。
表的模式定义在 schema.sql[15] 文件中。
schema.sql。
CREATE TABLE trips (
trip_id BIGINT,
vendor_id VARCHAR,
pickup_datetime TIMESTAMP,
dropoff_datetime TIMESTAMP,
store_and_fwd_flag VARCHAR,
rate_code_id BIGINT,
pickup_longitude DOUBLE,
pickup_latitude DOUBLE,
dropoff_longitude DOUBLE,
dropoff_latitude DOUBLE,
passenger_count BIGINT,
trip_distance DOUBLE,
fare_amount DOUBLE,
extra DOUBLE,
mta_tax DOUBLE,
tip_amount DOUBLE,
tolls_amount DOUBLE,
ehail_fee DOUBLE,
improvement_surcharge DOUBLE,
total_amount DOUBLE,
payment_type VARCHAR,
trip_type VARCHAR,
pickup VARCHAR,
dropoff VARCHAR,
cab_type VARCHAR,
precipitation BIGINT,
snow_depth BIGINT,
snowfall BIGINT,
max_temperature BIGINT,
min_temperature BIGINT,
average_wind_speed BIGINT,
pickup_nyct2010_gid BIGINT,
pickup_ctlabel VARCHAR,
pickup_borocode BIGINT,
pickup_boroname VARCHAR,
pickup_ct2010 VARCHAR,
pickup_boroct2010 BIGINT,
pickup_cdeligibil VARCHAR,
pickup_ntacode VARCHAR,
pickup_ntaname VARCHAR,
pickup_puma VARCHAR,
dropoff_nyct2010_gid BIGINT,
dropoff_ctlabel VARCHAR,
dropoff_borocode BIGINT,
dropoff_boroname VARCHAR,
dropoff_ct2010 VARCHAR,
dropoff_boroct2010 BIGINT,
dropoff_cdeligibil VARCHAR,
dropoff_ntacode VARCHAR,
dropoff_ntaname VARCHAR,
dropoff_puma VARCHAR);
65 个文件的加载器使用以下 SQL 语句:
COPY trips FROM 'data/trips_*.csv.gz' (HEADER false);
未压缩的单个文件使用以下 SQL 语句加载:
COPY trips FROM 'data/decompressed.csv' (HEADER false);
查询
数据加载完成后,基准测试脚本会运行每个基准查询[16]五次,并记录其执行时间。此外,查询结果会与相应的参考答案[17]进行验证,以确保测试结果的准确性。所有查询与原始十亿出租车行程[18]基准测试中使用的查询完全一致。
结果
加载时间
尽管我们处理的是一个包含 51 列的大型 CSV 数据集,DuckDB 仍能相当快速地完成数据加载。
需要注意的是,DuckDB 默认保留数据的插入顺序,这对性能有一定影响。以下结果中的所有数据集加载操作都将此选项设置为 false
。
SET preserve_insertion_order = false;
所有实验均在 Apple M1 Max(64 GB RAM)上运行,我们比较了单个未压缩 CSV 文件和 65 个压缩 CSV 文件的加载时间。
| 名称 | 时间(分钟) | CPU 使用率与 100% 的平均偏差 |
| 单文件——未压缩 | 11:52 | 31.57 |
| 多文件——压缩 | 13:52 | 27.13 |
从多个压缩文件加载数据比从单个未压缩文件加载更具 CPU 效率。多个压缩文件的 CPU 使用率偏差较小,表明 CPU 空转时间更少。主要有两个原因:(1)压缩文件比未压缩文件小约 8 倍,大大减少了从磁盘加载的数据量,从而减少了 CPU 等待数据处理的停顿时间;(2)并行化多个文件的加载比单个文件更容易,因为每个线程都可以独立处理一个文件。
CPU 效率差异也体现在执行时间上:从单个未压缩文件加载数据比从多个压缩文件快 2 分钟。这主要是由于我们当前的解压算法设计存在局限性。读取压缩文件包括三项操作:(1)将数据从磁盘加载到压缩缓冲区;(2)解压数据至解压缓冲区;(3)处理解压缓冲区。当前实现中,任务 1 和任务 2 被合并为一个操作,导致在当前缓冲区完全解压之前无法继续读取,进而导致 CPU 空转时间增加。
内部工作机制
我们可以进一步查看内部数据处理的情况,以验证加载时间的差异。
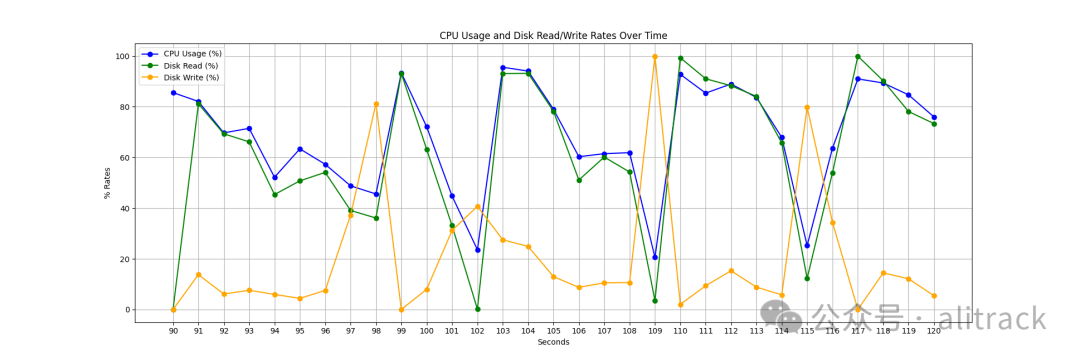
下图展示了 “单文件——未压缩” 运行时 CPU 和磁盘的利用率快照。可以看到,达到 100% CPU 利用率具有挑战性,由于数据被写入磁盘表,我们经常遇到停顿现象。另一个关键点是,CPU 利用率与磁盘读取高度相关,说明线程经常在处理数据之前等待数据加载。如果为 CSV 读取器/写入器引入异步 IO 技术(在后台进行输入/输出操作),并行处理性能将显著提升,因为单线程就能高效处理大部分磁盘 IO 操作,同时不影响 CPU 利用率。
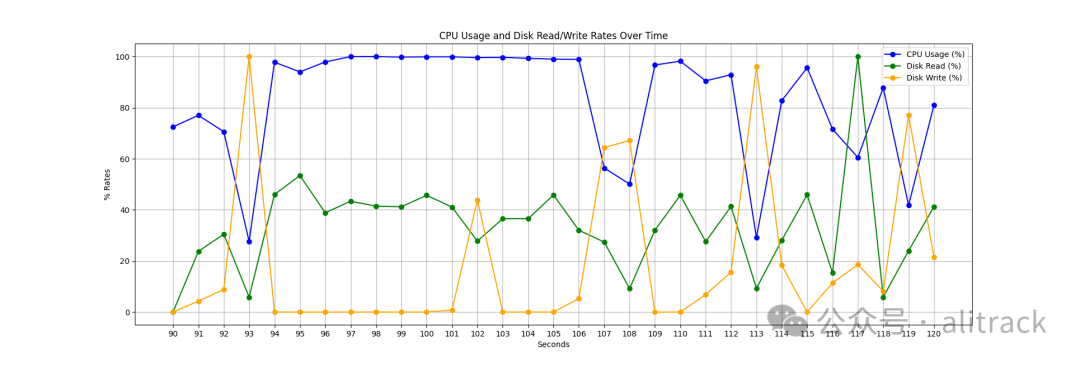
下图展示了 65 个压缩文件加载时的类似快照。虽然我们仍然在数据写入时遇到停顿,但由于压缩文件的数据体积较小,CPU 利用率显著提高。在这种情况下,数据的并行化处理更为简单。与未压缩文件类似,CPU 利用率中的空隙可以通过引入异步 IO 以及优化的解压算法来缓解。
查询时间
为了更加全面,我们还展示了在配备 M1 Pro CPU 的 MacBook Pro 上四个查询的执行时间。此对比展示了使用纯内存连接(无存储)与数据加载并持久化到数据库后的查询时间差异。
| 名称 | 无存储时间(秒) | 有存储时间(秒) |
| Q 01 | 2.45 | 1.45 |
| Q 02 | 3.89 | 0.80 |
| Q 03 | 5.21 | 2.20 |
| Q 04 | 11.2 | 3.12 |
最大的差异在于,当 DuckDB 使用持久化存储时,数据被高效压缩[19],因此查询数据集的速度快得多[20]。相比之下,当我们不使用持久化存储时,内存数据库会临时将数据存储在未压缩的 .tmp
文件中,以便处理内存溢出,这增加了磁盘 IO 负担,从而导致查询时间更长。这一发现引发了我们一个新的探索方向:是否可以通过对临时数据进行压缩来提升性能。
数据集生成过程
原始博客文章基于纽约市出租车和豪华轿车委员会发布的 CSV 文件生成了这个数据集。最初,这些文件包括精确的上车和下车经纬度坐标。然而,从 2016 年中期开始,为了保护隐私,这些精确坐标被模糊化为上车和下车位置的几何对象(甚至有故事说通过检查出租车的目的地导致婚姻破裂)。此外,近年来 TLC 决定将数据重新分发为 Parquet 文件,并且完全匿名化了所有经纬度数据,包括 2016 年中期之前的数据。
这为基准测试带来了问题,因为Redshift 上的十亿出租车行程[21]博客依赖于这些详细的位置信息。让我们来看一下以下的数据片段:
649084905,VTS,2012-08-31 22:00:00,2012-08-31 22:07:00,0,1,-
73.993908,40.741383000000006,-73.989915,40.75273800000001,1,1.32,6.1,0.5,0.5,0,0,0,0,7.1,CSH,0,0101000020E6100000E6CE4C309C7F52C0BA675DA3E55E4440,0101000020E610000078B471C45A7F52C06D3A02B859604440,yellow,0.00,0.0,0.0,91,69,4.70,142,54,1,Manhattan,005400,1005400,I,MN13,Hudson Yards-Chelsea-Flatiron-Union Square,3807,132,109,1,Manhattan,010900,1010900,I,MN17,Midtown-Midtown South,3807
我们看到精确的经纬度坐标:-73.993908,40.741383000000006,-73.989915,40.75273800000001
,以及根据这些经纬度生成的 PostGIS 几何十六进制 blob:0101000020E6100000E6CE4C309C7F52C0BA675DA3E55E4440,0101000020E610000078B471C45A7F52C06D3A02B859604440
(使用 ST_SetSRID(ST_Point(longitude, latitude), 4326)
生成)。
由于这些详细信息对数据集非常重要,因此无法再像原博客中描述的那样生成文件,因为这些详细位置信息已经缺失。然而,互联网从不遗忘。通过多方查找,我们找到了各种来源分发的原始数据集,例如 [1][22],[2][23],和 [3][24]。借助这些资源,我们将原始 CSV 文件与博客[25]中提到的天气信息相结合,生成了与原始博客类似的数据集。
此数据集与原始数据集有何不同?
我们的数据集与 “Redshift 上的十亿出租车行程” 博客中的数据集存在两个显著差异:
1. 我们的数据集包含截至 2016 年 6 月 30 日的精确经纬度信息,而原始文章仅使用了截至 2015 年底的数据(因为该文章发表于 2016 年 2 月)。
2. 我们的数据集包含了 Uber 行程数据,而原始数据集中未包含。
如果您希望使用与原始数据集更接近的数据进行基准测试,可以通过筛选掉额外数据生成新表。例如:
CREATE TABLE trips_og AS
FROM trips
WHERE pickup_datetime < '2016-01-01'
AND cab_type != 'uber';
结论
本文介绍了如何在 DuckDB 上运行出租车数据基准测试。我们提供了完整的脚本,便于您在喜欢的系统上进行基准测试。我们还展示了如何利用这个基准测试来评估 DuckDB 的性能,并从中获得对未来改进方向的深入见解。
引用链接
[1]
纽约出租车数据集: https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page[2]
数据库基准测试: https://tech.marksblogg.com/benchmarks.html[3]
机器学习: https://www.r-bloggers.com/2018/01/new-york-city-taxi-limousine-commission-tlc-trip-data-analysis-using-sparklyr-and-google-bigquery-2/[4]
数据可视化: https://www.kdnuggets.com/2017/02/data-science-nyc-taxi-trips.html[5]
Redshift 上的十亿出租车行程: https://tech.marksblogg.com/billion-nyc-taxi-rides-redshift.html[6]
出色的 CSV 读取性能: https://x.com/jmduke/status/1820593783005667459[7]
CSV 文件是 S3 中使用最广泛的外部数据源: https://assets.amazon.science/24/3b/04b31ef64c83acf98fe3fdca9107/why-tpc-is-not-enough-an-analysis-of-the-amazon-redshift-fleet.pdf[8]
公开提供的: https://github.com/pdet/taxi-benchmark/blob/0.1/files.txt[9]
Redshift 上的十亿出租车行程: https://tech.marksblogg.com/billion-nyc-taxi-rides-redshift.html[10]
相当复杂的问题: https://pdet.github.io/assets/papers/benchmarking.pdf[11]
taxi-benchmark GitHub 仓库: https://github.com/pdet/taxi-benchmark[12]
python generate_prepare_data.py: https://github.com/pdet/taxi-benchmark/blob/0.1/generate_prepare_data.py[13]
python benchmark.py: https://github.com/pdet/taxi-benchmark/blob/0.1/benchmark.py[14]
DuckDB 使用了未压缩的格式: https://duckdb.org/docs/guides/performance/how_to_tune_workloads#persistent-vs-in-memory-tables[15]
`schema.sql`: https://github.com/pdet/taxi-benchmark/blob/0.1/sql/schema.sql[16]
基准查询: https://github.com/pdet/taxi-benchmark/tree/0.1/sql/queries[17]
参考答案: https://github.com/pdet/taxi-benchmark/tree/0.1/sql/answers[18]
十亿出租车行程: https://tech.marksblogg.com/benchmarks.html[19]
高效压缩: https://duckdb.org/2022/10/28/lightweight-compression.html[20]
查询数据集的速度快得多: https://duckdb.org/docs/guides/performance/how_to_tune_workloads%7D#persistent-vs-in-memory-tables[21]
Redshift 上的十亿出租车行程: https://tech.marksblogg.com/billion-nyc-taxi-rides-redshift.html[22]
[1]: https://arrow.apache.org/docs/6.0/r/articles/dataset.html[23]
[2]: https://catalog.data.gov/dataset/?q=Yellow+Taxi+Trip+Data&sort=views_recent+desc&publisher=data.cityofnewyork.us&organization=city-of-new-york&ext_location=&ext_bbox=&ext_prev_extent=[24]
[3]: https://datasets.clickhouse.com/trips_mergetree/partitions/trips_mergetree.tar[25]
博客: https://github.com/toddwschneider/nyc-taxi-data
