




autovacuum 介绍
PostgreSQL中内部数据一致性是基于多版本并发控制 (MVCC) 机制,该机制允许数据库引擎维护多个行版本,能提供更大的并发,同时尽量减少不同进程之间的阻塞。在这个过程中会保留旧版本的行,这些旧版本的不活跃的行记录(死元组)除非清理,否则会一直存在,不断累积并占用大量磁盘空间,至使表和索引的不断膨胀,降低扫描效率;同时,统计信息不准确可能会导致生成错误的执行计划,从而导致查询缓慢、性能低下。
autovacuum是PostgreSQL数据库的一个后台进程,会随数据库同步启动(autovacuum=on,默认)。PostgreSQL使用autovacuum进程周期调用vacuum来自动清理死元组,并调用analyze来自动更新统计信息用于执行计划(autovacuum_mode=mix,默认)。
autovacuum 触发
autovacuum进程每隔autovacuum_naptime(秒)周期性开启新一轮的vacuum和analyze,会通过autovacuum_max_workers参数设置产生对应个数的线程进行批处理,对每一张表进行扫描,检查是否满足vacuum和analyze的条件。
- autovacuum_vacuum的触发条件:
1. 表上死元组的数量超过了:autovacuum_vacuum_scale_factor * 表记录数 + autovacuum_vacuum_threshold
2. 表上最大事务id超过了参数autovacuum_freeze_max_age(默认为2亿)
- autovacuum_analyze的触发条件:
1. 表上死元组的数量超过了:autovacuum_analyze_scale_factor * tuples + autovacuum_analyze_threshold
2. 表上最大事务id超过了参数autovacuum_freeze_max_age(默认为2亿)
比如,现在有一张表:
总表记录数为1000
autovacuum_vacuum_scale_factor为0.05
autovacuum_vacuum_threshold为50
根据上面的公式计算当死元组的数量超过:1000*0.05+50=100时会触发autovacuum_vacuum
但是如果对于一个拥有千万记录的大表,死元组的数量需要达到10000000*0.05+50=500050时才进行vacuum
这个阈值对大表的性能影响就相对明显了
所以,不同大小的表可能并不适用同一个参数标准,对此的解决方案是对大表单独设置表级的参数阈值标准:
alter table xx SET (autovacuum_vacuum_scale_factor = xx);
autovacuum 性能问题
因为vacuum会占用IO,如果不对autovacuum的吞吐量进行限制,那么autovacuum在后台处理大量死元组时会产生极高的IO冲击,导致业务受到很大影响。PostgreSQL设置了成本限制(cost_limit)的方式控制autovacuum带来的IO开销,使得业务尽可能不会受到autovacuum的影响。
具体而言,当一次自动vacuum产生的cost累积达到设定的阈值autovacuum_vacuum_cost_limit(同vacuum_cost_limit)时,会休眠autovacuum_vacuum_cost_delay的时间,重置累积的cost为0并继续执行,再次达到阈值时则再次休眠,如此不断反复该过程实现对autovacuum性能开销的管控,下面是单位时间内(1s)的autovacuum效率估算公式 :

三种代价参数:
- vacuum_cost_page_hit:内存读取数据块的开销(内存读)。 默认值设置为 1。
- vacuum_cost_page_miss:磁盘读取数据块的开销(磁盘读)。 默认值设置为 10。
- vacuum_cost_page_dirty:磁盘中打扫死元组的开销(磁盘写)。 默认值设置为 20。
成本限制相关参数:
- vacuum_cost_limit:vacuum的成本限制,成本达到该阈值后进入休眠,休眠结束后继续vacuum
- autovacuum_vacuum_cost_limit:同上,默认为-1代表直接引用vacuum_cost_limit的值
- autovacuum_vacuum_cost_delay:休眠时间,单位为ms
vacuum 性能优化
demo:
假设vacuum_cost_limit为1000,三种处理类型的cost为默认值1.10.20,vacuum_cost_delay为10ms
内存中一次性扫描的块数是1000*8k=8M 歇10ms后继续,1s可以进行100次,内存扫描的峰值可达到将近800M/s(读)
磁盘中一次性扫描的块数是100*8k=0.8M 歇10ms后继续,1s可以进行100次,磁盘扫描的峰值可达到将近80M/s (读)
磁盘中一次性打扫的块数是50*8k=0.4M 歇10ms后继续,1s可以进行100次,磁盘打扫的峰值可达到将近40M/s (写)
1. 如果无法接受这种额外的资源消耗,可以适当调整这五个参数即可(根据上面的公式调大或者调小参数)。
2. 如果觉得vacuum效率太慢,可以同步增大vacuum_cost_limit(默认200,机械盘可调大1000-2000,对于SSD磁盘可以调大到几千到一万)
和autovacuum_max_workers(该参数对vacuum没有很直接的影响,但是当autovacuum_vacuum_cost_limit明显增大时,可以适当调大),
可适当减小vacuum_cost_delay(最低1ms)
测试:
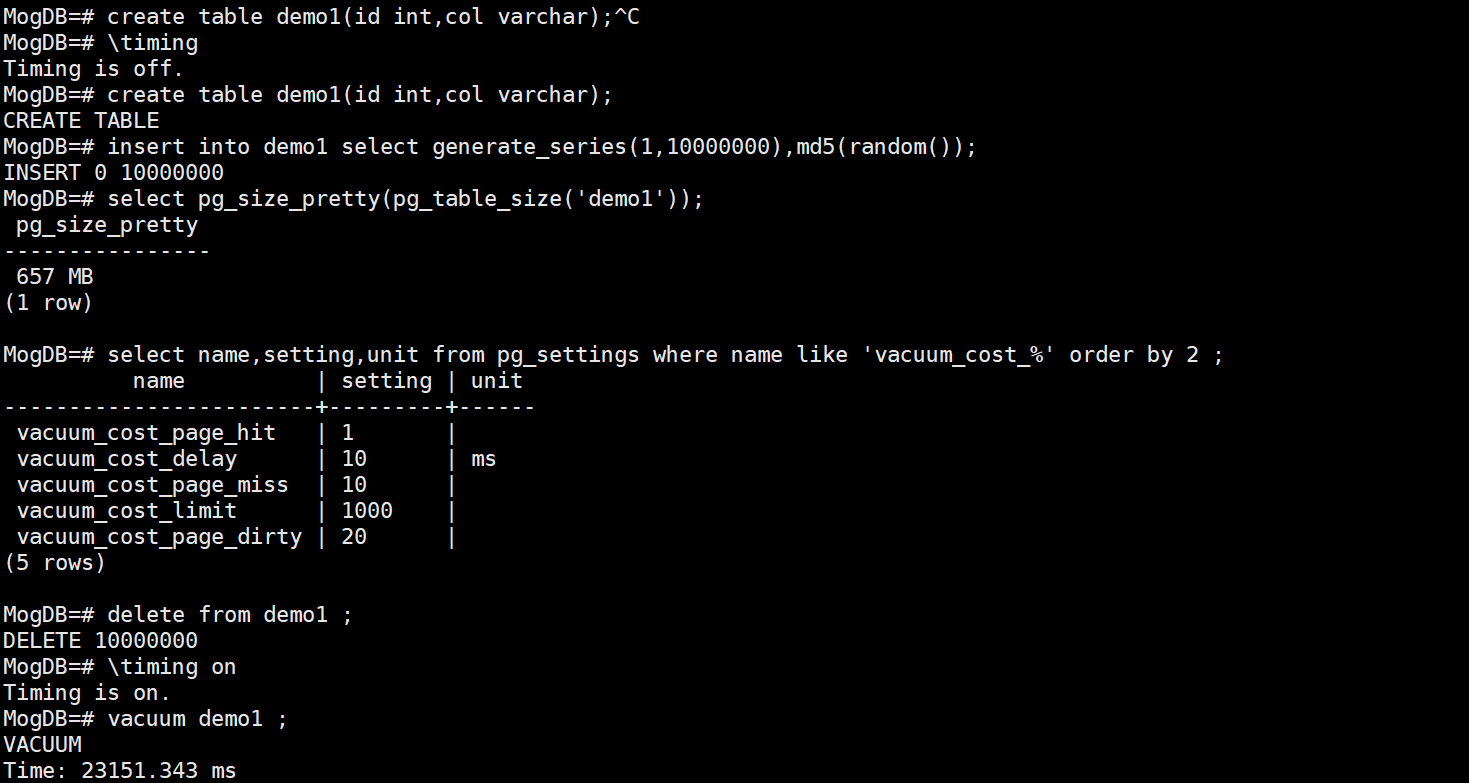
假设现在demo1表的死元组的数据量是640MB
三种代价参数的cost为默认值1 10 20
vacuum_cost_limit为1000,vacuum_cost_delay为10ms
手动执行vacuum,估算完成的时长:640MB÷80M/s=8s,640MB÷40M/s=16s,即24s左右
对比测试:
修改参数vacuum_cost_limit为10000,vacuum_cost_delay为2ms,预估性能提升50倍
手动执行vacuum,估算完成的时长:640MB÷4GB/s=0.16s,640MB÷2GB/s=0.32s,即0.5s左右
但是实际测试提升的倍数大概只有20倍左右:
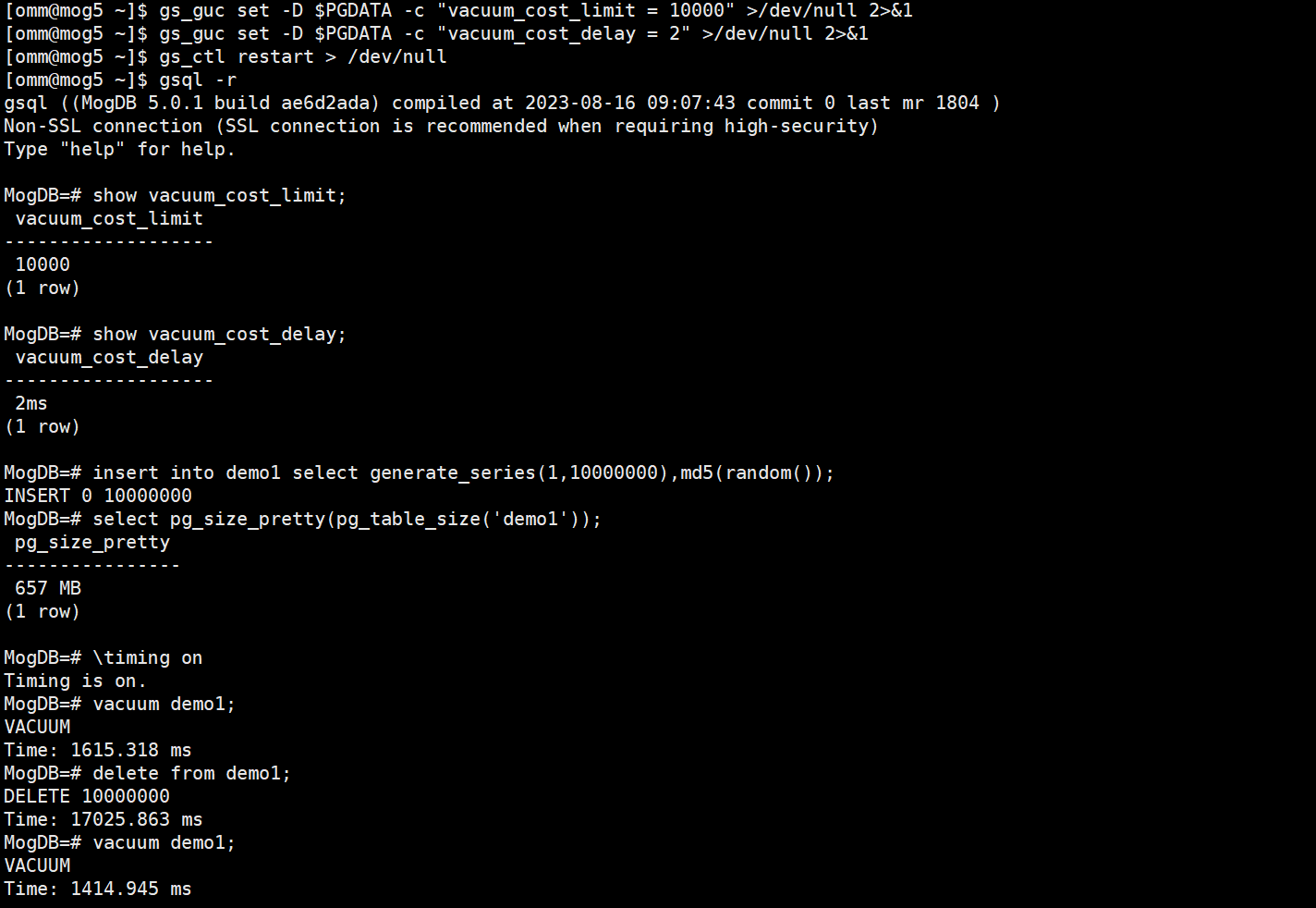
上述测试说明根据公式推导的是一个理论值,vacuum的性能实际情况下还会受到其他因素的影响如主机压力、maintenance_work_mem(autovacuum_work_mem)的大小、表的fillfactor。
以上性能优化思路同样适用于autovacuum,autovacuum关于成本限制的参数和休眠参数一般直接套用vacuum对应的参数即可:
autovacuum_vacuum_cost_limit 设置为-1即使用vacuum_cost_limit的值
autovacuum_vacuum_cost_delay 设置为-1即使用vacuum_cost_delay的值
需要注意的是:autovacuum_max_workers的值尽量使用默认值,不要调的太大或者太小
autovacuum 阻塞场景
- 长事务:在业务高并发下,astore存储引擎使得历史版本数据不断增多,这些历史数据的回收需要对应的事务提交或者回滚后才能进行,所以长事务会滞后vacuum操作。
- idle in transaction连接:如果一个事务处于idle in transaction状态(事务空闲,但不提交)太长时间,它会阻止VACUUM进程回收空间,造成表数据膨胀,会导致事务ID wraparound,甚至严重可能会占用大量的内存,从而导致数据库崩溃。
vacuum 与 vacuum full

