




点击蓝字 · 关注我们
作为当代金融业务系统中最重要的基础软件之一,数据库的国产化、安全可控对于提高整个行业安全性及供应链风险抵抗能力显得尤为重要。本文着眼于异构数据库迁移中的全量数据复制环节,结合我行自研的数据库迁移平台,与大家一起进行深入探索。
01 前言
全量数据复制一般是数据迁移的第二步,简言之,它所实现的功能就是从源库中导出全部需要的数据,然后再导入到目标库中。
因为我们考虑的是异构数据库之间的迁移,因此基本上各数据库厂商自带的导入导出工具将不再适用。当然,我们可以在一定程度上复用这些工具,来实现开发成本和迁移效率上的效益最大化。
参见之前的文章《数据库迁移解决方案探索之表结构转换》,我们的平台已经实现了异构数据库的表结构转换,因此,在本文中将只考虑纯粹数据的复制。
02 场景分析
全量数据复制的场景非常简单——数据导出+数据导入,下面我们分别来分析一下这两个过程可能面临的挑战。
(一)数据导出
将数据库内容导出的方式有很多种,最简单的就是利用数据库自带的工具,此时我们不考虑导出为特有二进制文件格式的工具,只考虑导出为文本文件的工具。这是因为在异构数据库间迁移,导出的源库格式文件往往并不能直接在目标库上使用,如此选择可以避免我们后续对文件内容进行解析所带来的额外复杂度。
数据库自有导出工具(后文简称导出工具)在导出文本文件时,一般是以特定分隔符来分隔各个字段,以换行符来区分各条记录。此时就会面临它的第一个局限性:如果数据中有这些特殊符号该怎么办?
大多数的导出工具仅提供到表级别的导出,并不支持多个类似表数据合并或拆分等等,而我们在表结构转换的过程中,可能目标库的表已经发生了此类变化。此时就会面临它的第二个局限性:以表为单位的数据集发生了变化该怎么办?
大多数的导出工具未能提供断点续作功能,如果任务中间中断,那么就会面临第三个局限性:任务中断时只能重新再进行完整导出。
因此,根据上面的分析,最好的解决方案就是设计一个能够解决包括上述问题在内的统一导出功能。
(二)数据导入
类比数据导出的分析,我们首先想到的就是要设计一个统一的导入功能。当然,这肯定是要满足的,JDBC提供了很好的兼容性,基于JDBC的批量数据插入就是一个最容易的实现方式,我们的迁移工具首先实现的就是这种方式,并将其命名为BRIDGE方式。
那么,这种万能的方式就足够了么?
答案当然是不够,因为它虽然万能,却舍弃了效率。每一个数据库迁移任务,其时间窗口都是有限的,全量数据复制往往是这个窗口内最耗时的操作,因此必须最大化地提升其效率,而为了提高效率,就只能根据不同的数据库进行相应的定制化导入。这样,数据自有导入工具(后文简称导入工具)就跃入了我们的眼帘。
同导出一样,我们也不考虑基于特有二进制文件格式的导入工具,同样也不考虑需要额外架设服务或建立很多辅助表的导入工具,因为只有这样才能实现对目标库的零侵入。
基于上面的原则,我们就可以选择例如Oracle的sqlldr、MySQL的load
data等这些已经经过实践证明非常高效的方式。那么此时将只面临一个问题:我们需要针对不同的工具,生成满足其需要的文件格式。由于这些都是文本文件,自然复杂度就降了下来。
03 核心设计
根据前面的分析,很自然地面临着两个选择:
将导出和导入合并为一个过程还是分开为两个
导出和导入处理的数据文件要不要落地
导出和导入解耦
这样就可以单独执行导出,将数据文件复制到其它地方后,再单独执行导入,甚至复制到多个地方多次导入,亦可以同时执行全部过程,灵活性大大提高。
导出和导入可以分别控制并发
灵活的断点续作控制
比如可以控制导出为表级别的导出,不必每次重跑全部任务,导入可以控制到数据文件级别,大大节省导出导入时间。
根据以上分析,全量数据复制流程大体如下:
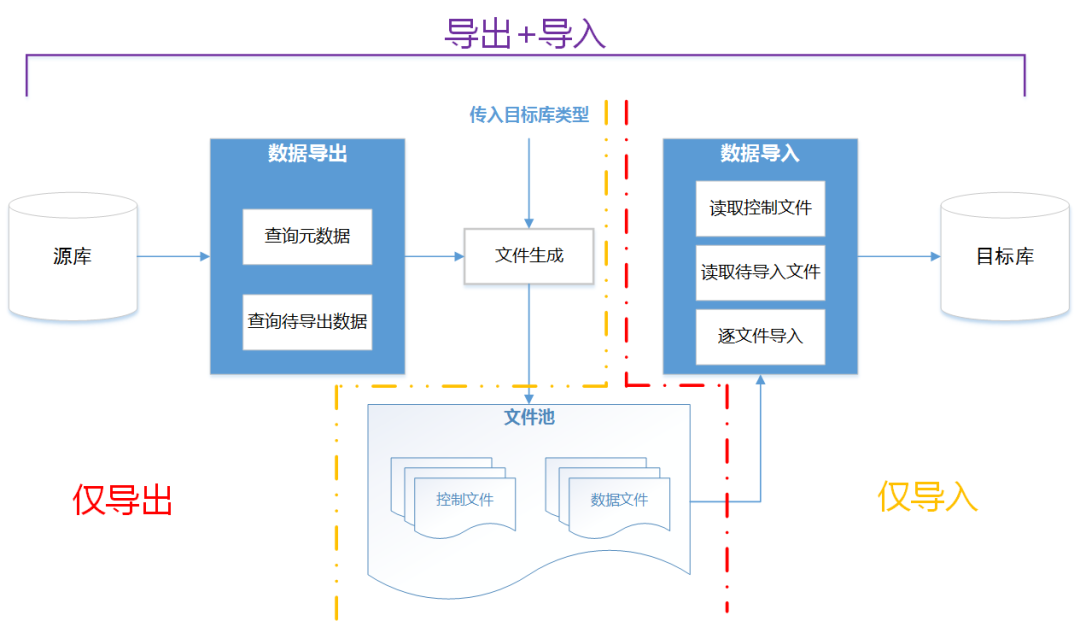
上图全图为完整流程,红色虚线左侧为仅导出流程,金色虚线右侧为仅导入流程,实际上的并发细节在图中做了省略。
接下来我们再分别看一下导出和导入的具体设计。
(一)导出设计
首先,在数据获取阶段,可以通过JDBC接口来对接各种不同的数据库,先获取元数据(此时仅需要字段及类型),然后再用一条SQL语句查询获取待导出数据即可。
最重要的工作在文件生成阶段,此时需要根据不同的目标数据库类型,来生成不同格式的文件,因此就需要熟知各数据库的相关知识。特别的,我们也把前文提到的BRIDGE导入方式看作一种特殊的数据库,也为它生成一种单独的文件格式,这样在导入时,就可以不用再区别对待。
为了解决数据库自有导出工具的诸多局限,我们将导出粒度设定为一条SQL查询语句,该语句可以包括JOIN、WHERE、UNION等任意字句,例如可以通过UNION将两张表数据合并在一起。
导出时按照上述粒度进行并发,并发度由参数控制,同时有其它参数控制单个数据文件大小,每个数据文件其实是导入时的并发粒度,这样就能实现导出和导入同步进行。
针对一条SQL语句的导出流程大体如下:
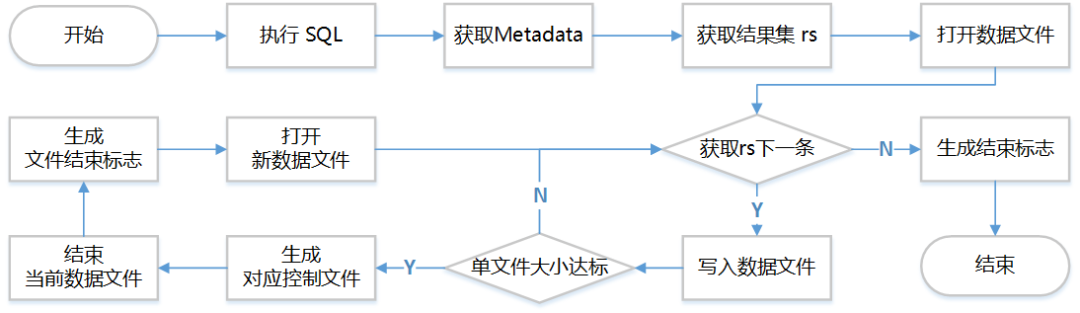
当然,上图中省略了错误处理,而且上图中生成文件仅是一个高度简化后的示意,实际上,对于Oracle会生成sqlldr文件,对于MySQL会生成load data文件,对于GaussDB会生成Copy Manager文件等等。而且,生成对应文件的各种选项也是我们精心挑选的,以最大化地提升效率和兼容性。例如我们实现了任意数据生成二进制格式Copy Manager文件以最大化GaussDB导入效率。
(二)导入设计
相对于导出,导入的设计比较简单,因为在导出时已经生成了数据文件和控制文件,导入仅需按照控制文件指示来导入数据即可。
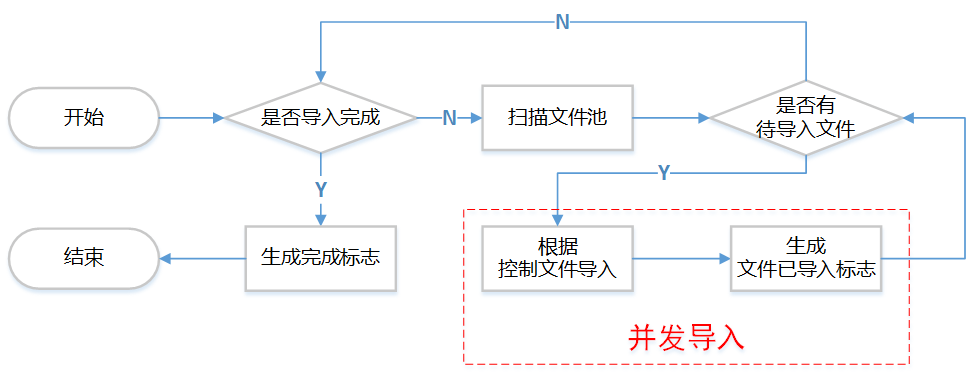
同样为简化起见,上图中省略了错误处理部分。其核心是根据控制文件导入,在这里针对主流数据库简单介绍一下:
针对Oracle数据库,控制文件即sqlldr控制文件,导入时会调用sqlldr命令进行导入
针对MySQL数据库,控制文件即load data命令,导入时会适用MySQL客户端执行load data命令
针对GaussDB、PostgreSQL数据库,控制文件为CopyManager执行语句,导入时会通过CopyManager API进行导入
BRIDGE导入方式,控制文件里即目标表和字段信息,导入时会根据这些信息用JDBC批量插入接口进行导入
04 其他考虑
(一)粒度控制及灵活性
源表;目标表;SELECT语句;源字段:目标字段,源字段:目标字段... |
除源表字段不可为空外,其它字段均可以为空或省略,当然,如果要指定后面的字段,此时前面的字段不能省略,只能留空,即分号占位符必须存在。
控制语句 | 含义 |
T1 | 复制源库表T1全部数据到目标库表T1 |
T1;T2 | 复制源库表T1全部数据到目标库表T2 |
T1;T2;SELECT * FROM T3 | 按照SQL语句导出数据到T2中,注意,此时指定的T1其实没用,仅作为与其它语句区分。 |
T1;;;COL1:C1,COL2:C2 | 复制T1全部数据到目标表T1,源表字段COL1对应目标表C1,源表字段COL2对应目标表C2 |
通过这样一个简单的设计,就在避免了数据库自带导出工具局限性的同时,极大地扩展了我们工具的灵活性。
当然您可能觉得这还不够,比如说我想将所有表(假设有1000张)原样迁移到目标库,难道要手动指定所有表?答案当然是不用,针对这样的场景,源表名其实是支持通配符的,规则如下:
单独一个*代表全部表
表名中带%表示模糊匹配,例如tab%
表名以-开始表示不复制这些表,例如 -test%
同时多种匹配模式都命中某张表时,按以下优先级顺序择一处理
首先,如果指定了不复制则必定不复制
其次,如果指定了具体规则按照具体规则处理
最后,如果是模糊匹配命中,按照原样迁移处理
根据上述规则再举一个例子:
控制语句 | 含义 |
* -TEST% WEI;CHEN | 所有以TEST开头的表不执行复制 源库表WEI复制到目标库表CHEN中 不满足上述条件的所有其它表原样迁移 |
(二)导出性能优化
为进一步提升导出效率,在设计时我们还针对具体的数据库做了相应的优化,例如对于支持分区表的数据库,可以采用按分区导出,对于较大的Oracle非分区表,可以按照我们的算法自动分片导出等等。
这些细节其实隐藏在了用户感知之外,对于用户来说,同样还是只需指定一个简单的表名或SQL语句,我们的工具会自动根据数据库里信息去修改这条SQL语句,为其开启具体优化。
(三)导入方式可选择
大多数时间人们都倾向于选择最快的数据复制方式,但现实中,受制于某些条件,最快的方式却未必是可用的。因此我们的迁移工具针对每一个目标库都提供了多种数据全量复制方式,这些可以通过参数进行指定,以方便用户选用。以GaussDB为例,我们就提供了CopyManager+文本格式、CopyManager+二进制格式和BRIDGE三种方式。
05 适用范围
对源库、目标库零侵入
导出、导入可同步进行也可分别进行
灵活的控制语句可满足已知的迁移需求
充分挖掘了各数据库在导入导出方面的性能底线
多种导入模式可供用户选择
支持在迁移过程中的字符集转换
近百个迁移参数控制且均有我们的最佳实践缺省值
目前支持的数据库范围为:
Oracle
MySQL及兼容MySQL的其它数据库
Postgres及兼容Postgres的其它数据库
GuassDB(openGauss\DWS)
DB2
SQL Server
GoldiLocks
06 小结
全量数据复制的过程中还有很多细节问题,限于篇幅此处不再详细展开,如果读者感兴趣,欢迎与我们联系。
本系列的后续文章将会继续对增量同步、数据校验等功能进行进一步探索,敬请继续关注。

微信号|基础技术研究
