




String类型
Redis中key和value的大小不能超过512M
redis中的过期时间不会因为修改超过而被刷新,只有当执行
set del getset
命令时,命令会清除超时时间
基本操作
> set mykey somevalue
OK
> get mykey
"somevalue"
#设置带有过期时间的key
redis> SET key-with-expire-time "hello" EX 10086
OK
redis> GET key-with-expire-time
"hello"
redis> TTL key-with-expire-time
(integer) 10069
#key不存在时会成功
> set mykey newval nx
(nil)
> set mykey newval xx
OK
#字符串自增 INCR 命令将字符串值解析成整型,将其加一,最后将结果保存为新的字符串值;它是线程安全的
> set counter 100
OK
> incr counter
(integer) 101
存储实现原理
以set hello world
为例,每个键值对都会有一个dictEntry
,它的结构如下图:
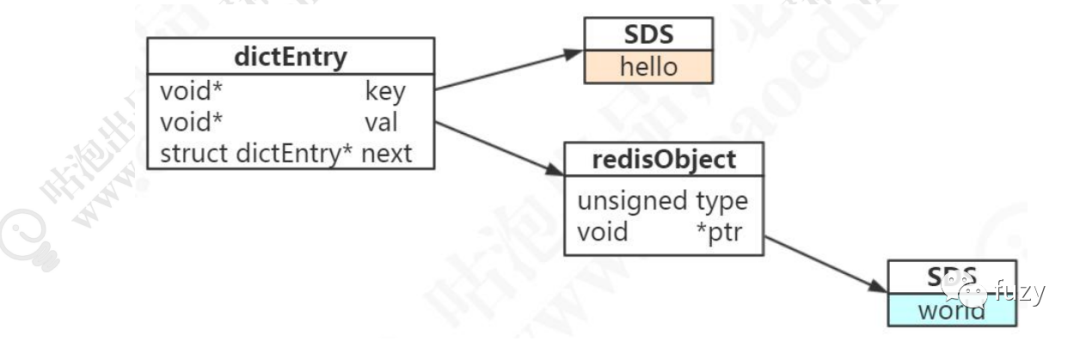
如图所示,key存储在SDS中,value存储在redisObject
对象中(五种常用的数据类型都是通过redisObject
来存储的)
SDS
redis中存储字符串的一种实现,它有几种结构分别用于存储不同长度的字符串。
字符串类型的内部编码有三种:
1、int,存储 8 个字节的长整型(long,2^63-1)。
2、embstr, 代表 embstr 格式的 SDS(Simple Dynamic String 简单动态字符串), 存储小于 44 个字节的字符串。
3、raw,存储大于 44 个字节的字符串
应用场景
热点数据缓存(例如报表,明星出轨),对象缓存,全页缓存。可以提升热点数据的访问速度。
分布式Session
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>分布式锁
set key value EX 10 NX:如果key存在则设置失败,否则10m后key过期。全局ID
incrby userid 1000计数器
Hash类型
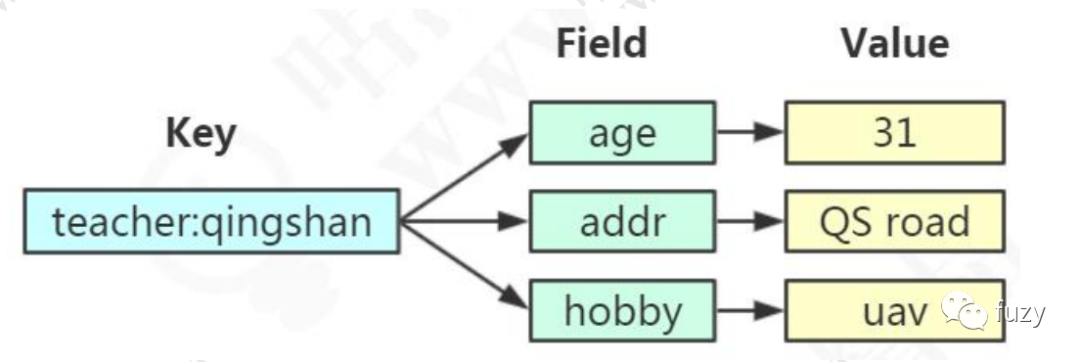
如图,Hash类型属于键值对类型,但value字段只能存储字符串,不能存储其他类型。
基本操作
#语法 hmset key field value field1 value1 [...]
> hmset user:1000 username antirez birthyear 1977 verified 1
OK
> hget user:1000 username
"antirez"
> hget user:1000 birthyear
"1977"
> hgetall user:1000
1) "username"
2) "antirez"
3) "birthyear"
4) "1977"
5) "verified"
6) "1"
应用场景
String可以做的事情,Hash都可以做(Hash更节省空间,一个key就能存储一个对象的数据)。另外还有其他适用场景,比如根据用户查询购物车信息,我们可以设置以下结构:
key:用户 id;field:商品 id;value:商品数量。
对应的操作可以设置以下命令操作来完成购物车操作:
购物车商品+1:hincr。
购物车商品-1:hdecr。
删除购物车:hdel。
全选:hgetall。
获取商品数量:hlen。
List类型
Redis lists基于LinkedList实现。也就是说该数据结构既有栈的特性也有队列的特性。
基本操作
#lrange 命令:lrange key start end:start和end都可以为负数,这是告知redis从尾部开始计数;
> rpush mylist A
(integer) 1
> rpush mylist B
(integer) 2
> lpush mylist first
(integer) 3
> lrange mylist 0 -1
1) "first"
2) "A"
3) "B"
> rpush mylist a b c
(integer) 3
> rpop mylist
"c"
> rpop mylist
"b"
> rpop mylist
"a"
常用场景
在博客引擎实现中,你可为每篇日志设置一个list,在该list中推入博客评论,等等。
List的阻塞操作
可以使用Redis来实现生产者和消费者模型,如使用LPUSH和RPOP来实现该功能。但会遇到这种情景:list是空,这时候消费者就需要轮询来获取数据,这样就会增加redis的访问压力、增加消费端的cpu时间,而很多访问都是无用的。为此redis提供了阻塞式访问 BRPOP 和 BLPOP 命令。消费者可以在获取数据时指定如果数据不存在阻塞的时间,如果在时限内获得数据则立即返回,如果超时还没有数据则返回null, 0表示一直阻塞。同时redis还会为所有阻塞的消费者以先后顺序排队。
Set类型
Redis Set 是 String 的无序排列。
SADD
指令把新的元素添加到 set 中。对 set 也可做一些其他的操作,比如测试一个给定的元素是否存在,对不同 set 取交集,并集或差,等等。最大存储数量 2^32-1
基本操作
添加一个或者多个元素:sadd myset a b c d e f g
获取所有元素:smembers myset
统计元素个数:scard myset
随机获取一个元素 srandmember key
随机弹出一个元素 spop myset
移除一个或者多个元素 srem myset d e f
查看元素是否存在 sismember myset a
> sadd myset 1 2 3
(integer) 3
> smembers myset
1. 3
2. 1
3. 2
#检测元素是否存在
> sismember myset 3
(integer) 1
应用场景
示例一:微博点赞
用 like:t1001 来维护 t1001 这条微博的所有点赞用户
点赞了这条微博:sadd like:t1001 u3001
取消点赞:srem like:t1001 u3001
是否点赞:sismember like:t1001 u3001
点赞的所有用户:smembers like:t1001
点赞数:scard like:t1001
示例二:商品打标签
用 tags:i5001 来维护商品所有的标签
sadd tags:i5001 画面清晰细腻
sadd tags:i5001 真彩清晰显示屏
sadd tags:i5001 流畅至极
示例三:商品筛选
获取差集:sdiff set1 set2
获取交集:sinter set1 set2
获取并集:sunion set1 set2
ZSet类型
sorted set,有序的 set,每个元素有个 score;score 相同时,按照 key 的 ASCII 码排序。
基本操作
添加元素:zadd myzset 10 java 20 php 30 ruby 40 cpp 50 python
获取全部元素:zrange myzset 0 -1 withscores || zrevrange myzset 0 -1 withscores
根据分值区间获取元素:zrangebyscore myzset 20 30
移除元素:zrem myzset php cpp
统计元素个数:zcard myzset
获取元素:zsocre myzset java
应用场景
id 为 6001 的新闻点击数加 1:zincrby hotNews:20190926 1 n6001
获取今天点击最多的 15 条:zrevrange hotNews:20190926 0 15 withscores
BitMaps
BitMaps
最大的优点之一是,在存储信息时,它们通常可以极大地节省空间。例如,在用增量用户id表示不同用户的系统中,仅使用512MB内存就可以记住40亿用户的一位信息。通常应用在用户访问统计和在线用户统计这块。
Hyperloglogs
提供了一种不太准确的基数统计方法,比如统计网站的 UV,存在 一定的误差。
Streams
5.0 推出的数据类型。支持多播的可持久化的消息队列,用于实现发布订阅功能,借 鉴了 kafka 的设计。
