





很久没写了, 最近回家直接躺尸了, 所以一直没有更新, 今天抽出一点时间来写点文章, 避免大家以为 loger 消失了 😓
之前我们有提到在处理集群部署的缓存雪崩问题时, 我们可以通过将数据存放在不同的节点来解决这个问题, 今天我们就来详细聊一下这个问题
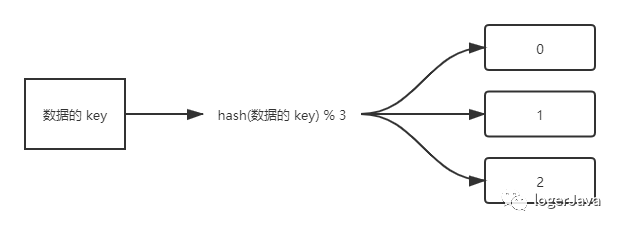
现在我们假设一个业务场景, 现有 3 台缓存服务器, 分别为 0, 1, 2 , 而我们需要做的是存放 3 万条数据到缓存中
很容易的, 我们就会想到将 3 万条数据均匀的分布到 3 台服务器上, 这样能够分摊缓存的压力, 但是怎么做呢 ?
最简单的办法就是没有任何规律的将 3 万条数据平均分配到 3 台服务器上, 这样做的确可以满足场景的需求, 但是仔细想想, 在应用过程中, 我们需要遍历 3 台缓存服务器, 遍历效果很低, 时间也会很长, 如果每次获取数据都要遍历 3 台服务器, 那么这个解决方案我觉得是失败的
大家都有了解过 HashMap, 那么我们回顾一下, HashMap 在计算元素 put 到 Hash 桶有一个 Hash 公式 index = (Length - 1 ) & hash
, 那么想想当前场景是否与 HashMap 存在些许类似呢 ?
我们是否可以将缓存数据的 key 进行 hash, 然后对缓存服务器进行取模操作, 通过取模后的结果决定此数据将缓存到哪台服务器上, 这样是否就可以在 3 台服务器中轻松取到缓存数据了呢 ?
说起来有些抽象, 我们来具体分析一下
因为缓存数据的 key 是不允许重复的, 所以当我们对同一个 key 进行 hash 操作时, 得出的结果是一致的, 什么意思呢 ?
我们现有三台服务器 0, 1, 2 使用 hash 后的结果对 3 进行取模操作, 那么余数肯定是 0, 1, 2 正好与我们的服务器相对应, 也就是说如果计算出来取模结果是 0 那么就存在 0 服务器上, 结果是 1 就存在 1 服务器上
这样做的好处也就显而易见了, 我们在访问这条数据的时候, 只需要再进行一次计算, 就可以得出此数据在哪台服务器上, 直接访问就可以了
我们画个图更清晰的看一下 :
那么这种算法是否存在缺陷呢 ? 我们思考如下场景 :
目前我们有 3 台缓存服务器, 随着业务的增长, 3 台服务器太少了, 我们要增加服务器, 变为 4 台服务器, 这回出现什么问题呢 ?
看一下公式我们就会发现, 原始的数据计算为 hash(key) % 3 , 而增加一台后变为 hash(key) % 4 , 这样计算的结果就发生了改变, 就像 HashMap 扩容之后要进行 rehash 一样, 这种情况无论是增加服务器, 还是减少服务器都无法避免, 而解决这个问题就是我们今天要聊的一致性哈希算法
所谓一致性哈希算法, 其本质也是取模算法, 只不过上面的方法是对服务器的数量取模, 而一致性哈希是对 232 取模
为什么是 232 呢 ? 我们可以将 232 想象成一个圆, 这个圆由 232 组成, 如下图 :
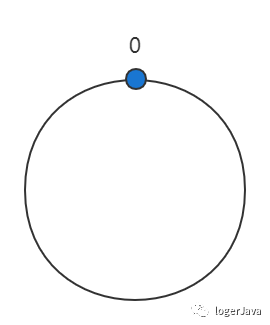
圆的正上方代表 0 , 顺时针依次为 1, 2, 3 ...... 一直到 232 -1 , 这个圆我们成为 hash 环
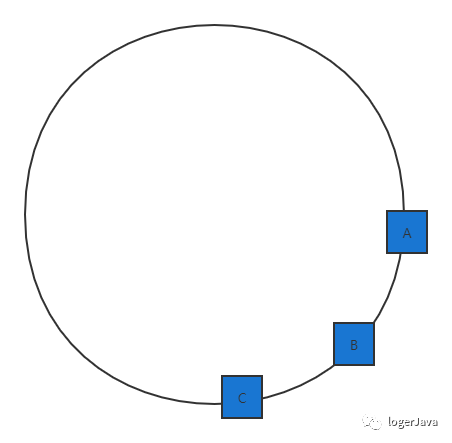
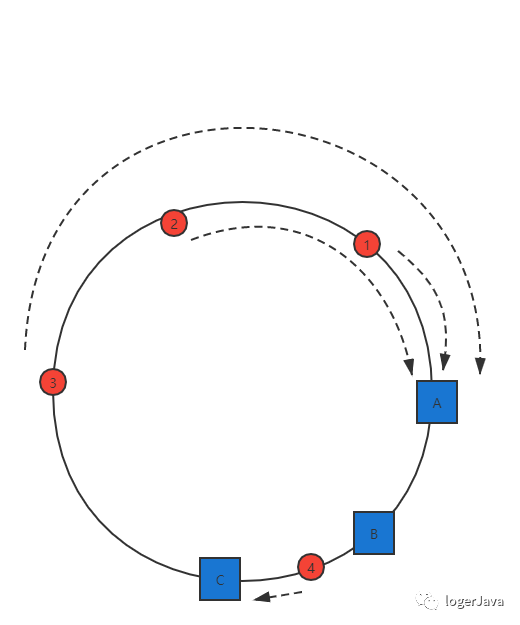
接下来我们可以将各服务器进行 hash, 可以选择服务器的主机名或 IP 作为关键字进行 hash 操作, 这样我们就能确定每台服务器在 hash 环上的位置, 比如有三台服务器 A, B, C 的话, 那么 hash(IP) % 232 出来的 hash 环可能是这样 :
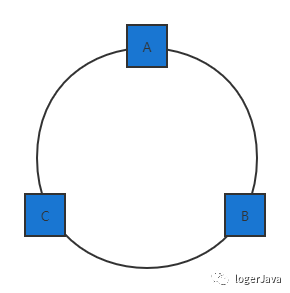
图画的丑了点 ... 不要在意这些细节, 现在我们已经将服务器映射到了 hash 环上, 我们依旧可以用同样的方法将数据映射到 hash 环上, 我们利用同样的公式 hash(key) % 232, 后 hash 环是可能是这样的 :
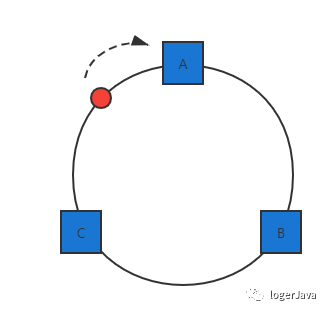
红色的点就代表数据映射到 hash 环上的位置, 那么这个数据到底属于哪台服务器呢 ? 其实 loger 在画的时候已经标记出来了, 就是沿顺时针方向的第一个服务器
一致性哈希算法就是通过这种方式判断一个对象应该被缓存到哪台服务器上的, 从被缓存对象的位置触发, 顺时针方向的第一个服务器就是该数据要缓存的服务器
这样由于被缓存对象与服务器 hash 后的值是固定的,所以,在服务器不变的情况下,数据必定会被缓存到固定的服务器上
在最开始我们提出过, 在服务器发生变化的情况下, 会出现缓存雪崩问题, 使用一致性哈希如何解决这个问题呢 ?
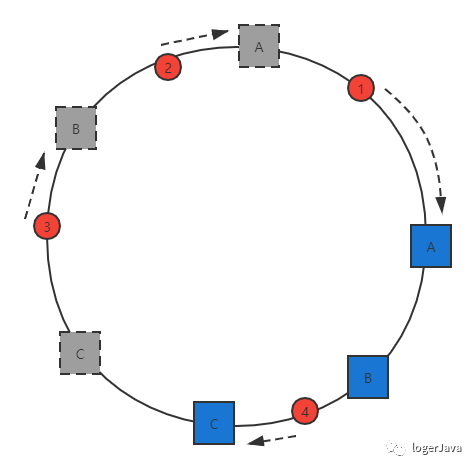
假设 A, B, C 三台服务器,
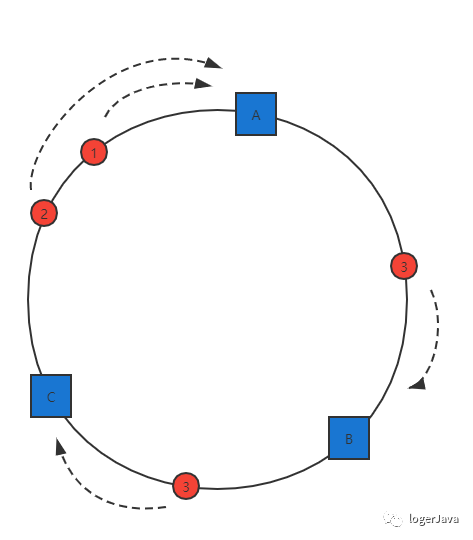
B 服务器出现问题, 我现在想要移除它 :
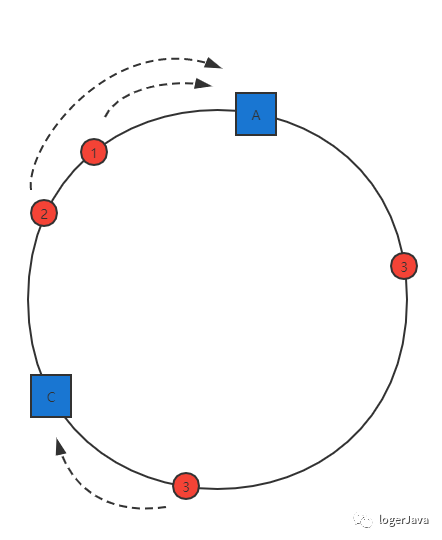
通过上面的图片我们可以看出, 在未移除 B 服务器时, 数据 3 应该被缓存到服务器 B, 移除 B 之后, 数据 3 应该被缓存到服务器 C 中, 也就是说移除服务器 B 之后数据 3 的位置会发生变化
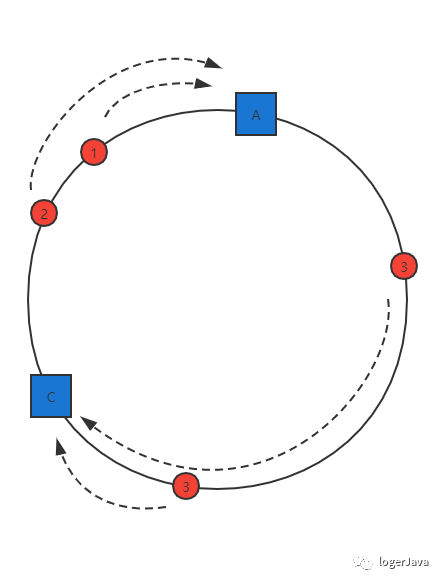
但是其他的数据并没有发生变化, 依旧缓存到原来的服务器中, 如果使用之前的 hash 算法, 服务器数量发生改变时, 所有服务器的所有缓存会在同一时间失效, 而使用一致性哈希算法时, 服务器的数量如果发生改变, 并不是所有缓存都会失效, 而是只有部分缓存会失效, 前端的缓存仍然能分担整个系统的压力, 而不至于所有压力都在同一时间集中到后端服务器上
当然, 上面讲的所有情况都是理想状态下的情况, 显示情况可能会很奇葩
它可能是这样 :
通过计算缓存之后可能就变成了这样
如果此时 A 服务器出现故障, 那么势必会有大量缓存失效, 极端情况下依旧可能出现崩溃情况, 这一问题一致性哈希算法采用 "虚拟节点" 来解决
hash 环倾斜, 这种情况是极其有可能发生的, 当 hash 环倾斜后, 往往会极度不均衡的分布在服务器上, 解决方案就是让服务器尽量均匀的出现在 hash 环上, 这样就可以进行均匀分配, 而我们只有 3 台服务器要怎么办呢 ?
没错就是虚拟节点, 既然没有真实的物理节点, 我们就将现有的物理节点通过虚拟方法复制出来, 加入 hash 环
如图, 是 hash 环倾斜的虚拟节点版本, 这样就能减少 hash 环倾斜带来的问题
抽象派灵魂画师罪恶的一篇文章结束了, 说实话我画的是不是还可以 
关注公众号更多精彩文章等你来看哦
