




前言
本篇文章主要讲解 Redis 的分布式锁, 众所周知, 在进行多线程操作时, 避免同时操作一个共享变量产生数据问题, 我们通常通过锁来解决这个问题, 保证共享变量的正确性, 这里锁的使用范围是在一个进程中
线程是程序执行的最小单位,而进程是操作系统分配资源的最小单位
那么如果多进程操作同一个共享资源, 应该怎么保证它的正确性呢 ?
举一个例子, 我们之前有讲到分布式与微服务, 假设多个进程也就是多个服务, 需要修改 MySQL 中的同一个行记录, 怎么避免操作乱序导致的数据错误呢 ?
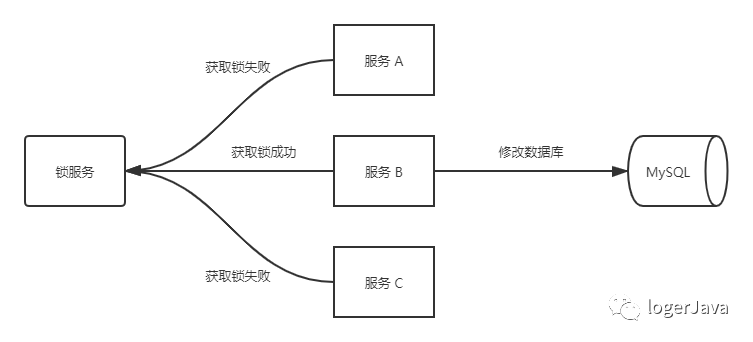
想要实现分布式锁, 我们需要借助一个外部系统, 在进程进行操作之前先去这个系统上申请锁, 而这个锁服务则必须支持互斥锁, 也就是说当两个请求同时进来, 一个阻塞, 另一个返回
业界常用的的分布式锁的实现方式有 Redis 与 Zookeeper, 本篇文章主要讲解 Redis 的分布式锁
初步实现
根据上面的问题, 我们得出结论, 需要在外部系统中进行 "加锁" 操作, 那么在 Redis 中怎么去实现这个操作呢 ? 我们需要使用到 SETNX 命令
SETNX : 如果 key 不存在,才会设置它的值,否则什么也不做
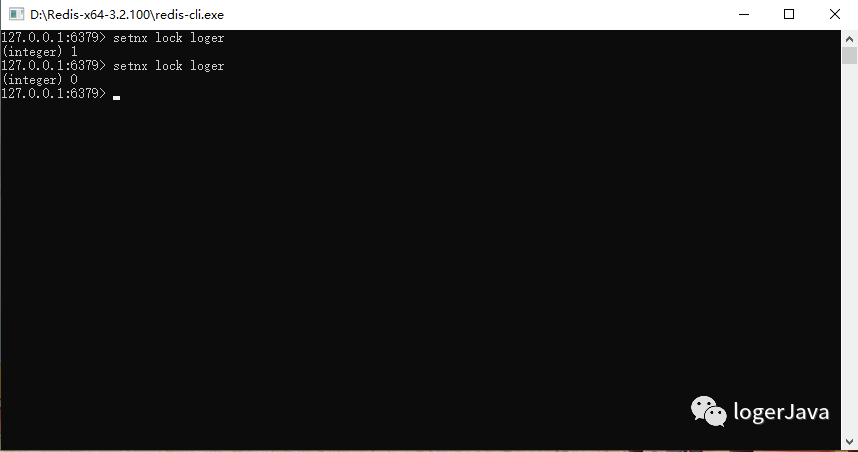
如图所示, 先申请加锁, key 为 lock, value 为 loger, 加锁成功, 在后面操作去申请锁的时候, 因为之前已经存在 lock 了, 所以加锁失败
此时我们就可以通过这个命令来实现操作共享资源前的加锁功能, 流程如下 :
SETNX 申请加锁
加锁成功, 操作 MySQL 共享资源
DEL 释放锁
整个过程非常简单, 但是不要忘记, 涉及到锁, 那么就一定要考虑死锁, 那么上述流程在什么情况下会造成死锁呢 ?
在程序处理逻辑时, 出现异常, 没有释放掉本应被释放的锁
服务直接挂了, 没有释放锁
出现以上情况时, 这个锁就会一直被占用, 无法得到释放, 也就表示其他用户永远无法拿到这个锁
解决死锁问题
联想到在 Java 中解决阻塞时间过长, 或死锁问题, 我们很容易就可以找到答案, 那就是给锁设置过期时间
回到 Redis 这再简单不过了, 通过 EXPIRE 命令就可以设置过期时间
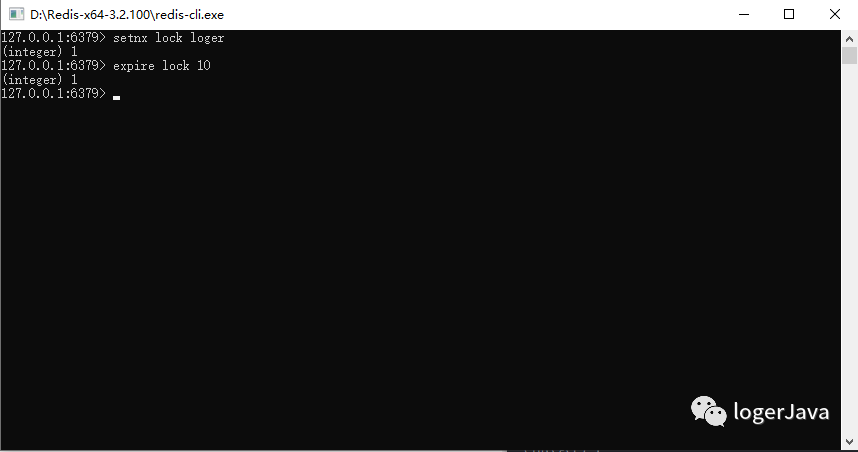
如图, 我们将 key 设置了 10s 的过期时间, 也就是无论操作用户是否有释放锁, 在 10s 后 Redis 都会在自动释放
这个步骤也十分简单, 那么这样就可以了吗 ? 答案明显是否定的, 要不 loger 为啥还要单独写一篇分布式锁的文章呢 (手动狗头)
我们思考下面的问题, 我们知道 Redis 的命令是单线程执行的, 也就是说上图中的两条命令在 Redis 中可以看作 "加锁" 和 "设置过期时间" 两个步骤, 聪明的你肯定已经想到了 loger 要说什么, 如果 "加锁" 成功了, 但是 "设置过期时间" 因为特殊原因没有执行会发生什么 ?
SETNX 申请加锁成功, EXPIRE 设置过期时间因为网络原因, 执行失败
SETNX 申请加锁成功, Redis 掉电了, EXPIRE 没有执行
甭管是啥情况, 总而言之, "加锁" 和 "设置过期时间" 这两个操作并不能保证是原子操作, 没有办法保证要么一起成功, 要么一起失败, 这也就导致了因过期时间无法设置或设置失败, 那么就可以认为死锁问题依旧存在
幸运的 Redis 在 2.6.12 之后扩展了 SET 命令的参数

这样我们就解决了死锁的问题, 那么是否这样就可以认为可以正常使用了呢 ? 是否还存在其他问题 ?
试想如下场景 :
服务 A 加锁成功, 操作共享资源
服务 A 操作时间超过了锁的过期时间, 锁被自动释放
服务 B 加锁成功, 操作共享资源
服务 A 操作完成, 释放锁 (此时释放的是服务 B 的锁)
很明显的可以看出, 此场景下分布式锁存在两个问题 :
锁的过期时间评估不准确, 导致存在提前释放锁的风险
释放别人的锁, 因为在进行锁释放时, 并没有校验这把锁是否属于自己, 所以这种释放锁的方式并不严谨, 会存在释放他人锁的风险
那么这两个问题怎么解决呢 ?
评估锁的过期时间
最简单解决这个问题的办法就是, 延长时间
例如 : 操作共享资源的时间可能最慢需要 20s 才能完成, 那我就设置锁的过期时间为 30s
这种方案确实在一定程度上可以缓解这种问题, 但是要注意, 这仅仅是缓解, 是无法彻底解决问题的, 原因就是, 在拿到锁之后, 去操作共享资源所面临的场景是错综复杂的, 很可能遇到很多奇奇怪怪的情况 (发生异常, 网络超时, 掉电), 而我们这里采取的预估时间, 只能预估一般情况下的时间, 无法精准预测所有突发情况的时间
那么怎么去解决这个问题呢 ?
俗话说的话 : "不要重复造轮子", 在业界已经有了成熟的解决方案, 那就是 Redisson
在 Redisson 中处理这种问题的机制叫做 "看门狗", 其原理就是 : 在加锁时, 设置过期时间, 然后再开启一个守护线程, 定时的去检测锁的失效时间, 如果锁快要过期了, 但是操作共享资源还没有结束, 那么就自动对锁进行续期处理, 重新设置过期时间
锁被别人释放
怎么解决, 很简单, 原来加锁和释放锁都不认识, 那么只要让他们两个认识就可以了
在加锁的时候, 我们设置一个只有自己知道的标识进去, 可以是线程 id , 也可以是 UUID 这种
127.0.0.1:6379> set lock uuid ex 20 nxOK
在释放锁的时候, 我们进行判断, 如果锁为同一个那么就释放, 伪代码如下 :
if (redis.get("lock") == uuid) {redis.del("lock")}
需要注意, 这里面也涉及上面讲到的原子性的问题, "get" 和 "del" 两个操作并不是原子的 :
服务 A 执行 get 命令, 判断锁是自己的
服务 B 执行 set 命令, 获取锁成功 (这种情况概率虽然很小, 但是还是要考虑进去)
服务 A 执行 del 命令, 释放了服务 B 的锁
那么怎么去保证它的原子性呢, 答案是写为 lua 脚本, 来让 Redis 执行
还是之前的思路, 因为 Redis 执行命令是单线程的, 也就表示在执行一个 lua 脚本的时候, 其他命令操作都会等待, 直到上一个命令处理完成, 这样就可以保证两个命令的原子性了
小结
加锁命令 setnx , key 不存在, 才会设置它的值, 否则什么也不做
避免死锁 expire 设置过期时间
保证 setnx 与 expire 的原子性, Redis 2.6.12 扩展了 set 命令
过期时间评估不好, 锁提前过期, 采用守护线程, 自动续期
锁被别人释放, 写入唯一标识, 在操作前线检查标识是否匹配, 再进行释放
集群或哨兵模式下的存在的问题
上面 loger 描述的场景, 都是在单机 Redis 的情况下进行的分析, 而如果带入集群或哨兵场景, 这个分布式锁还会安全吗 ?
试想如下场景 :
服务 A 在 master 上执行 set 命令, 加锁操作成功
此时, master 挂掉了, set 命令并未同步到 slave
slave 被哨兵选举为新的 master, 这个锁就在 master 上丢失了
Redis 的作者提出了一种解决方案, 名为 Redlock
Redlock
我们来看一下 Redis 作者提出的 Redlock 方案, 它存在两个前提 :
不需要部署从库和哨兵实例, 只部署主库
主库要部署多个, 官方推荐至少 5 个
也就是说, 如果想要使用 Redlock 那么至少要部署 5 个 Redis 实例, 还都要是主库, 那么它是如何使用的呢 ?
首先客户端先获取当前时间戳, T1
客户端依次向 5 个实例发起加锁请求, 且每个请求会设置超时时间, 如果一个实例加锁失败, 就立即向下一个 Redis 实例申请加锁
如果客户端半数以上 Redis 实例加锁成功, 则再次获取当前时间戳 T2, 如果 T2 - T1 < 锁的过期时间, 此时认为客户端加锁成功
加锁成功, 就去操作共享资源
加锁失败, 向全部节点发起释放锁的请求 (lua 脚本)
我们来分析一下为什么 Redlock 要这么做 ?
为什么要在多个实例上加锁 ?
容错性, 就算部分实例宕机, 只要剩余实例加锁成功, 那么锁服务依旧可用
为什么大多数加锁成功才算成功 ?
还是容错性, 5 个 Redis 实例就相当于一个分布式系统, 而此时的节点出错就相当于异常节点, 那么只要大多数节点是正常的, 整个系统依旧是可以正常使用的, 类似于分布式系统的 "拜占庭将军问题"
为什么加锁成功后, 要计算加锁的累计耗时 ?
因为操作的是多个节点, 那么所耗费的时间必定要比操作单个实例耗时更久, 再加上网络请求问题, 如丢包, 延迟等, 所以即便大多数节点加锁成功了, 如果加锁的累计耗时已经超过了锁的过期时间, 那么这个锁就没有意义了
为什么要向全部节点发起释放锁请求 ?
是为了清除所有节点上的残留锁, 例如, 客户端在其中一个节点加锁成功, 但是因为网络原因读取响应结果失败, 但实际上加锁已经成功了, 所以释放锁的时候, 不管有没有加锁成功, 都需要对所有节点进行锁的释放
神仙打架
大佬的世界总是和我们相聚遥远, 在 Redlock 提出时, 就遭到了业界著名的分布式系统专家的质疑
专家的名字叫做 Martin, 是英国剑桥大学的一名分布式系统研究员, 他对这个 Redlock 算法模型, 提出了质疑, 并且写了一篇文章, 提出了自己的看法
让我们来看一下大佬的质疑, 下面贴出原文链接 :
https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
Martin 主要阐述了四个观点 :
一, 分布式锁的目的是什么 ?
效率
使用分布式锁的互斥能力,是避免不必要地做同样的两次工作, 如果锁失效, 并不会带来恶性的后果, 例如发了 2 次邮件等, 无伤大雅
正确性
使用锁用来防止并发进程互相干扰, 如果锁失效, 会造成多个数据操作同一条数据, 导致数据不一致, 丢失等一系列问题
二, 锁在分布式系统会遇到的问题
在分布式系统中, 异常场景主要包括三个方面, 简称 NPC :
N : Network Delay, 网络延迟
P : Process Pause, 进程暂停 (GC)
C : Clock Drift, 时钟漂移
Martin 用了一个进程暂停的例子, 指出 Redlock 的安全问题 :
客户端 1 请求锁定节点 A、B、C、D、E
客户端 1 的拿到锁后,进入 GC
所有 Redis 节点上的锁都过期了
客户端 2 获取到了 A、B、C、D、E 上的锁
客户端 1 GC 结束, 认为成功获取锁
客户端 2 也认为获取到了锁, 发生冲突
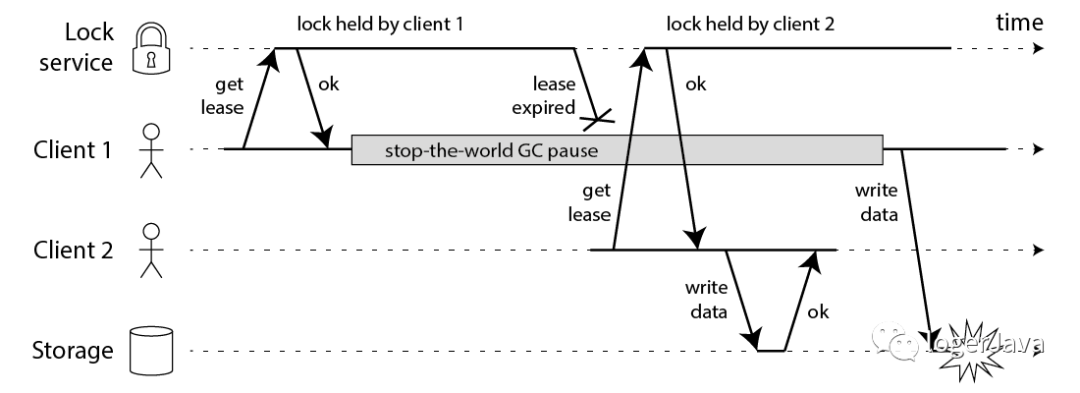
Martin 认为, GC 可能发生在程序的任意时刻, 而且执行时间是不可控的
就算是没有 GC 的编程语言, 在发生 NPC 问题时, 都可能导致 Redlock 出现问题
三, 假设时钟是不合理的
当 Redis 节点时钟发生问题时, 也会导致 Redlock 失效
客户端 1 获取节点 A、B、C 上的锁, 但由于网络问题, 无法访问 D 和 E
节点 C 上的时钟向前跳跃, 导致锁到期
客户端 2 获取节点 C、D、E 上的锁, 由于网络问题, 无法访问 A 和 B
客户端 1 和 2 现在都相信它们持有了锁, 冲突
Martin 觉得, Redlock 必须强依赖多个节点的时钟是保持同步的, 一旦有节点时钟发生错误, 那这个算法模型就失效了
并且提出机器时钟发生错误在实际场景中很有可能发生, 比如 :
系统管理员手动修改了时钟
机器时钟在进行 NTP 同步时, 发生了大的跳跃
四, 提出 fecing token 方案, 保证正确性
所谓 fecing token 方案, 流程如下 :
客户端在获取锁时, 锁服务可以提供一个递增的 token
客户端拿着这个 token 去操作共享资源
共享资源可以根据 token 拒绝后来者的请求
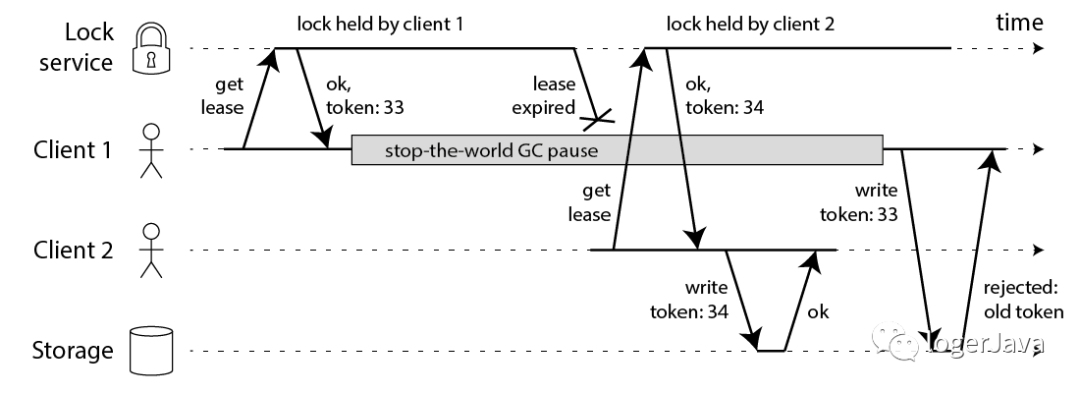
这样一来, 无论 NPC 哪种异常情况发生, 都可以保证分布式锁的安全性, 因为它是建立在异步模型上的
这边 Martin 都亮剑了, 我们来看一下Redis 的作者 Antirez 是怎么回答的, 原文链接如下 :
http://antirez.com/news/101
文章中的主要重点有两个 :
一, 时钟问题
Antirez 表示, Redlock 并不需要完全一致的时钟, 只需要大体一致就可以了
比如, 要计时 5s , 但实际可能记了 4.5s , 或者 5.5s , 有一定误差, 但是是要不超过锁的失效时间就可以
对于时钟修改问题, Antirez 反驳 :
手动修改时钟问题 : 只要不去手动修改时钟就好了, 否则你直接修改 Raft 日志, 那 Raft 也会无法工作 ...
时钟跳跃问题 : 可以通过适当的运维, 保证时钟不会大幅度跳跃
二, 网络延迟, GC 问题
在 Martin 问题中表示 GC 可能发生在任何时间, 所以 Redlock 是不安全的, Antirez 则表示这个假设存在问题, Redlock 实际是安全的
我们可以回顾一下上面的 Redlock 的步骤, 在第三步的时候通过 T2 - T1 与锁的过期时间做了比较, Antirez 表示如果在 1-3 步骤中发生了网络延迟, GC 等问题, 那么在 T2 - T1 的时候是可以检测出来的, 若超过了锁设置的过期时间, 那么加锁就会失败, 之后释放锁的所有节点就好了
并且 Antirez 表示, 如果 Martin 认为, 发生网络延迟、进程 GC 是在步骤三之后, 也就是拿到了锁, 操作共享资源的途中发生了问题, 那么不仅仅是 Redlock 会出现这个文字, 任何其他的锁服务都会出现类似问题, 如 Zookeeper
综上所述, Antirez 的结论 :
同意时钟跳跃对 Redlock 存在影响, 但是认为可以避免
Redlock 设计时, 充份考虑了 NPC 问题, 在步骤三之前出现 NPC 问题, 可以保证正确性, 在步骤三之后发生 NPC 问题, 其他的锁一样也有这个问题
所以捋顺一下, 他俩的情况就是  :
:
Antirez : 快来看快来看, 我整了个 Redlock, 大伙看看我 nb 不 ?
https://redis.io/topics/distlock
Martin : 你这个 Redlock 不行啊, 有点 low
https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
Antirez : 来, 让哥教教你怎么用 !
http://antirez.com/news/101
总结
我们使用分布式锁的目的是为了保证多进程操作同一个共享资源的正确性, 至于采用哪种分布式锁的方式, 要具体情况具体分析, 根据实际业务场景考虑是否需要使用更复杂的分布式锁
在使用 Redlock 时更要考虑 NPC 问题, 时钟偏移实际上很容易出现, 并且无法避免, 一定要考虑好处理方案
参考
深度剖析:Redis分布式锁到底安全吗 ? - Kaito
https://zhuanlan.zhihu.com/p/378797329
结尾
本篇文章到此结束, 关于 Redis 分布式锁的问题, 就写到这里, 如果大家有发现什么问题可以在下方留言
我是 loger, 关注公众号看更多技术分享
