




前言
经过前面一篇文章, 小伙伴的提醒 (实际上根本没人提醒 ...), 我发现需要先来了解一下分布式相关的知识点, 如果没有这方面的知识, 后面很多问题确实难以理解, 这也就有了今天这篇文章, 也算是个小拓展吧
什么是分布式 ?
老规矩, 先来整理概念 : 分布式系统是一组计算机,通过网络相互连接传递消息与通信后并协调它们的行为而形成的系统, 组件之间彼此进行交互以实现一个共同的目标
怎么去理解呢 ? 举一个例子 :
一个成熟的互联网产品公司, 就比如电商公司, 你能想到的常见模块大概包括, 商城的主页, 活动的推广页, 用户信息, 订单信息, 支付, 后台库存管理等等一些功能, 经过一些数据统计分析和项目运行期间的运维情况, 我们会发现几个问题
按照功能模块进行统计访问信息, 某些功能的访问量很低, 有些则很高
单体项目中这些模块分别被部署在一个服务器的 tomcat 上, 而通过服务划分后我们就可以将访问量低的模块放在稍差的服务器, 访问量高的放在好的服务器, 从而实现资源的合理利用
在部署上线的过程中, 我仅仅想要上线新的推广页项目, 但是迫于单体的局限, 整个项目都要停止, 然后发布新版本; 在程序崩溃下同理, 比如在支付模块崩溃的情况下引起宕机问题, 就会导致其他所有功能全部失效
通过服务划分, 模块之间独立, 可以让模块之间独立工作, 不仅便于扩展, 也可以保证其他服务不停止的情况下, 单独上线新功能, 某一服务崩溃的情况下其他服务照常运行
当然分布式不只是如此, 上面只是一个简单的例子, 由此我们可以推导出以下几点优点 :
可靠性
各个模块互相独立, 在一台服务器宕机, 崩溃的情况下, 不会影响其他服务
扩展性
根据需要增加更多的机器
灵活性
很容易的在不影响其他无关服务的情况下, 进行部署与调试
高吞吐量
比如某一个任务在一台机器运行需要 10 小时, 通过分布式合理拆分, 在不同的机器上可能 1 个小时就结束了
开放系统
本地和远程都可以访问到服务
人无完人, 程序亦是, 分布式的缺点 :
故障排除问题
分布式系统排除, 诊断, 测试问题比较麻烦
网络问题
系统吞吐量虽然变大了, 但是响应时间会变长 (网络传输, 高负载, 通信过程信息丢失等)
架构设计复杂
以分布式事务为首的一系列问题
运维复杂度高
运维人员说了 : "本来单体只维护一个就完事了, 你整个分布式, 我得维护一堆" (手动狗头)
学习曲线变大
变成分布式要学的可不是一点半点啊, 老铁们
CAP 理论
概念 : 分布式系统不可能同时满足一致性 (C:Consistency)、可用性 (A:Availability) 和分区容忍性 (P:Partition Tolerance), 最多只能同时满足其中两项
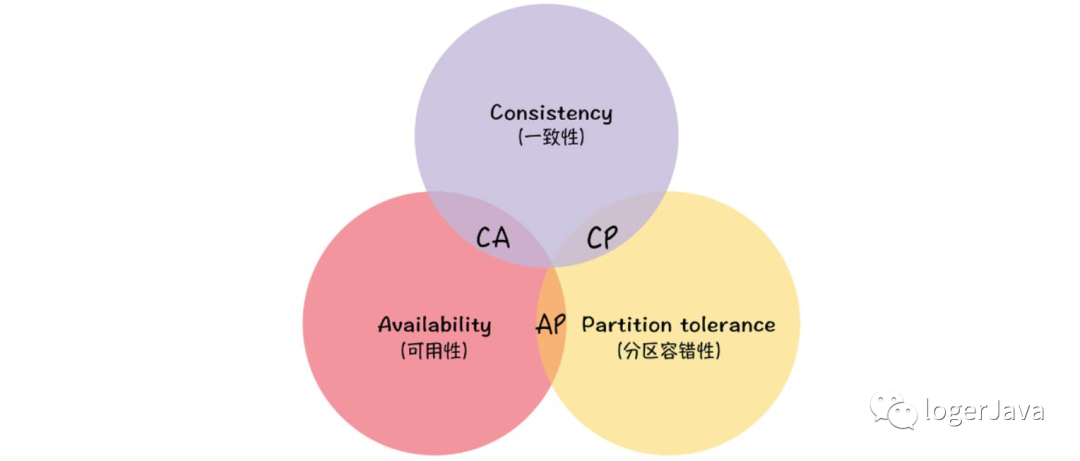
Consistency 一致性
一致性指的是多个数据副本是否能保持一致的特性, 在一致性的条件下, 系统在执行数据更新操作之后能够从一致性状态转移到另一个一致性状态
对系统的一个数据更新成功之后, 若所有用户都能够读取到最新的值, 则认为该系统具有强一致性
Availability 可用性
可用性指分布式系统在面对各种异常时可以提供正常服务的能力, 可以用系统可用时间占总时间的比值来衡量, 4 个 9 的可用性表示系统 99.99% 的时间是可用的
在可用性条件下, 要求系统提供的服务一直处于可用的状态, 对于用户的每一个操作请求总是能够在有限的时间内返回结果
Partition Tolerance 分区容错性
网络分区指分布式系统中的节点被划分为多个区域, 每个区域内部可以通信, 但是区域之间无法通信
在分区容忍性条件下, 分布式系统在遇到任何网络分区故障的时候, 仍然需要能对外提供一致性和可用性的服务, 除非是整个网络环境都发生了故障
在分布式系统中, 分区容错性是必不可少的, 因为我们总是要假设网络是不可靠的, 所以 CAP 理论实际上是要在可用性和一致性之间做权衡
CAP 是无法完全兼顾的, 但并非是只能选择 AP 或 CP, 剩下的就不要了, 就比如其中的一致性, CAP 理论中的 C 代表的是强一致性, 但实际上还有弱一致性和最终一致性
BASE 理论
BASE 理论由 eBay 架构师提出, 是对 CAP 中一致性和可用性权衡的结果, 其核心思想是 : 即使无法做到强一致性, 但每个应用都可以根据自身业务特点, 采用适当的方式来使系统达到最终一致性
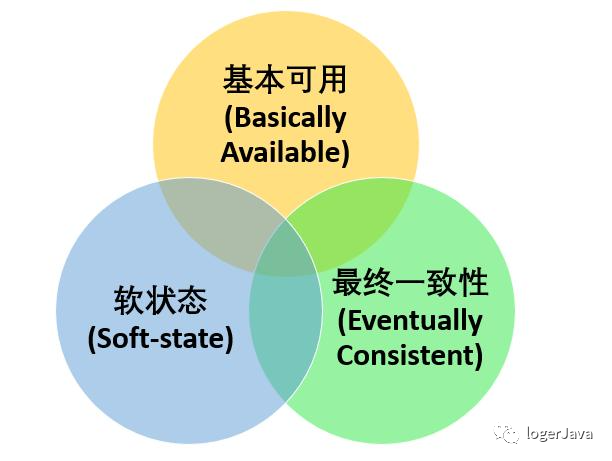
Basically Available 基本可用
指分布式系统在出现故障的时候, 保证核心可用, 允许损失部分可用性
例如, 电商在做促销活动, 为了保证购物系统的稳定性, 部分消费者可能会被引导到一个降级的页面
Soft State 软状态
指允许系统中的数据存在中间状态, 并认为该中间状态不会影响系统整体可用性, 即允许系统不同节点的数据副本之间进行同步的过程存在时延
Eventually Consistent 最终一致性
最终一致性强调的是系统中所有的数据副本, 在经过一段时间的同步后, 最终能达到一致的状态
ACID 要求强一致性, 通常运用在传统的数据库系统上, 而 BASE 要求最终一致性, 通过牺牲强一致性来达到可用性,通常运用在大型分布式系统中
在实际的分布式场景中, 不同业务单元和组件对一致性的要求是不同的, 因此 ACID 和 BASE 往往会结合在一起使用
结尾
其实本来是没有这篇文章的, 但是 loger 为了避免之后讲到一些技术时设计到分布式问题, 大家一头雾水所以先凑了一篇类似简介的文章
关于分布式系统其实有很多细节以及一些有趣的问题, 比如分布式事务的解决方案, 拜占庭将军问题, Paxos 算法, Raft 算法等, 感兴趣的话大家可以自行了解一下, 就不做探讨了
后面我们还是会回到原来的进度, 继续整理 Redis 方面的知识体系, 以及剩下没写的 MySQL 调优问题
我是 loger, 关注公众号, 更多知识分享等你来看
