




一、函数介绍
GROUPING_ID(expr) 函数表示参数是否参与分组的向量值(分组统计语法中,分组组
合指其中的单列或多列表达式的某种分组情况),返回数值的二进制位表示对应参数列是否
为分组列。当参与分组时,参数位为 0 ;否则为 1 。
例如,GROUPING_ID(c1,c2) 返回值为 2 ,对应二进制数值为 10 ,表示 c1 列未参与, c2 列参与分组。
注:该文章中的举例部分 数据库版本为:GBase8sV8.8_3.5.1
二、函数语法
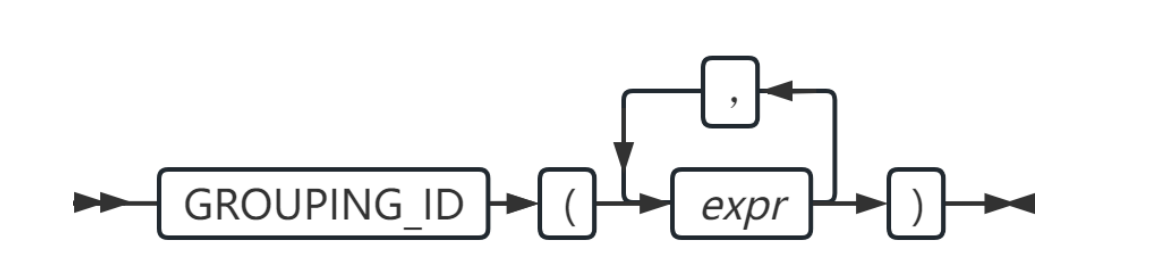
返回值计算规则如下:
GROUPING_ID(expr1,expr2,……)中的每个参数 expr 对应一个列,当该参数对
应的列为分组列时,该参数位的值为 0 ,否则为 1 。最后将所有参数位的值串联在一起,
组成一个 0 和 1 的二进制数,再将该二进制数转换为一个十进制数,即为 GROUPING_ID
的返回值
三、限制
1.GROUPING_ID 函数的返回值类型为整型数值。
2.GROUPING_ID 函数的参数支持多个。参数限制和 GROUP BY 参数限制保持一致。
3. GROUPING_ID 函数的参数 expr 必须是 GROUP BY 子句中的表达式的子集。
4. GROUPING_ID 函数的参数 expr 不支持为 NULL 。
5. GROUPING_ID 作为分组函数,不能出现在 WHERE 或连接条件中。
6. 当在视图中使用 SELECT GROUPING_ID () 时,必须使用别名,否则报错。
7. 使用 HAVING GROUPING_ID () 时,不可用别名,需直接使用函数表达式。
四、举例
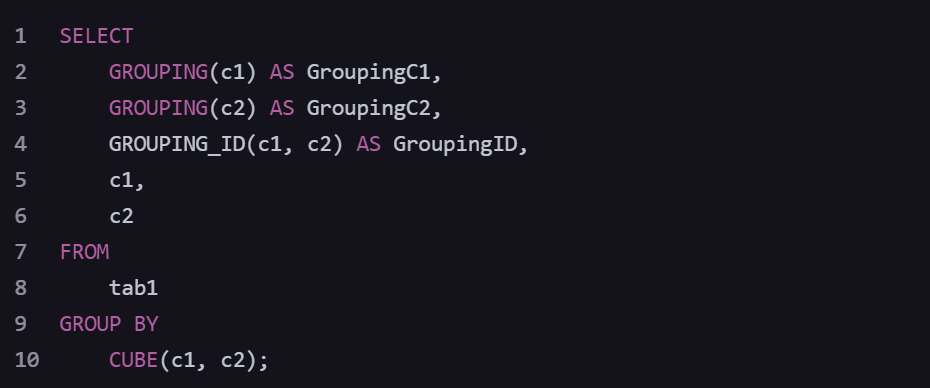
1.例如,表 tab 1 表结构如下:

对表 tab1 的 c1、c2 列进行 CUBE 分组,统计分组组合包括 (c1,c2),(c1),(c2),全
空 四种分组组合。 使用 GROUPING_ID(c1,c2) 函数返回 c1,c2 列是否参与分组的向量值。
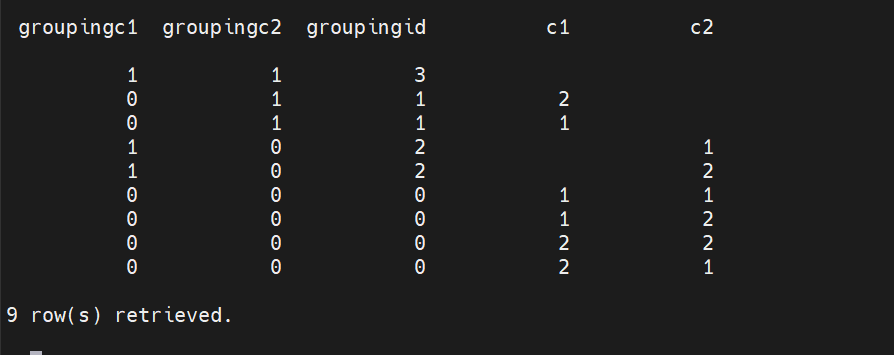
结果如下:
五、结果解释:
1.以下是 CUBE(c1, c2) 可能的输出组合(假设 c1 和 c2 是维度列,而实际选择的列(如 c1, c2)在 SELECT 语句中明确列出):
(c1, c2) 的所有唯一组合(非聚合维度)
(c1, NULL) 的每个 c1 的汇总(c2 被视为 NULL,表示在 c1 维度上的汇总)
(NULL, c2) 的每个 c2 的汇总(c1 被视为 NULL,表示在 c2 维度上的汇总)
(NULL, NULL) 的全表汇总
2.在 SELECT 语句中,GROUPING(c1) 和 GROUPING(c2) 会指示在特定聚合行中,c1 和 c2 是否为 NULL(即,它们是否参与了当前行的聚合)。如果列参与了聚合(即,它不是 NULL),则 GROUPING 函数返回 0;如果列被设置为 NULL 以进行汇总(例如,在 (c1, NULL) 或 (NULL, c2) 组合中),则 GROUPING 函数返回 1。
3.GROUPING_ID 函数为当前的聚合行返回一个唯一的位掩码,其中每一位对应于 GROUPING 函数的一个参数。如果相应的列在聚合中被视为 NULL(即用于汇总),则该位被设置为 1;否则,它被设置为 0。对于两个参数的 GROUPING_ID(c1, c2),返回的整数值可以是一个 0 到 3 的数字,其中:
0 表示 (c1, c2) 是具体的值(非聚合)
1 表示 (c1, NULL)(仅 c1 聚合)
2 表示 (NULL, c2)(仅 c2 聚合)
3 表示 (NULL, NULL)(全表聚合)
