




向量数据库|第2期|pgvectorscale
大家都听说过pgvector,一个PostgreSQL存储和查询向量的扩展,是PG AI生态当之无愧的最受推崇的工具之一。pgvector向PG中添加了vector类型,以及各种搜索操作符和索引,使其拥有vectors和metadata的完整数据库能力。但他的HNSW索引有两个问题:
1)需要将整个索引都放到内存,否则会变慢。索引成为整个应用的唯一瓶颈
2)基于HNSW索引的search不能以一种合理的方式充分利用预过滤。利用HNSW查询向量首先需要进行索引查询、获取结果,然后才能进行过滤。更为糟糕的是,HNSW仅能从search中返回最大结果集(大多数情况下小于 1,000,否则会变得很慢)。假设你有一个多租户应用,维护数千支teams,每一个有数千个文本(或向量)。针对你的查询请求,HNSW会查询所有vectors,返回一个有限数量的结果集,然后在此结果集上执行过滤。如果最佳结果位于不相干team中时,无法保证为你的team找到任何向量。
pgvectorscale(Rust语言开发的)添加了基于磁盘的流索引,可以解决这两个问题。准确的说,它添加了微软DiskANN论文中提到的StreamingDiskANN,一种图结构的专门用于过滤的近邻查询的索引。
pgvectorscale的三大特性:支持DiskANN索引(算法)、支持streaming post-filtering、支持SBQ(statistical binary quantization)。
1、DiskANN算法
DiskANN算法和HNSW类似也是一种基于图的查询算法。基于图的算法有一个问题:查找一个距离start position非常远的点非常耗时,因为它需要大量hops。
HNSW通过引入一个分层系统(顶层仅有“long-range”边,即高速公路边,帮助快速进入正确的区域,并且有指向低层节点的指针允许以更细粒度的遍历图)。该方法虽然解决了Long-range问题,但通过分层系统引入了更多的indirection,需要更多随机访问,从而需要将该图放到RAM中以获得更好的性能。
与此相反,DiskANN使用单层图,在图构建时通过引用远距离的邻居边来解决long-range问题。单层构建简化了算法,并且在查询时减少了不必要的随机访问,使得SSD更加高效。
相对于HNSW来说,它从一个随机图开始,他的核心是一个名为Vamana的图ANN算法,即构建图的算法为:
1)随机初始化一个出度为R的图G:每个节点随机选择R数量的邻居节点并建立连接
2)计算图G的导航点,也就是近似质心
3)以距离全局质心最近的点作为搜索算法起始节点,为每个点重新选择近邻
4)基于步骤1初始化的随机近邻图和步骤3确定的起始点,对每个点做GreedySearch即贪婪搜索,将搜索路径上的所有点都放到近邻集。这里需要跳到1.1和1.2部分了解如何选择候选邻居集。
5)执行步骤3)和4)两遍,第一遍α=1,第二遍α>=1。
其实是,在随机图基础上,从质心开始遍历两遍重新生成新图。
如何体现Disk?
对于索引构建的问题,DiskANN 在构建索引时通过 k-means 聚类的方式将整个数据集划分成 k 个簇,然后将每个节点分配到最近的 l 个簇中,每个簇分别构建 Vamana 图,这样就可以在内存中进行索引的构建,最后通过简单的边并集将所有不同的图合并为一个图。
1.1如何选择近邻?
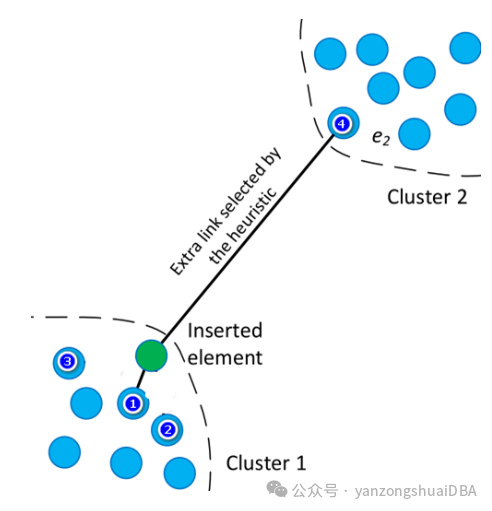
1.2如何调整,再增加一些长边?

2、streaming post-filtering

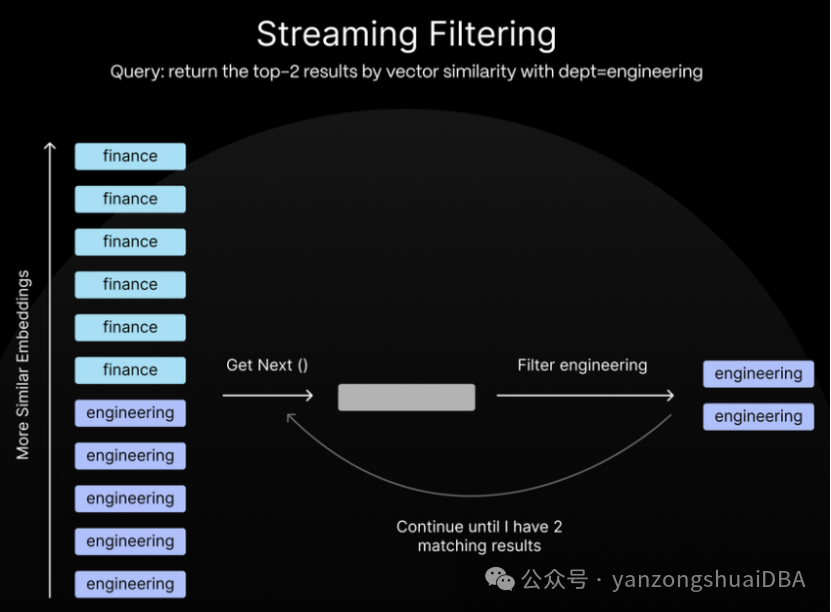
3、新的量化算法:statistical binary quantization
4、参考
https://www.timescale.com/blog/how-we-made-postgresql-as-fast-as-pinecone-for-vector-data/
https://www.timescale.com/blog/how-we-built-a-content-recommendation-system-with-pgai-and-pgvectorscale/
https://github.com/timescale/pgvectorscale/?ref=timescale.com
https://proceedings.neurips.cc/paper_files/paper/2019/file/09853c7fb1d3f8ee67a61b6bf4a7f8e6-Paper.pdf?ref=timescale.com
https://mp.weixin.qq.com/s?__biz=MzkxOTQwNzU0Ng==&mid=2247486484&idx=1&sn=f254f2adbe4d3d3186fd04fdf3e4de5b&chksm=c1a3d2c1f6d45bd758dac5380ffbff2ad97a8ae7f435b4265feadd3fe0fe09c0a43cfc6ca136#rd
https://blog.csdn.net/whenever5225/article/details/106863674
https://dl.acm.org/doi/pdf/10.5555/3454287.3455520
https://mp.weixin.qq.com/s/ynXT945swVVJDFk8UJ-xIQ
