Knowledge Graph-Enhanced Large Language Models via Path Selection
论文地址: https://arxiv.org/pdf/2406.13862
论文概述
近年来,大型语言模型(LLMs)在各类自然语言处理任务中表现出色,展现出强大的推理能力。然而,在需要超出训练语料范围的新知识的场景中,LLMs 往往会生成事实不准确的内容,这一现象被称为“幻觉问题”。为了提高生成内容的真实性,将知识图谱(KGs)中的外部知识融入 LLM 成为一种有效的策略。然而,现有方法大多依赖 LLM 自身来提取知识图谱中的知识,这种方式的灵活性较低,因为 LLM 只能对某个知识(如知识图谱中的路径)是否应被使用做出简单的二元判断。此外,LLM 倾向于仅选择与输入文本直接相关的知识,而忽略了潜在有用的间接语义知识,从而限制了知识增强的效果。为解决这些问题,本文提出了一种名为 KELP(Knowledge Graph-Enhanced Large Language Models via Path Selection)的新方法,旨在通过知识图谱(Knowledge Graph, KG)增强大语言模型(LLM)的生成准确性。KELP 的设计目的是解决 LLM 生成内容的事实性错误(即幻觉问题),并通过引入与输入问题相关的知识路径作为上下文,改善生成的真实性和准确性。KELP 包括知识路径提取、样本编码和精细化路径选择三个主要阶段,使得模型能够灵活地引入直接和间接相关的知识,提高答案的可靠性。
核心内容
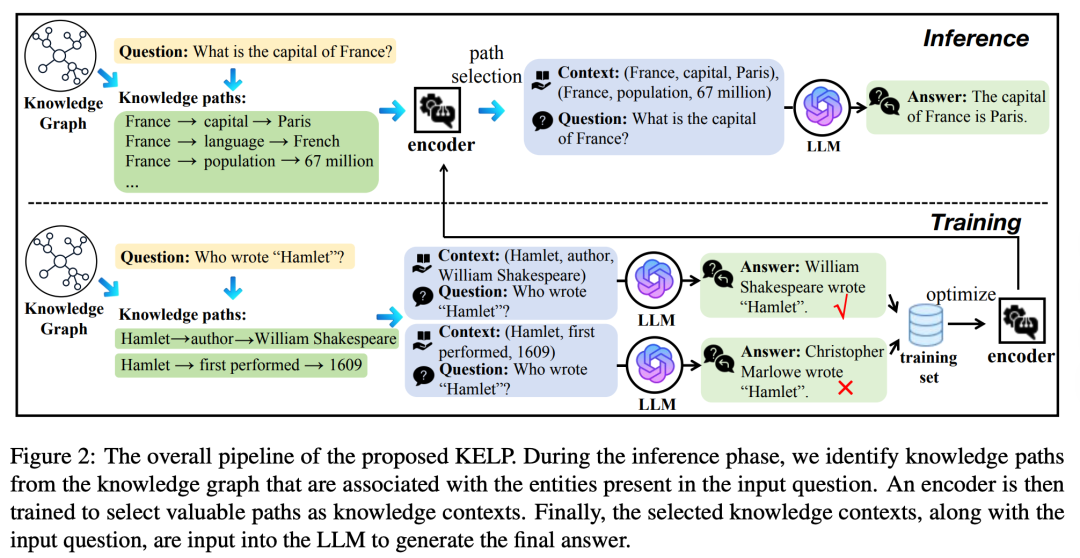
KELP 方法的核心流程可以分为以下三个阶段:知识路径提取、样本编码和精细化路径选择,如下图所示。
1. 知识路径提取
在第一步中,KELP 从知识图谱(KG)中提取与输入问题相关的知识路径。具体来说,模型首先识别问题中的实体,例如,针对问题 “What is the capital of France?”,识别出实体 “France”。然后,KELP 从知识图谱中提取与该实体相关的 1-hop 和 2-hop 知识路径(即经过一个或两个关系的路径),作为候选知识路径。这些路径包含与 “France” 相关的不同信息,例如 “France → capital → Paris”(法国的首都是巴黎)、“France → language → French”(法国的官方语言是法语)等。这些路径被视为可能对回答问题有帮助的候选知识。
2. 样本编码
在样本编码阶段,KELP 使用一个经过训练的编码器,将问题和知识路径映射到一个潜在的语义空间中,以计算它们之间的相似性分数。编码器的目的是通过学习,使其能够识别与输入问题潜在相关的知识路径,而不仅仅是直接相关的路径。以 “Who wrote ‘Hamlet’?” 为例,KELP 会从知识图谱中提取与 “Hamlet” 相关的路径,例如 “Hamlet → author → William Shakespeare”(作者是威廉·莎士比亚)和 “Hamlet → first performed → 1609”(首次上演于1609年)。编码器会计算这些路径与问题之间的语义相似性,并将它们赋予不同的相似性分数,以判断每条路径对回答问题的潜在影响力。
3. 精细化路径选择
在路径选择阶段,KELP 使用相似性分数和覆盖规则,对候选知识路径进行进一步筛选。模型设定两个覆盖规则,以保证所选择的路径既具有代表性,又能够提供多样化的信息。首先,对于共享相同三元组的路径,KELP 会基于相似性分数选择得分最高的路径,从而避免冗余信息的重复引入。其次,为了保证选择的路径多样性,KELP 会对不同的三元组设定数量限制,以避免相似内容的过度覆盖。最后,模型设置了一个相似性阈值,确保所选路径与输入问题的相似性足够高,以避免低相关性的路径对生成答案产生负面影响。在推理阶段(如图2的上半部分所示),模型在经过编码器筛选后,选择出最合适的路径,并将它们与问题一起作为上下文输入到大语言模型(LLM),生成最终答案。例如,对于 “What is the capital of France?” 这一问题,模型选择包含“France、capital、Paris”这一路径的上下文,最终生成答案“法国的首都是巴黎”。在训练阶段(如图2的下半部分所示),KELP 会通过对比正确和错误答案的生成情况,来优化编码器的参数。模型生成一个训练集,其中包含正样本(正确答案)和负样本(错误答案),并通过优化使编码器能够更准确地筛选出有助于生成正确答案的路径。例如,针对 “Who wrote ‘Hamlet’?” 这个问题,如果模型选择的路径导致生成的答案是“威廉·莎士比亚写了《哈姆雷特》”,则这条路径被视为正样本;如果答案错误(例如“克里斯托弗·马洛写了《哈姆雷特》”),则该路径被视为负样本。这种训练方式确保了编码器在未来推理阶段可以更好地选择相关路径。综上所述,KELP 通过知识路径提取、样本编码和精细化路径选择三个步骤,将知识图谱中潜在有用的知识灵活地引入大语言模型的上下文中,从而提高生成的答案的事实性和准确性。