





近日,第七届数字中国建设峰会在福州开幕,峰会聚焦数字经济与数字中国建设的新进展和新技术。峰会期间,浪潮云岳向量数据库重磅发布,这是一款高性能、高可用、低延迟的分布式智能原生数据库,可满足政企用户大模型场景对海量多模态数据存储和高效高维向量数据、全文数据融合检索的需求。

重新定义数据库存储与检索的未来
作为浪潮云推出的最新云原生数据库产品,浪潮云岳向量数据库结合了前沿的分布式技术和智能算法,提供卓越的多维向量数据、结构化数据、全文数据的存储和融合检索能力,并支持千亿级向量规模、百万级QPS及毫秒级查询延迟,确保在高并发场景下依然可以提供稳定可靠的性能。
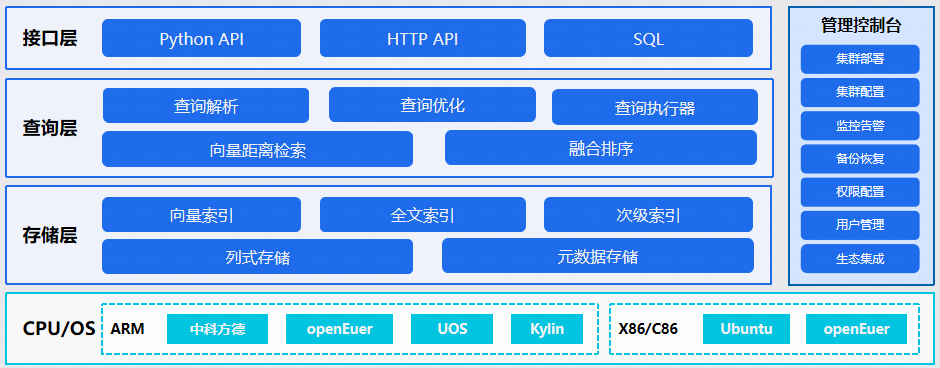
浪潮云岳向量数据库核心特性包括以下三个方面。
多模数据支持:浪潮云岳向量数据库支持向量、张量、结构化、全文数据等多种数据类型的存储和检索,满足多样化的数据需求;
三路召回与融合排序:支持稀疏向量、稠密向量和全文的三路召回和融合排序,提供精准的检索结果;
高并发、低延迟、高可靠:在高并发的查询环境下依然能够保持低延迟和高可靠性,保障系统的稳定运行。
浪潮云岳向量数据库专为大模型和检索增强生成(RAG)系统提供数据底座,解决了企业在构建和管理知识库过程中面临的诸多挑战,能够有效应对纯向量召回不准确、无法满足多样化查询等痛点问题,同时简化系统运维,提升查询精准性。
其主要应用场景包括以下四个方面。
检索增强生成(RAG):在私域知识构建知识库时,解决大模型记忆、幻觉、新鲜度和数据安全等问题,有效扩展大模型的时间与空间边界;
大模型上下文记忆:保持大模型与用户的会话信息,检索相关性高的上下文,生成提示词配合大模型问答,降低幻觉情况发生;
推荐系统:根据用户行为和需求推荐相关信息或产品,提升用户体验;
多模检索:针对文本、图片、音频、视频等多模态数据进行智能化检索,满足多样化的信息需求。
随着大模型时代的到来,作为浪潮海若大模型的坚实数据底座,浪潮云岳向量数据库应运而生,它的诞生标志着浪潮云在向量数据存储与检索领域迈出了重要一步,可以有效帮助大模型突破时间和空间限制,加速大模型在行业场景上的落地,与大模型共建新质生产力,发挥澎湃动能,为数字经济发展添砖加瓦。

