今天为大家分享一篇ICML 2024年的向量检索论文: Residual Quantization with Implicit Neural Codebooks
论文作者来自META FAIR实验室和荷兰TU/e大学。 论文地址:https://arxiv.org/pdf/2401.14732
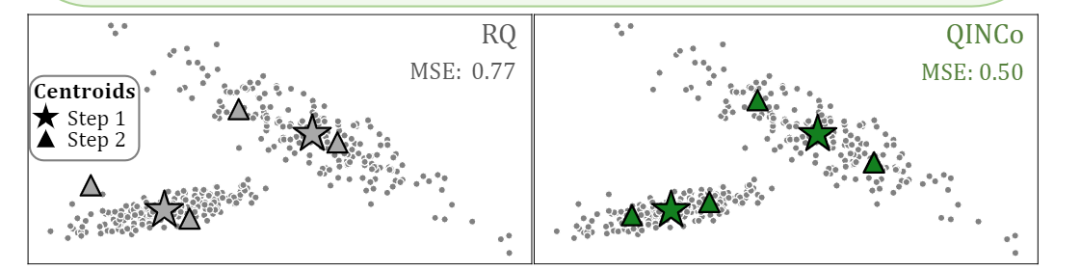
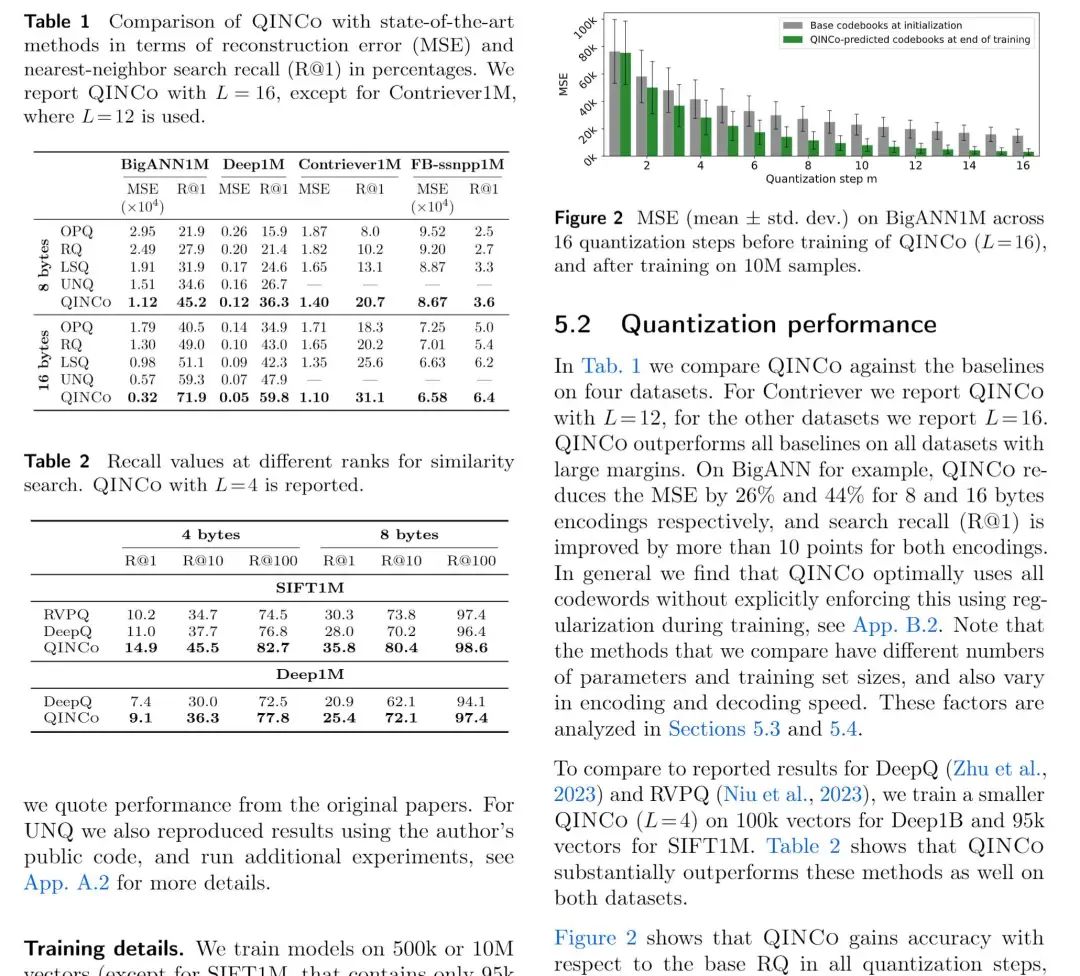
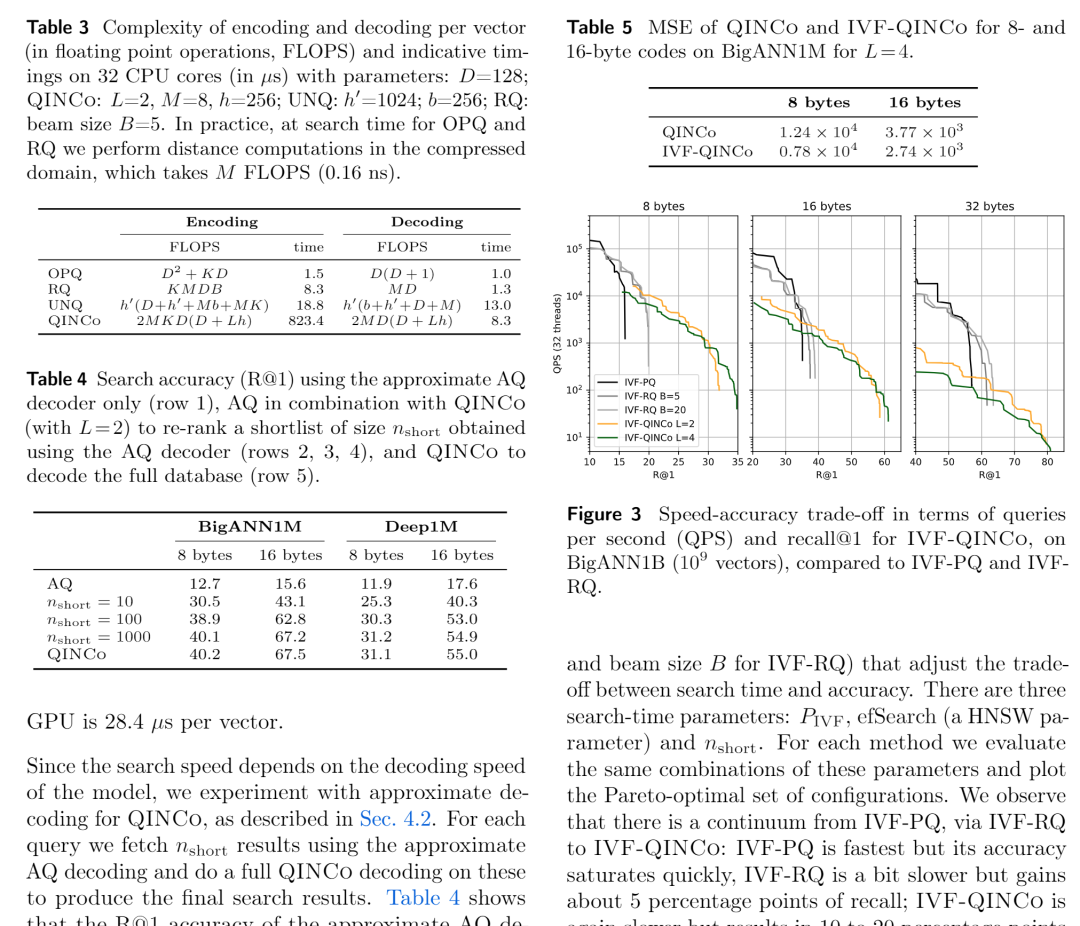
代码地址:https://github.com/facebookresearch/Qinco 论文概述 向量量化技术可以用于压缩高维向量数据,以牺牲部分精度为代价显著降低向量的存储消耗,并结合向量索引的数据结构提供快速相似性搜索的能力。 其中残差量化指的是将一次量化后的误差向量再次进行量化,并通过量化向量+量化残差向量重建原始向量,降低精度损失。依此类推,将误差向量的量化误差进一步量化,就形成了多级残差量化。 在本论文中,作者指出由于各级量化相互独立,互相之间的数据分布信息没有得到传递,影响了量化的效果。如下图,在残差量化(RQ)中,二级中心相对于一级中心的偏移是固定的,这与实际数据分布不符。 针对这一问题,本文训练神经网络在每一级的残差量化中动态输出码本,显著降低量化误差。同时可以结合IVF索引,提供在大规模数据上相似性检索的能力。 关键算法 隐式神经码本 由于在每个上级聚类中单独训练码本会产生指数级代价,因此本文采用的策略是使用隐式码本,即没有具体的码本,而是使用神经网络来生成码本。 具体来说,残差量化的每一层中,均有一个神经网络负责生成码本,网络接受一个目前重构的向量和一个基础码本(可以由普通RQ训练而成)作为输入,输出一个新的码本。各级网络串联而成,因此前一级的训练误差影响后一级的训练效果。另外,基础码本作为初始化参数保证网络训练可以从较低的损失开始。 网络结构上,QINCO的每级首先引入仿射变换,然后接入L个残差块,每个残差块包含两层。首层码本由基础码本的第一级直接确定。 向量编解码与模型训练 编码与普通RQ区别不大,只有码本是通过每层的神经网络输出。解码由于需要每层的重建向量作为输入,所以仍然只能串行逐层相加。模型损失函数方面,使用残差向量与每层最近码字的MSE的加和。 与IVF索引的结合 QINCO可以很自然与IVF索引结合,在首层IVF后,第一层的重建向量即为IVF聚类中心。由于QINCO没有固定码本,无法利用现有技术中的快速距离计算技术,所以作者设计了一个近似的decoder,固定每层的码本。在索引实现上,QINCO为第一层的IVF聚类中心建了一个HNSW,实现聚类的快速扫描。使用生成的固定码本做近似距离计算,最后在少量Candidates上使用完整的QINCO解码计算距离,进行精排。 精彩段落 <<< 左右滑动见更多 >>>
总结 本文提出针对多层残差量化框架的隐式码本学习技术,为多层自适应码本打开了一个新思路。QINCO显著降低了量化损失,提高了召回率。然而在编解码的速度上大幅度慢于传统方法,在实际场景中应用略为受限。 延伸阅读 [1] CVPR'16 多级残差量化:Efficient Indexing of Billion-Scale Datasets of Deep Descriptors
(https://openaccess.thecvf.com/content_cvpr_2016/papers/Babenko_Efficient_Indexing_of_CVPR_2016_paper.pdf)
[2] ICCV'19 基于向量变换的神经量化编码: Unsupervised neural quan-tization for compressed-domain similarity searc
(https://openaccess.thecvf.com/content_ICCV_2019/papers/Morozov_Unsupervised_Neural_Quantization_for_Compressed-Domain_Similarity_Search_ICCV_2019_paper.pdf)
编者简介 王泽宇
复旦大学与巴黎西岱大学联合培养博士生,研究领域为高维数据(向量、序列等)管理和分析。以第一作者在SIGMOD,VLDB,VLDBJ,TKDE等数据库领域会议/期刊发表多篇论文,并担任审稿人。
个人主页:https://zeyuwang.top/
谷歌学术:https://scholar.google.com.hk/citations?hl=zh-CN&user=XXGhABIAAAAJ
技术博客:https://www.jianshu.com/u/d015902c6d09