




概述
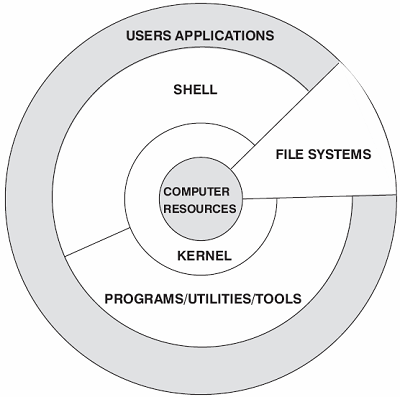
数据库软件的运行离不开操作系统内核的支撑,它依赖于操作系统提供的各种资源和服务。操作系统离不开硬件的支撑,否则所有的资源分配和调度都无法被响应。数据库软件的运行同样离不开文件系统的支撑,文件系统为数据库软件提供了数据存储的基础。数据库中的数据通常以文件的形式存储在磁盘上,文件系统负责管理这些文件的存储、读取和写入操作。
本文将围绕硬件、文件系统、操作系统内核等角度来优化数据库运行的支撑体系,在系统层面上提高数据库软件的性能。
硬件性能
这里主要讨论应该选择什么样的处理器、内存、硬盘和网卡,以及它们的性能基准。
生产 CPU 最具有代表性的当属英特尔公司,同时也是目前市面上使用最多的,但国产的鲲鹏、海光、龙芯必定是未来的采购趋势(信创)。每个厂家在开发 CPU 时会设计多种不同的架构来适应不同的需求,主要基于两种指令集:复杂指令集 CISC 和精简指令集 RISC ,比如 x86 就是复杂指令集的代表, arm 就是简单指令集的代表。随着技术的发展,两种架构的 CPU 都在性能和稳定性方面经过了大量的验证和优化,所以没有谁好谁坏一说,不过许多企业级应用和成熟的服务器环境通常采用 x86 架构,其性能为:
- 延迟:1~15ns
- 带宽:20~60GB
内存类型目前使用最多的是DDR系列:DDR1、DDR2、DDR3、DDR4。DDR4性能最优:
- 延迟:30~100ns
- 带宽:2~12GB
硬盘按照存储介质来区分,可分为:HDD机械硬盘和SSD固态硬盘,从综合性能来看,SSD优于HDD,具体的性能指标:
- IOPS:读几万次/s,写几千次/s
- 响应时间:即1/IOPS计算得到,读不到0.1ms,写不到1ms
- 吞吐率:读250Mb/s,写150Mb/s
网卡方面主要关注带宽,生产上一般使用万兆网卡。
文件系统优化
首先是文件系统的选择,一般使用较多的是 ext4 或者 xfs 文件系统,他们都有各自的优势,适用于不同的使用场景。ext4 优势在于成熟稳定、向下兼容、易于维护,在标准的桌面和服务器环境中,ext4 是一个不错的选择;而 xfs 凭其高性能、日志追踪、大容量支持等优势在需要处理大型文件和高性能工作负载的情况下显得更为适合。
文件系统直接对应磁盘,所以在 IO 层面具有一定的优化空间,如:
- SSD的 Trim 垃圾擦除(挂载时添加discard)
- 关闭 atime 跳过记录访问时间
mount -o discard,noatime /dev/sda /
# fstab配置自动挂载
/dev/sda / xfs discard,noatime,errors=remount-ro 0 1
- 预读
blockdev --setra 8192 /dev/sda
echo 'blockdev --setra 8192 /dev/sda' >> /etc/rc.local
# 这里的4096代表扇区的数量,扇区大小一般为512字节,故代表4MB的预读,
# 查看设置:blockdev --getra /dev/sda
- IO调度器
echo deadline > /sys/block/sda/queue/scheduler
echo 'echo deadline > /sys/block/sda/queue/scheduler' >> /etc/rc.local
内核优化
- 虚拟内存
# 内存耗尽才使用swap
echo 'vm.swappiness=0' >> /etc/sysctl.conf
sysctl -p
# 禁用swap
swapoff -a
echo 'swapoff -a' >> /etc/rc.local
使用虚拟内存可能会产生性能抖动,所以一般建议禁用或者最后使用。
- 内存预分配
echo 'vm.overcommit_memory=2' >> /etc/sysctl.conf
echo 'vm.overcommit_ratio=85' >> /etc/sysctl.conf
sysctl -p
这样设置可以在内存紧张(内存使用超过85%)时关闭overcommit,降低oom的风险
- 缓存刷脏优化
echo 'vm.dirty_background_ratio=5' >> /etc/sysctl.conf
echo 'vm.dirty_ratio=10' >> /etc/sysctl.conf
sysctl -p
- 数据库内存分配优化
shared_buffers:数据缓冲区,设置为主机内存的25%左右
wal_buffers:xlog缓冲区,一般设置为4MB~16MB即可,可适当调大
work_mem:用于hash、排序、连接等操作,一般设置为几十MB即可,可根据并发适当调大
maintence_work_mem:用于vacuum、create index等维护操作,建议会话级调大
autovacuum_work_mem:autovacuum为每个进程分配的内存
temp_buffers:临时表的内存,保持默认8M即可,可适当调大
- 开启大页
查看操作系统支持的大页规格(一般是2M和1G的规格):
ls /sys/kernel/mm/hugepages/
查看当前设置的大页规格:
cat /proc/meminfo | grep Hugepagesize
根据 shared_buffers ➗ 大页规格 设定需要的大页数量:
echo 'vm.nr_hugepages=xx' >> /etc/sysctl.conf
sysctl -p
数据库配置参数启动大页
huge_pages=on
- shmmax、shmall调整
shmmax为主机物理内存的大小,单位是字节
shmall为系统中可以使用的共享内存页面总数,单位是page(4k),一般可以通过shmmax➗4096得到
demo:32GB的主机内存
shmmax:32 * 1024 * 1024 * 1024 = 34359738368
shmall:34359738368 ÷ 4096 = 8388608
echo 'kernel.shmmax=34359738368' >> /etc/sysctl.conf
echo 'kernel.shmall=8388608' >> /etc/sysctl.conf
sysctl -p
- 关闭防火墙、禁用selinux
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
- 配置资源限制ulimit
vi /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
* soft memlock -1
* hard memlock -1
其余内核参数和数据库参数的设置在这里就不一一展示了,具体可参考PG官方文档区调优。
总结
“既要马儿跑,又要马儿不吃草”这句谚语很生动地形容优化的思想,我们得榨干每一点可以利用的资源来提升整体的性能。当然,喂更多的草,马儿肯定跑的更快更远,这就好比去直接升级硬件、加大容量等操作来简单粗暴地提升性能,这种一般是压榨无果的最后手段。文本围绕硬盘I/O、内存分配、文件系统、操作系统内核等多角度提升数据库“底座”性能。
