






亲爱的社区小伙伴们,我们很高兴地向大家宣布,在 3 月 8 日我们引来了 Apache Doris 2.1.0 版本的正式发布,欢迎大家下载使用。
在查询性能方面, 2.1 系列版本我们着重提升了开箱盲测性能,力争不做调优的情况下取得较好的性能表现,包含了对复杂 SQL 查询性能的进一步提升,在 TPC-DS 1TB 测试数据集上获得超过 100% 的性能提升,查询性能居于业界领先地位。
在数据湖分析场景,我们进行了大量性能方面的改进、相对于 Trino 和 Spark 分别有 4-6 倍的性能提升,并引入了多 SQL 方言兼容、便于用户可以从原有系统无缝切换至 Apache Doris。在面向数据科学以及其他形式的大规模数据读取场景,我们引入了基于 Arrow Flight 的高速读取接口,数据传输效率提升 100 倍。
在半结构化数据分析场景,我们引入了全新的 Variant 和 IP 数据类型,完善了一系列分析函数,面向复杂半结构化数据的存储和分析处理更加得心应手。
在 2.1.0 版本中我们也引入了基于多表的异步物化视图以提升查询性能,支持透明改写加速、自动刷新、外表到内表的物化视图以及物化视图直查,基于这一能力物化视图也可用于数据仓库分层建模、作业调度和数据加工。
在存储方面,我们引入了自增列、自动分区、MemTable 前移以及服务端攒批的能力,使得大规模数据实时写入的效率更高。
在负载管理方面,我们进一步完善了 Workload Group 资源组的隔离能力,并增加了运行时查看 SQL 资源用量的能力,进一步提升了多负载场景下的稳定性。
在 2.1.0 版本的研发过程中,有 237 位贡献者为 Apache Doris 带来了接近 6000 个 Commits。同时 2.1.0 版本也同样经过了近百家社区用户的大规模打磨,在测试过程中向我们反馈了许多有价值的优化项,在此向所有参与版本研发、测试和需求反馈的贡献者们表示最衷心的感谢。后续我们将会持续敏捷发版来响应所有用户对功能和稳定性的更高追求,欢迎大家在使用过程中给予我们更多反馈。
GitHub下载:
https://github.com/apache/doris/releases
官网下载页:
https://doris.apache.org/download
Release Note:
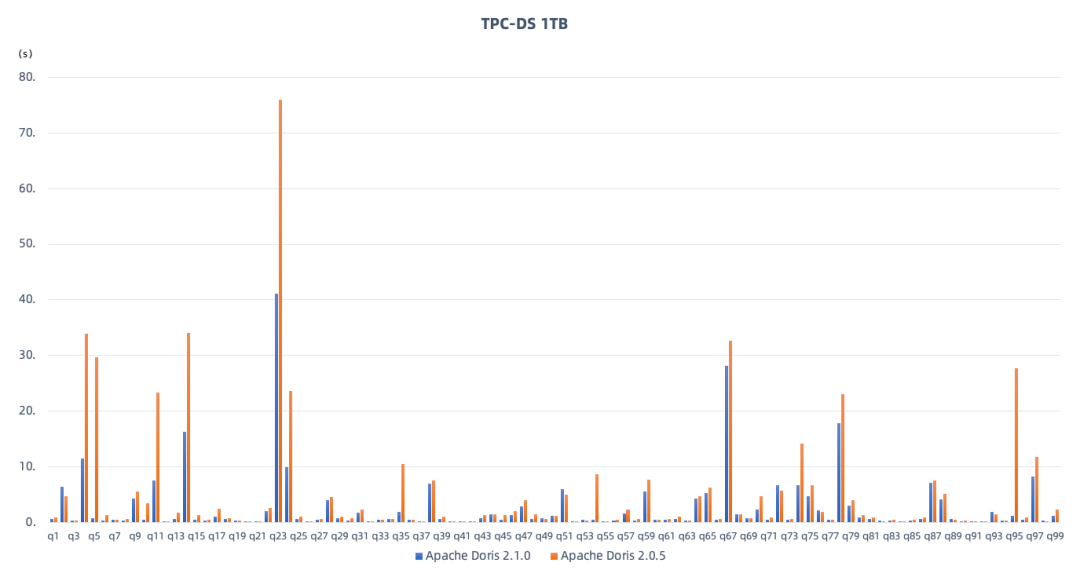
在 2.1 系列版本中,我们着重提升了开箱盲测性能,力争不做调优的情况下取得较好的性能表现,包含了对复杂 SQL 查询性能的进一步提升。在此我们以 TPC-DS 1TB 作为性能测试对比的基准,重点对比最新 2.1.0 版本与 2.0.5 版本的性能提升。集群规模均为 1FE、3BE,其中 BE 节点的服务器配置为 48C 192G。从以下测试结果中可以看到:
2.1.0 版本的总查询耗时为 245.7 秒,相较于 2.0.5 版本的 489.6 秒,性能提升达到 100 %; 在全部 99 个 SQL 中,有近三分之一的 SQL 查询性能提升达到 2 倍以上,超过 80 个 SQL 都获得显著性能提升; 不论是基础的过滤、排序、聚合,或者复杂的多表关联查询、子查询以及窗口函数计算,2.1.0 版本都有更为明显的性能优势; 2.0.5 版本或 2.1.0 版本,都可以完整执行 TPC-DS 的 99 个查询。
01 优化器更智能
优化器基础设施完善:在多种优化器基础设施方面进行了补充和增强,例如对统计信息推导和代价模型方面的持续改进,使之能够收集更多的特征信息为复杂优化提供基础; 优化规则持续扩展:得益于丰富的实际场景反馈,新版本中查询优化器增强了包括算子下压在内的许多经典规则,结合上述基础设施扩充而引入的新优化规则,使得新版本的查询优化器能覆盖更广泛的使用场景; 枚举框架进一步优化:在查询优化器 Cascades 和 DPhyper 两大融合框架的基础上,继续深耕框架能力、优化框架性能,确立了更为清晰的枚举策略,兼顾计划质量和枚举效率,为高性能引擎提供坚实基础。例如将 Cascades 默认枚举表上限从 5 提升到了 8、有效扩大了高质量计划的覆盖范围,同时进一步优化 DPhyper 枚举效率、使之能够枚举出更优计划。
02 无统计信息优化
03 Parallel Adaptive Scan 并行自适应扫描
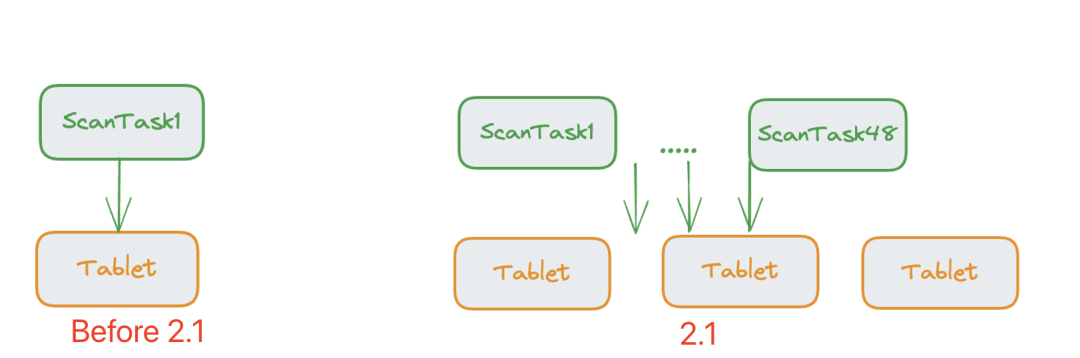
04 Local Shuffle
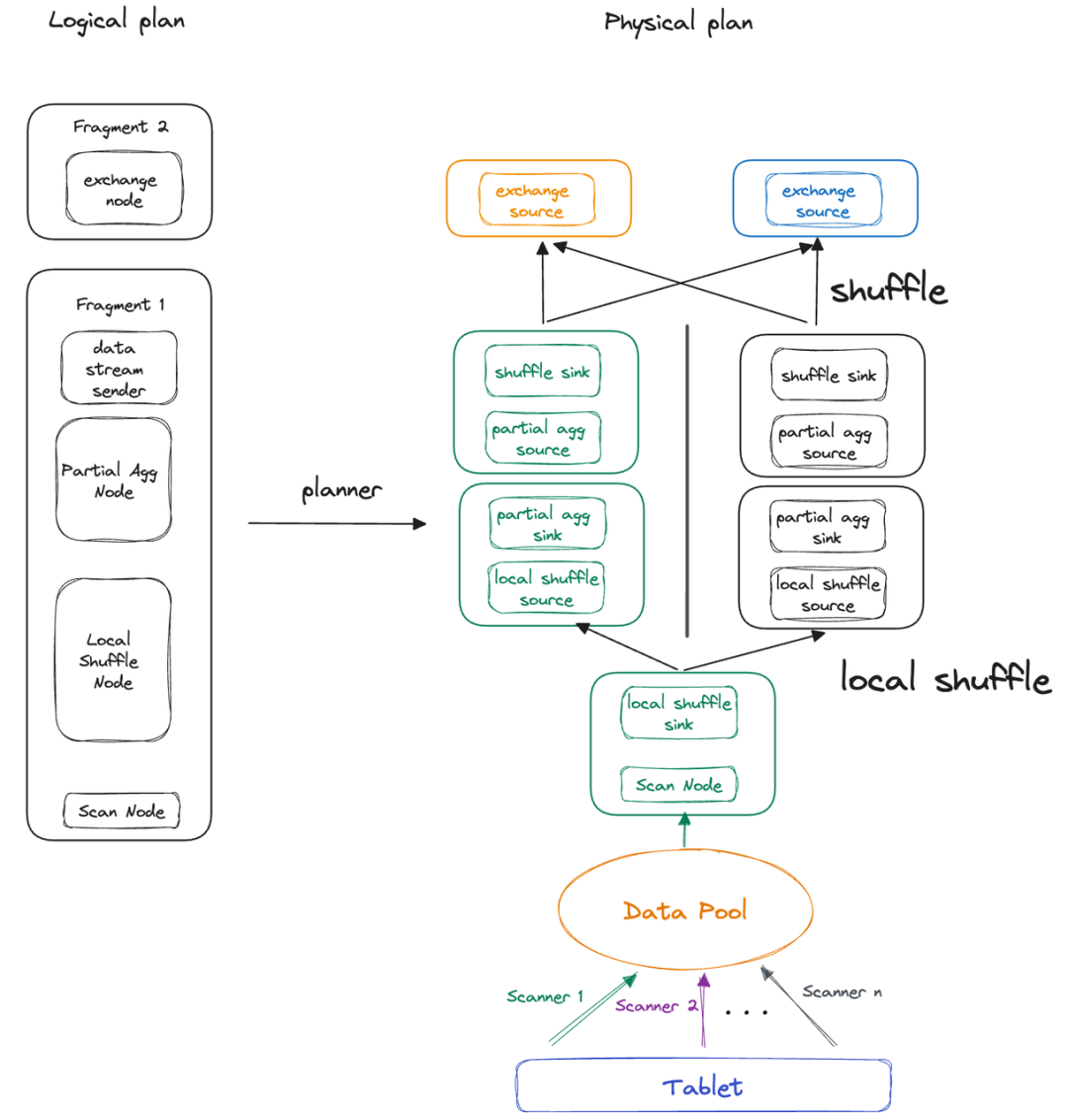
参考文档:https://doris.apache.org/zh-CN/docs/query-acceleration/pipeline-x-execution-engine
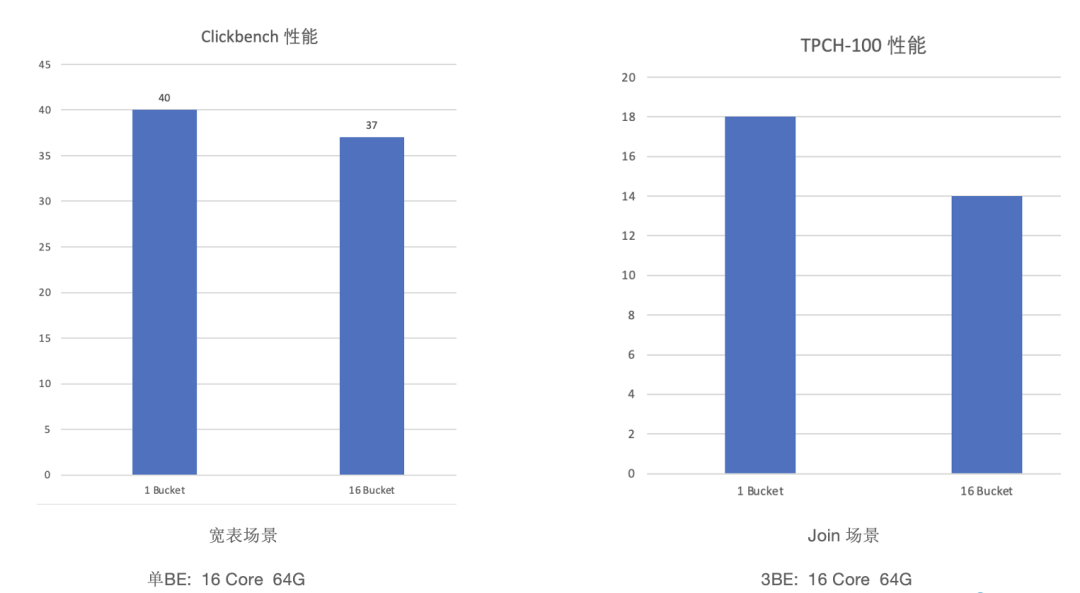
ARM 架构深度适配,性能提升 230%
在大宽表场景中, ClickBench 测试数据集 43 个 SQL 的总查询耗时从 102.36 秒降低至 30.73 秒,性能提升超过 230%; 在多表关联场景中, TPC-H 22 个 SQL 的总查询耗时从 174.8 秒降低至 90.4 秒,性能提升 93%;
数据湖分析
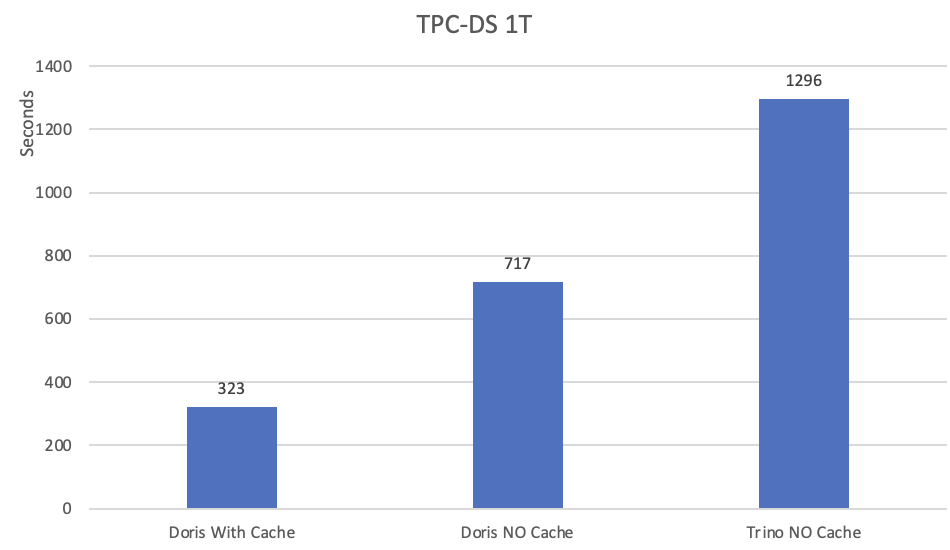
在无缓存情况下,Apache Doris 的总体运行耗时间为 717s、Trino 为 1296s,查询耗时降低了 45%,全部 99 条 SQL 中有 80% 比 Trino 更快 ; 在开启文件缓存功能并命中的情况下,Apache Doris 的总体性能可以进一步提升 2.2 倍以上,较 Trino 有 4 倍以上的性能提升,全部 99 条 SQL 性能均优于 Trino。
02 多 SQL 方言兼容
sql_dialect设置当前会话的 SQL 方言类型,即可使用对应的 SQL 方言进行查询。
set sql_dialect = trino,即可直接采取 Trino SQL 语法执行查询。在某些社区用户的实际线上业务 SQL 兼容性测试中,在全部 3w 多条查询语句中与 Trino SQL 兼容度高达 99% 以上。也欢迎所有用户在使用过程中向我们反馈不兼容的 Case,帮助 Apache Doris 更加完善。
参考文档:https://doris.apache.org/zh-CN/docs/lakehouse/sql-dialect
03 高速数据读取,数据传输效率提升 100 倍
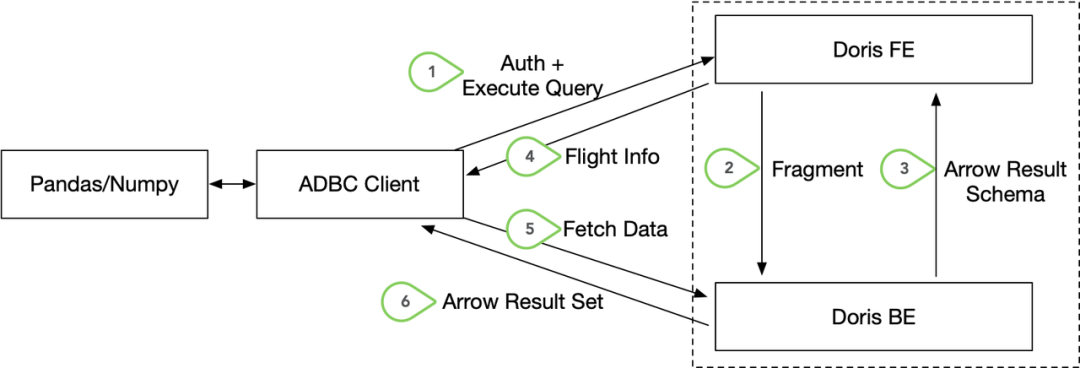
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "user",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "pass",
})
cursor = conn.cursor()
cursor.execute("select * from arrow_flight_sql_test order by k0;")
print(cursor.fetchallarrow().to_pandas())
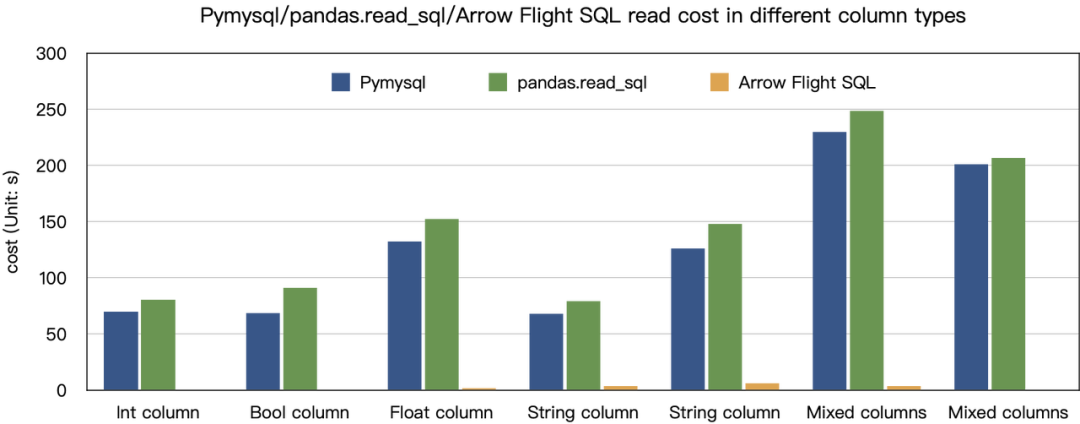
Paimon Catalog:Paimon 版本升级至 0.6.0,优化了 Read Optimized 表的读取,在 Paimon 数据充分合并的场景下,可以有 10 倍的性能提升; Iceberg Catalog:Iceberg 版本升级至 1.4.3,同时解决了 AWS S3 认证的若干兼容性问题; Hudi Catalog:Hudi 版本升级至 0.14.1,同时解决了 Hudi Flink Catalog 的若干兼容性问题。
多表物化视图
use tpch;
CREATE TABLE IF NOT EXISTS orders (
o_orderkey integer not null,
o_custkey integer not null,
o_orderstatus char(1) not null,
o_totalprice decimalv3(15,2) not null,
o_orderdate date not null,
o_orderpriority char(15) not null,
o_clerk char(15) not null,
o_shippriority integer not null,
o_comment varchar(79) not null
)
DUPLICATE KEY(o_orderkey, o_custkey)
PARTITION BY RANGE(o_orderdate)(
FROM ('2023-10-17') TO ('2023-10-20') INTERVAL 1 DAY)
DISTRIBUTED BY HASH(o_orderkey) BUCKETS 3
PROPERTIES ("replication_num" = "1");
insert into orders values
(1, 1, 'ok', 99.5, '2023-10-17', 'a', 'b', 1, 'yy'),
(2, 2, 'ok', 109.2, '2023-10-18', 'c','d',2, 'mm'),
(3, 3, 'ok', 99.5, '2023-10-19', 'a', 'b', 1, 'yy');
CREATE TABLE IF NOT EXISTS lineitem (
l_orderkey integer not null,
l_partkey integer not null,
l_suppkey integer not null,
l_linenumber integer not null,
l_quantity decimalv3(15,2) not null,
l_extendedprice decimalv3(15,2) not null,
l_discount decimalv3(15,2) not null,
l_tax decimalv3(15,2) not null,
l_returnflag char(1) not null,
l_linestatus char(1) not null,
l_shipdate date not null,
l_commitdate date not null,
l_receiptdate date not null,
l_shipinstruct char(25) not null,
l_shipmode char(10) not null,
l_comment varchar(44) not null
)
DUPLICATE KEY(l_orderkey, l_partkey, l_suppkey, l_linenumber)
PARTITION BY RANGE(l_shipdate)
(FROM ('2023-10-17') TO ('2023-10-20') INTERVAL 1 DAY)
DISTRIBUTED BY HASH(l_orderkey) BUCKETS 3
PROPERTIES ("replication_num" = "1");
insert into lineitem values
(1, 2, 3, 4, 5.5, 6.5, 7.5, 8.5, 'o', 'k', '2023-10-17', '2023-10-17', '2023-10-17', 'a', 'b', 'yyyyyyyyy'),
(2, 2, 3, 4, 5.5, 6.5, 7.5, 8.5, 'o', 'k', '2023-10-18', '2023-10-18', '2023-10-18', 'a', 'b', 'yyyyyyyyy'),
(3, 2, 3, 6, 7.5, 8.5, 9.5, 10.5, 'k', 'o', '2023-10-19', '2023-10-19', '2023-10-19', 'c', 'd', 'xxxxxxxxx');
CREATE TABLE IF NOT EXISTS partsupp (
ps_partkey INTEGER NOT NULL,
ps_suppkey INTEGER NOT NULL,
ps_availqty INTEGER NOT NULL,
ps_supplycost DECIMALV3(15,2) NOT NULL,
ps_comment VARCHAR(199) NOT NULL
)
DUPLICATE KEY(ps_partkey, ps_suppkey)
DISTRIBUTED BY HASH(ps_partkey) BUCKETS 3
PROPERTIES (
"replication_num" = "1"
)创建物化视图:
CREATE MATERIALIZED VIEW mv1
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by(l_shipdate)
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES ('replication_num' = '1')
AS
select l_shipdate, o_orderdate, l_partkey,
l_suppkey, sum(o_totalprice) as sum_total
from lineitem
left join orders on lineitem.l_orderkey = orders.o_orderkey
and l_shipdate = o_orderdate
group by
l_shipdate,
o_orderdate,
l_partkey,
l_suppkey;
透明改写加速:支持常见算子的透明改写,如 Select、Where、Join、Group by、Aggregation 等,可以直接通过建立物化视图,对现有的查询进行加速。例如在 BI 报表场景,某些报表查询延时比较高,就可以通过建立合适的物化视图进行加速。 自动刷新:物化视图支持不同刷新策略,如定时刷新和手动刷新,也支持不同的刷新粒度,如全量刷新、分区粒度的增量刷新等。 外表到内表的物化视图:可以对存放在 Hive、Hudi、Iceberg 等数据湖系统上的数据建立物化视图,加速对数据湖的访问,也可以通过物化视图的方式将数据湖中的数据同步到 Apache Doris 内表中。 物化视图直查:用户也可以将物化视图的构建看做 ETL 的过程,把物化视图看做是 ETL 加工后的结果数据,由于物化视图本身也是一个表,所以用户可以直接查询物化视图。
参考文档:https://doris.apache.org/zh-CN/docs/query-acceleration/async-materialized-view/
01 自增列 AUTO_INCREMENT
CREATE TABLE `demo`.`dictionary_tbl` (
`user_id` varchar(50) NOT NULL,
`aid` BIGINT NOT NULL AUTO_INCREMENT
) ENGINE=OLAP
UNIQUE KEY(`user_id`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 32
PROPERTIES (
"replication_allocation" = "tag.location.default: 3",
"enable_unique_key_merge_on_write" = "true"
);
limit,
offset+
order by进行查询。在进行深分页查询时,即使查询数据量较少、数据库仍需将全部数据读取至内存进行全量排序,查询效率比较低下。采取自增列可以为每一行生成唯一标识、查询时记住上一页最大唯一标识并用于下一页的查询条件,实现更高效的分页查询。
CREATE TABLE `demo`.`records_tbl2` (
`key` int(11) NOT NULL COMMENT "",
`name` varchar(26) NOT NULL COMMENT "",
`address` varchar(41) NOT NULL COMMENT "",
`city` varchar(11) NOT NULL COMMENT "",
`nation` varchar(16) NOT NULL COMMENT "",
`region` varchar(13) NOT NULL COMMENT "",
`phone` varchar(16) NOT NULL COMMENT "",
`mktsegment` varchar(11) NOT NULL COMMENT "",
`unique_value` BIGINT NOT NULL AUTO_INCREMENT
) DUPLICATE KEY (`key`, `name`)CREATE TABLE ipv4_test (
`id` int,
`ip_v4` ipv4
) ENGINE=OLAP
DISTRIBUTED BY HASH(`id`) BUCKETS 4
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
DISTRIBUTED BY HASH(`key`) BUCKETS 10
PROPERTIES (
"replication_num" = "3"
);
select * from records_tbl2 order by unique_value limit 100;通过程序记录下返回结果中 select * from records_tbl2 order by unique_value limit 100;
unique_value中的最大值,假设为 99,则可用如下方式查询第二页的数据:
select key, name, address, city, nation, region, phone, mktsegment
from records_tbl2, (select unique_value as max_value from records_tbl2 order by uniuqe_value limit 1 offset 9999) as previous_data
where records_tbl2.uniuqe_value > previous_data.max_value
order by unique_value limit 100;
unique_value的最大值时,例如要直接获取第 101 页的内容,则可以使用如下方式进行查询
select key, name, address, city, nation, region, phone, mktsegment
from records_tbl2, (select unique_value as max_value from records_tbl2 order by uniuqe_value limit 1 offset 9999) as previous_data
where records_tbl2.uniuqe_value > previous_data.max_value
order by unique_value limit 100;
参考文档:https://doris.apache.org/zh-CN/docs/advanced/auto-increment
02 自动分区 Auto Partition
CREATE TABLE `DAILY_TRADE_VALUE`
(
`TRADE_DATE` datev2 NULL COMMENT '交易日期',
`TRADE_ID` varchar(40) NULL COMMENT '交易编号',
......
)
UNIQUE KEY(`TRADE_DATE`, `TRADE_ID`)
AUTO PARTITION BY RANGE date_trunc(`TRADE_DATE`, 'year')
(
)
DISTRIBUTED BY HASH(`TRADE_DATE`) BUCKETS 10
PROPERTIES (
"replication_num" = "1"
);
date_trunc、分区列仅支持
DATE或者
DATETIME格式;List 分区不支持函数调用,分区列支持
BOOLEAN、TINYINT、
SMALLINT、
INT、
BIGINT、
LARGEINT、
DATE、
DATETIME、
CHAR、
VARCHAR数据类型,分区值为枚举值;
参考文档:https://doris.apache.org/zh-CN/docs/advanced/partition/auto-partition/
INSERT INTO…SELECT语句是 ETL 中最高频使用的操作之一,可以快速完成数据在库表之间的迁移、转换以及清洗合并,提升
INSERT INTO…SELECT性能可以更好满足用户对数据快速提取和分析的需求。在 Apache Doris 2.0 版本中,我们引入了单副本导入功能(Single Replica Load)来减少多副本的重复写入和 Compaction 工作,但是导入性能还存在优化的空间。
INSERT INTO…SELECT性能,我们实现了 MemTable 前移以进一步减少导入过程中的开销,能在大多数场景中能在 2.0 版本的基础上取得 100% 的导入性能提升。
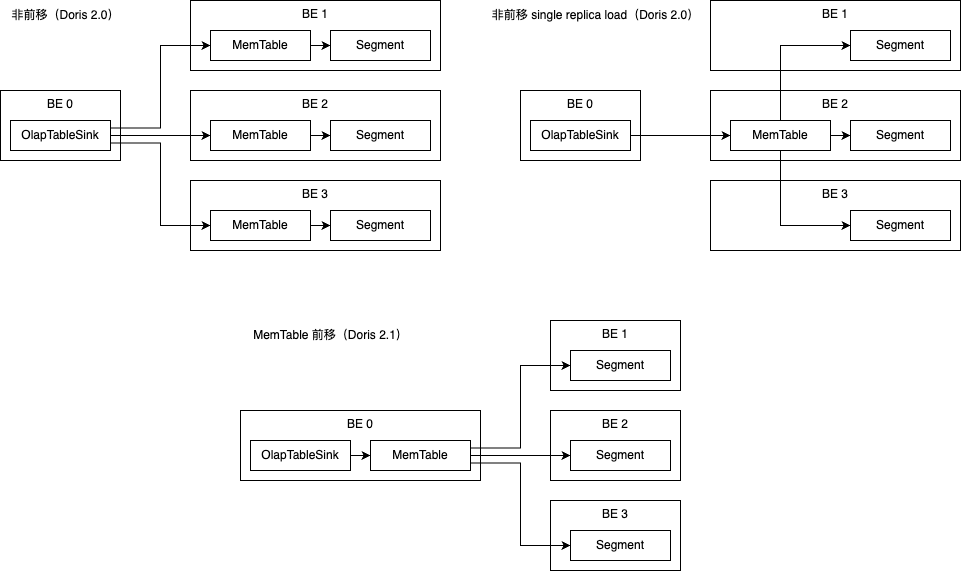
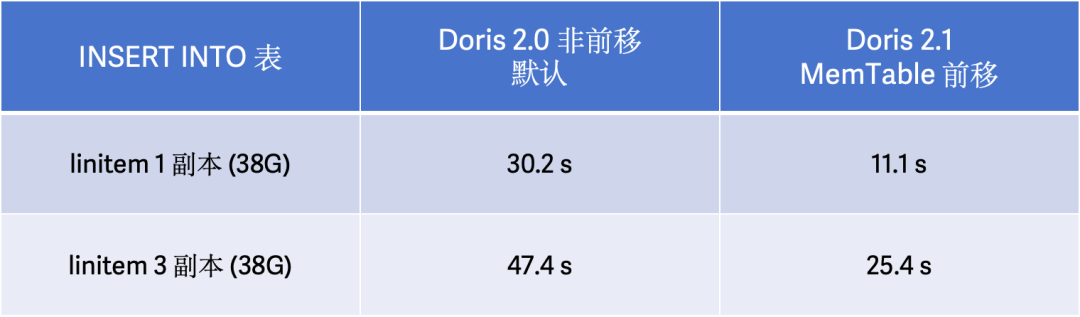
enable_memtable_on_sink_node=false来关闭 MemTable 前移。
04 高频实时导入/服务端攒批 Group Commit
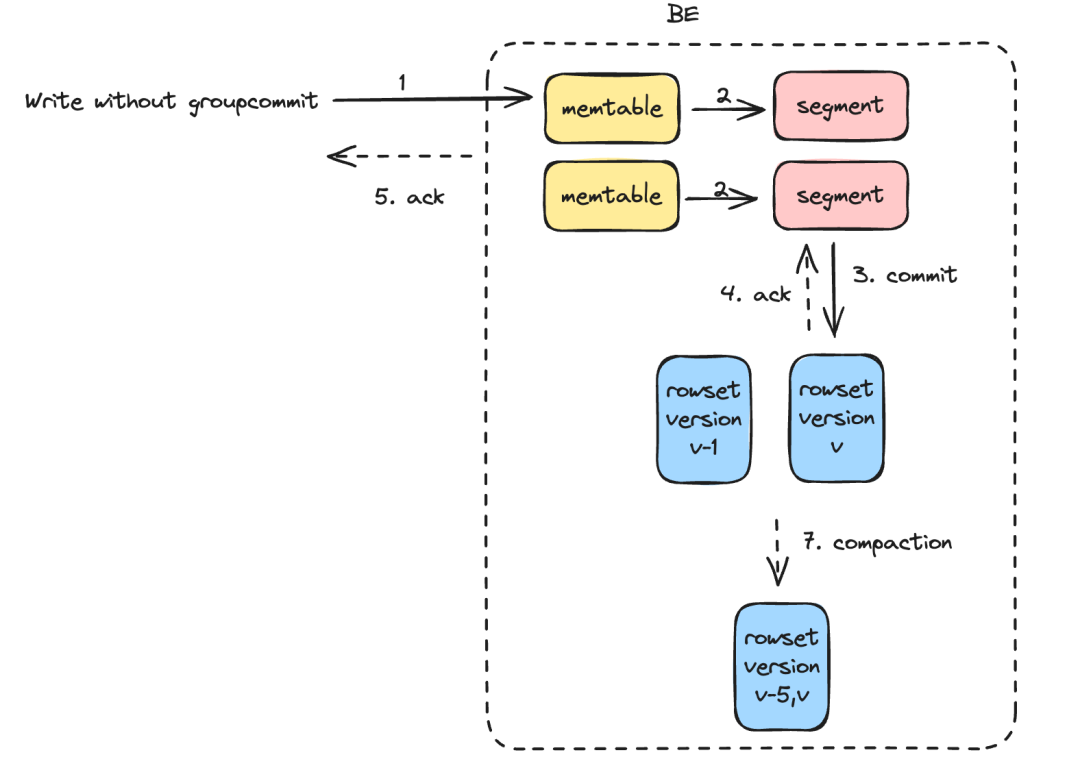
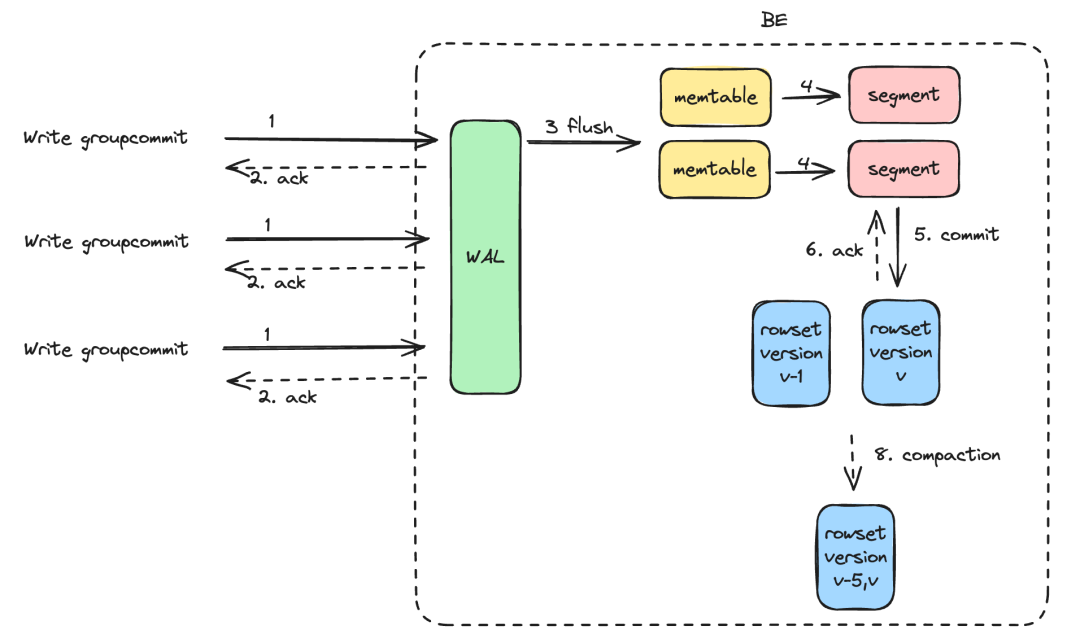
sync_mode和异步模式
async_mode。同步模式下会将多个导入在一个事务提交,事务提交后导入返回,在导入完成后数据立即可见。异步模式下数据会先写入 WAL,Apache Doris 会根据负载和表的
group_commit_interval属性异步提交数据,提交之后数据可见。为了防止 WAL 占用较大的磁盘空间,单次导入数据量较大时,会自动切换为
sync_mode。
async_mode)的写入性能进行了测试,测试报告如下:
集群配置为 1FE 1BE,数据集为 TPC-H SF10 Lineitem 表,总共约 22GB、1.8 亿行; 经测试,在并发数 20、单次 Insert 数据行数 100 行下,导入效率达到 10.69w 行/秒、导入吞吐达 11.46 MB/秒, BE 节点的 CPU 使用率稳定保持在 10%-20%;
集群配置为 1FE 3BE,数据集为 httplogs、总共 31GB、2.47 亿行。在未开启 Group Commit 和 开启 Group Commit 的异步模式时,通过设置不同的单并发数据量和并发数,对比数据的写入性能。 经测试,在并发数 10、单次导入数据量 1 MB 下,未开启 Group Commit 时会提示 -235 错误,开启后可稳定运行且导入效率达 81w 行/秒、导入吞吐达 104 MB/秒;在并发数 10、单次导入数据量 10MB 下,开启 Group Commit 后耗时降低至原先的 55%、导入吞吐提升 79%;
参考文档和完整测试报告:https://doris.apache.org/zh-CN/docs/data-operate/import/import-way/group-commit-manual/
半结构化数据分析
一种方式是用户提前预定好表结构,加工成宽表,在数据进入前将数据解析好,这种方案的优点是写入性能好,查询也不需要解析,但是使用不够灵活、对表结构发起变更增加运维、研发的成本。 使用 Doris 中的 JSON 类型、或是存成 JSON String,将原始 JSON 数据不经过加工直接入库, 查询的时候,用解析函数处理。优点是不需要额外的数据加工、预定义表结构拍平嵌套结构,运维、研发方便,但存在解析性能以及数据读取效率低下的问题。
-- 无索引
CREATE TABLE IF NOT EXISTS ${table_name} (
k BIGINT,
v VARIANT
)
table_properties;
-- 在v列创建索引,可选指定分词方式,默认不分词
CREATE TABLE IF NOT EXISTS ${table_name} (
k BIGINT,
v VARIANT,
INDEX idx_var(v) USING INVERTED [PROPERTIES("parser" = "english|unicode|chinese")] [COMMENT 'your comment']
)
table_properties;
-- 查询,使用`[]`形式访问子列
SELECT v["properties"]["title"] from ${table_name}
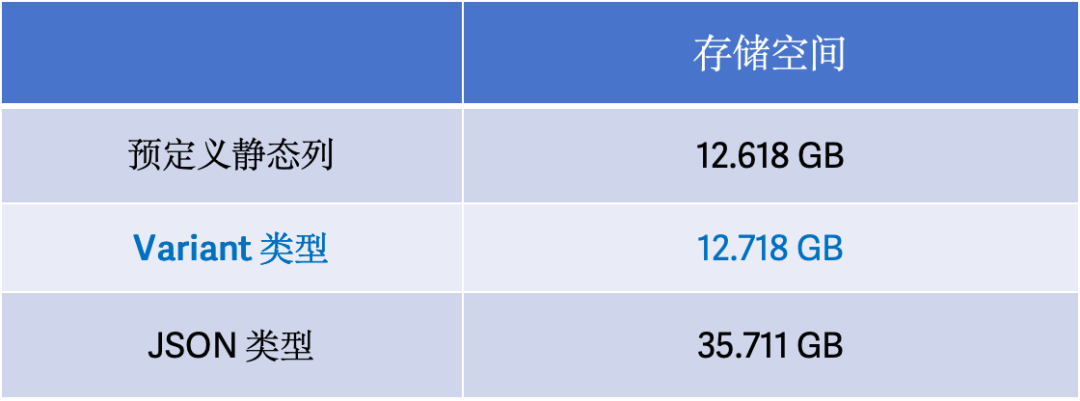
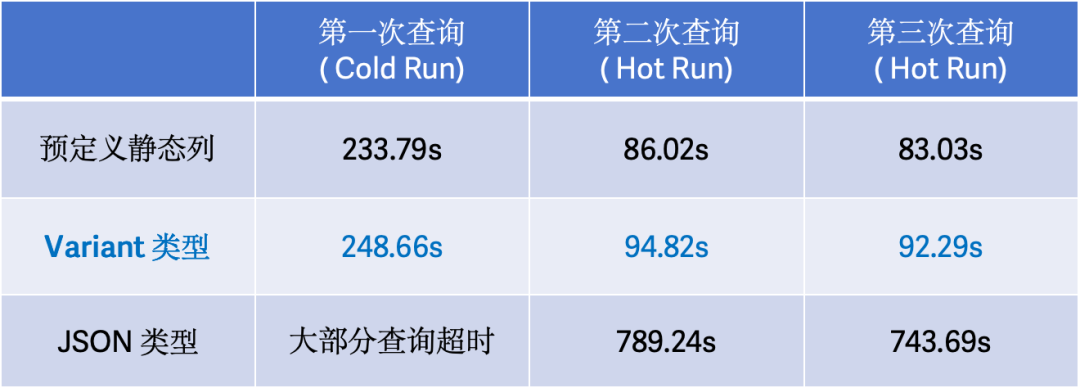
目前 Variant 暂不支持 Aggregate 模型,也不支持将 Variant 类型作为 Unique 或 Duplicate 模型的主键及排序键; 推荐使用 RANDOM 模式或者开启 Group Commit 导入,写入性能更高效; 日期、Decimal 等非标准 JSON 类型尽可能提取出来作为静态字段,性能更好; 二维及其以上的数组以及数组嵌套对象,列存化会被存成 JSONB 编码,性能不如原生数组; 查询过滤、聚合需要带 Cast,存储层会根据存储类型和 Cast 目标类型来提示(hint)存储引擎谓词下推,加速查询。
参考文档:https://doris.apache.org/zh-CN/docs/sql-manual/sql-reference/Data-Types/VARIANT
02 IP 数据类型
IPV4_NUM_TO_STRING:将类型为 Int16、Int32、Int64 且大端表示的 IPv4 的地址,返回相应 IPv4 的字符串表现形式; IPV4_CIDR_TO_RANGE:接收一个 IPv4 和一个包含 CIDR 的 Int16 值,返回一个结构体,其中包含两个 IPv4 字段分别表示子网的较低范围(min)和较高范围(max); INET_ATON:获取包含 IPv4 地址的字符串,格式为 A.B.C.D(点分隔的十进制数字)
参考文档:https://doris.apache.org/zh-CN/docs/sql-manual/sql-reference/Data-Types/IPV6
03 复杂数据类型分析函数完善
explode_map:支持 MAP 类型数据行转列(仅在新优化器中实现)
explode_map需要和 Lateral View 一起使用,可以接多个 Lateral View, 结果则是每个
explode_map之后的行数以笛卡尔积的形式展示。
-- 建表语句
CREATE TABLE `sdu` (
`id` INT NULL,
`name` TEXT NULL,
`score` MAP<TEXT,INT> NULL
) ENGINE=OLAP
DUPLICATE KEY(`id`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
-- insert 数据
insert into sdu values (0, "zhangsan", {"Chinese":"80","Math":"60","English":"90"});
insert into sdu values (1, "lisi", {"null":null});
insert into sdu values (2, "wangwu", {"Chinese":"88","Math":"90","English":"96"});
insert into sdu values (3, "lisi2", {null:null});
insert into sdu values (4, "amory", NULL);
mysql> select name, course_0, score_0 from sdu lateral view explode_map(score) tmp as course_0,score_0;
+----------+----------+---------+
| name | course_0 | score_0 |
+----------+----------+---------+
| zhangsan | Chinese | 80 |
| zhangsan | Math | 60 |
| zhangsan | English | 90 |
| lisi | null | NULL |
| wangwu | Chinese | 88 |
| wangwu | Math | 90 |
| wangwu | English | 96 |
| lisi2 | NULL | NULL |
+----------+----------+---------+
mysql> select name, course_0, score_0, course_1, score_1 from sdu lateral view explode_map(score) tmp as course_0,score_0 lateral view explode_map(score) tmp1 as course_1,score_1;
+----------+----------+---------+----------+---------+
| name | course_0 | score_0 | course_1 | score_1 |
+----------+----------+---------+----------+---------+
| zhangsan | Chinese | 80 | Chinese | 80 |
| zhangsan | Chinese | 80 | Math | 60 |
| zhangsan | Chinese | 80 | English | 90 |
| zhangsan | Math | 60 | Chinese | 80 |
| zhangsan | Math | 60 | Math | 60 |
| zhangsan | Math | 60 | English | 90 |
| zhangsan | English | 90 | Chinese | 80 |
| zhangsan | English | 90 | Math | 60 |
| zhangsan | English | 90 | English | 90 |
| lisi | null | NULL | null | NULL |
| wangwu | Chinese | 88 | Chinese | 88 |
| wangwu | Chinese | 88 | Math | 90 |
| wangwu | Chinese | 88 | English | 96 |
| wangwu | Math | 90 | Chinese | 88 |
| wangwu | Math | 90 | Math | 90 |
| wangwu | Math | 90 | English | 96 |
| wangwu | English | 96 | Chinese | 88 |
| wangwu | English | 96 | Math | 90 |
| wangwu | English | 96 | English | 96 |
| lisi2 | NULL | NULL | NULL | NULL |
+----------+----------+---------+----------+---------+
explode_map_outer
和explode_outer
的目的一致,可以将当前 MAP 类型的列中是 NULL 的数据行展示出来。
mysql> select name, course_0, score_0 from sdu lateral view explode_map_outer(score) tmp as course_0,score_0;
+----------+----------+---------+
| name | course_0 | score_0 |
+----------+----------+---------+
| zhangsan | Chinese | 80 |
| zhangsan | Math | 60 |
| zhangsan | English | 90 |
| lisi | null | NULL |
| wangwu | Chinese | 88 |
| wangwu | Math | 90 |
| wangwu | English | 96 |
| lisi2 | NULL | NULL |
| amory | NULL | NULL |
+----------+----------+---------+
2. 增加 IN 谓词支持 Struct 类型数据的能力(仅在新优化器中实现)
IN 谓词的左参数支持struct() function
构建的 Struct 类型的数据,也支持 Select 某表中某一列是 Struct 类型的数据,右边的参数支持一个由struct() function
构建的 Struct 类型的数据的数组。IN 谓词支持 Struct 类型可以有效替换 Where 条件中如果需要大量的 or 连词连接的表达式,如:(a = 1 and b = '2') or (a = 1 and b = '3') or (...)
可以通过 IN 实现为 struct(a,b) in (struct(1, '2'), struct(1, '3'), ...)
mysql> select struct(1,"2") in (struct(1,3), struct(1,"2"), struct(1,1), null);
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| cast(struct(1, '2') as STRUCT<col1:TINYINT,col2:TEXT>) IN (NULL, cast(struct(1, '2') as STRUCT<col1:TINYINT,col2:TEXT>), cast(struct(1, 1) as STRUCT<col1:TINYINT,col2:TEXT>), cast(struct(1, 3) as STRUCT<col1:TINYINT,col2:TEXT>)) |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| 1 |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
mysql> select struct(1,"2") not in (struct(1,3), struct(1,"2"), struct(1,1), null);
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| ( not cast(struct(1, '2') as STRUCT<col1:TINYINT,col2:TEXT>) IN (NULL, cast(struct(1, '2') as STRUCT<col1:TINYINT,col2:TEXT>), cast(struct(1, 1) as STRUCT<col1:TINYINT,col2:TEXT>), cast(struct(1, 3) as STRUCT<col1:TINYINT,col2:TEXT>))) |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| 0 |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
3.MAP_AGG:接收 expr1 作为键,expr2 作为对应的值,返回一个 MAP
参考文档:https://doris.apache.org/zh-CN/docs/sql-manual/sql-functions/aggregate-functions/map-agg/
负载管理
Doris 2.0 版本的 CPU 隔离是基于优先级队列实现的,而在 2.1 版本中 Apache Doris 是基于 CGroup 实现了 CPU 资源的隔离,因此从 2.0 版本升级到 2.1 版本时,需要在使用前完成 CGroup 的配置,详细注意事项参考官网文档。 目前 Workload Group 支持的工作负载类型包括查询的隔离以及导入与查询之间的隔离,需要注意的是如果期望对导入负载进行彻底的限制,那么需要开启 MemTable 前移。 用户需要通过开关指定当前集群的 CPU 限制模式是软限还是硬限,暂不支持两种模式同时运行,两种模式的切换可以参考官网文档,后续我们也会根据用户的实际需求决定是否要同时支持这两种模式。
参考文档:https://doris.apache.org/zh-CN/docs/admin-manual/workload-group/
02 TopSQL
mysql [(none)]>desc function active_queries();
+------------------------+--------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------------------+--------+------+-------+---------+-------+
| BeHost | TEXT | No | false | NULL | NONE |
| BePort | BIGINT | No | false | NULL | NONE |
| QueryId | TEXT | No | false | NULL | NONE |
| StartTime | TEXT | No | false | NULL | NONE |
| QueryTimeMs | BIGINT | No | false | NULL | NONE |
| WorkloadGroupId | BIGINT | No | false | NULL | NONE |
| QueryCpuTimeMs | BIGINT | No | false | NULL | NONE |
| ScanRows | BIGINT | No | false | NULL | NONE |
| ScanBytes | BIGINT | No | false | NULL | NONE |
| BePeakMemoryBytes | BIGINT | No | false | NULL | NONE |
| CurrentUsedMemoryBytes | BIGINT | No | false | NULL | NONE |
| ShuffleSendBytes | BIGINT | No | false | NULL | NONE |
| ShuffleSendRows | BIGINT | No | false | NULL | NONE |
| Database | TEXT | No | false | NULL | NONE |
| FrontendInstance | TEXT | No | false | NULL | NONE |
| Sql | TEXT | No | false | NULL | NONE |
+------------------------+--------+------+-------+---------+-------+
active_queries()
函数记录了查询在各个 BE 上运行时的审计信息,该函数可以当做普通的 Doris 表来看待,支持查询、谓词过滤、排序和 Join 等操作。常用的指标包括 SQL 的运行时间、CPU 时间、单 BE 的峰值内存、Scan 的数据量以及 Shuffle 的数据量,也可以从 BE 的粒度做上卷,查看 SQL 全局的资源用量。
查看集群中目前运行时间最久的n个sql
select QueryId,max(QueryTimeMs) as query_time from active_queries() group by QueryId order by query_time desc limit 10;
查看目前集群中CPU耗时最长的n个sql
select QueryId, sum(QueryCpuTimeMs) as cpu_time from active_queries() group by QueryId order by cpu_time desc limit 10
查看目前集群中scan行数最多的n个sql以及他们的运行时间
select t1.QueryId,t1.scan_rows, t2.query_time from
(select QueryId, sum(ScanRows) as scan_rows from active_queries() group by QueryId order by scan_rows desc limit 10) t1
left join (select QueryId,max(QueryTimeMs) as query_time from active_queries() group by QueryId) t2 on t1.QueryId = t2.QueryId
查看目前各个BE的负载情况,按照CPU时间/scan行数/shuffle字节数降序排列
select BeHost,sum(QueryCpuTimeMs) as query_cpu_time, sum(ScanRows) as scan_rows,sum(ShuffleSendBytes) as shuffle_bytes from active_queries() group by BeHost order by query_cpu_time desc,scan_rows desc ,shuffle_bytes desc limit 10
查看单BE峰值内存最高的N个sql
select QueryId,max(BePeakMemoryBytes) as be_peak_mem from active_queries() group by QueryId order by be_peak_mem desc limit 10;
Insert Into……Select,预计在 2.1 版本之上的三位迭代版本中会支持 Stream Load 和 Broker Load 的资源用量展示。
参考文档:https://doris.apache.org/zh-CN/docs/sql-manual/sql-functions/table-functions/active_queries/
其他
01 Decimal256
CREATE TABLE `test_arithmetic_expressions_256` (
k1 decimal(76, 30),
k2 decimal(76, 30)
)
DISTRIBUTED BY HASH(k1)
PROPERTIES (
"replication_num" = "1"
);
insert into test_arithmetic_expressions_256 values
(1.000000000000000000000000000001, 9999999999999999999999999999999999999999999998.999999999999999999999999999998),
(2.100000000000000000000000000001, 4999999999999999999999999999999999999999999999.899999999999999999999999999998),
(3.666666666666666666666666666666, 3333333333333333333333333333333333333333333333.333333333333333333333333333333);
select k1, k2, k1 + k2 a from test_arithmetic_expressions_256 order by 1, 2;
+----------------------------------+-------------------------------------------------------------------------------+-------------------------------------------------------------------------------+
| k1 | k2 | a |
+----------------------------------+-------------------------------------------------------------------------------+-------------------------------------------------------------------------------+
| 1.000000000000000000000000000001 | 9999999999999999999999999999999999999999999998.999999999999999999999999999998 | 9999999999999999999999999999999999999999999999.999999999999999999999999999999 |
| 2.100000000000000000000000000001 | 4999999999999999999999999999999999999999999999.899999999999999999999999999998 | 5000000000000000000000000000000000000000000001.999999999999999999999999999999 |
| 3.666666666666666666666666666666 | 3333333333333333333333333333333333333333333333.333333333333333333333333333333 | 3333333333333333333333333333333333333333333336.999999999999999999999999999999 |
+----------------------------------+-------------------------------------------------------------------------------+-------------------------------------------------------------------------------+
3 rows in set (0.09 sec)
02 任务调度 Job Scheduler
周期性的 Backup; 过期数据定时清理; 周期性的导入任务,如定时通过 Catalog 的方式去进行增量或全量数据同步; 定期 ETL,如部分用户定期从宽表中 Load 数据至指定表、从明细表中定时拉取数据存至聚合表、ODS 层表定时打宽并写入原有宽表更新;
资源浪费:由于调度系统误认为任务失败,可能会重新调度执行已经成功的任务,导致不必要的资源消耗。 数据重复或丢失:如果调度系统选择重试导入任务,可能导致数据重复导入,造成数据冗余和不一致。另一方面,如果调度系统直接标记任务为失败,可能导致实际已成功导入的数据被忽略或丢失。 时间延误:由于调度系统的容错机制被触发,可能需要进行额外的任务调度和重试,导致整体数据处理时间延长,影响业务效率和响应速度。 系统稳定性下降:频繁的重试或直接失败可能导致调度系统和 Doris 的负载增加,进而影响系统的稳定性和性能。
高效调度:Job Scheduler 可以在指定的时间间隔内安排任务和事件,确保数据处理的高效性。采用时间轮算法保证事件能够精准做到秒级触发。 灵活调度:Job Scheduler 提供了多种调度选项,如按 分、小时、天或周的间隔进行调度,同时支持一次性调度以及循环(周期)事件调度,并且周期调度也可以指定开始时间、结束时间。 事件池和高性能处理队列:Job Scheduler 采用 Disruptor 实现高性能的生产消费者模型,最大可能的避免任务执行过载。 调度记录可追溯:Job Scheduler 会存储最新的 Task 执行记录(可配置),通过简单的命令即可查看任务执行记录,确保过程可追溯。 高可用:依托于 Doris 自身的高可用机制,Job 可以很轻松的做到自恢复,高可用。
// 从 2023-11-17 起每天定时执行 insert语句直到 2038 年结束
CREATE
JOB e_daily
ON SCHEDULE
EVERY 1 DAY
STARTS '2023-11-17 23:59:00'
ENDS '2038-01-19 03:14:07'
COMMENT 'Saves total number of sessions'
DO
INSERT INTO site_activity.totals (time, total)
SELECT CURRENT_TIMESTAMP, COUNT(*)
FROM site_activity.sessions where create_time >= days_add(now(),-1) ;
注意:当前 Job Scheduler 仅支持 Insert 内表,参考文档:https://doris.apache.org/zh-CN/docs/sql-manual/sql-reference/Data-Definition-Statements/Create/CREATE-JOB
Behavior Changed
Unique Key 模型默认开启 Merge On Write 写时合并,新创建的 Unique Key 模型的表将自动设置 enable_unique_key_merge_on_write=true
。倒排索引 Invert Index 经过一年多时间的打磨,已实现了对原本的位图索引 Bitmap Index 功能和场景的全覆盖,且功能上和性能上都大幅优于原本的位图索引 Bitmap Index,因此从 Apache Doris 2.1 版本起,我们将默认停止对位图索引 Bitmap Index 的支持,已经创建的位图索引保持不变将继续生效,不允许创建新的位图索引,在未来我们将会移除位图索引的相关代码。 cpu_resource_limit
不再支持,其本身是限制 BE 上 Scanner 线程数目的功能,而 Workload Group 也能支持设置 BE Scanner 线程数目,所以已设置的cpu_resource_limit
将失效。Segment Compaction 主要应对单批次大数据量的导入,可以在同一批次数据中进行多个 Segment 的 Compaction 操作,在 2.1 版本开始 Segment Compaction 将默认开启, enable_segcompaction
默认值设置为 True。Audit Log 插件 从 2.1 版本开始,Apache Doris 开始内置 Audit Log 审计日志插件,用户只需通过设置全局变量 enable_audit_plugin
开启或关闭审计日志功能。对于之前已经安装过审计日志插件的用户,升级后可以继续使用原有插件,也可以通过 uninstall 命令卸载原有插件后,使用新的插件。但注意,切换插件后,审计日志表也将切换到新的表中。 具体可参阅:https://doris.apache.org/docs/ecosystem/audit-plugin/
致谢
467887319、924060929、acnot、airborne12、AKIRA、alan_rodriguez、AlexYue、allenhooo、amory、amory、AshinGau、beat4ocean、BePPPower、bigben0204、bingquanzhao、BirdAmosBird、BiteTheDDDDt、bobhan1、caiconghui、camby、camby、CanGuan、caoliang-web、catpineapple、Centurybbx、chen、ChengDaqi2023、ChenyangSunChenyang、Chester、ChinaYiGuan、ChouGavinChou、chunping、colagy、CSTGluigi、czzmmc、daidai、dalong、dataroaring、DeadlineFen、DeadlineFen、deadlinefen、deardeng、didiaode18、DongLiang-0、dong-shuai、Doris-Extras、Dragonliu2018、DrogonJackDrogon、DuanXujianDuan、DuRipeng、dutyu、echo-dundun、ElvinWei、englefly、Euporia、feelshana、feifeifeimoon、feiniaofeiafei、felixwluo、figurant、flynn、fornaix、FreeOnePlus、Gabriel39、gitccl、gnehil、GoGoWen、gohalo、guardcrystal、hammer、HappenLee、HB、hechao、HelgeLarsHelge、herry2038、HeZhangJianHe、HHoflittlefish777、HonestManXin、hongkun-Shao、HowardQin、hqx871、httpshirley、htyoung、huanghaibin、HuJerryHu、HuZhiyuHu、Hyman-zhao、i78086、irenesrl、ixzc、jacktengg、jacktengg、jackwener、jayhua、Jeffrey、jiafeng.zhang、Jibing-Li、JingDas、julic20s、kaijchen、kaka11chen、KassieZ、kindred77、KirsCalvinKirs、KirsCalvinKirs、kkop、koarz、LemonLiTree、LHG41278、liaoxin01、LiBinfeng-01、LiChuangLi、LiDongyangLi、Lightman、lihangyu、lihuigang、LingAdonisLing、liugddx、LiuGuangdongLiu、LiuHongLiu、liuJiwenliu、LiuLijiaLiu、lsy3993、LuGuangmingLu、LuoMetaLuo、luozenglin、Luwei、Luzhijing、lxliyou001、Ma1oneZhang、mch_ucchi、Miaohongkai、morningman、morrySnow、Mryange、mymeiyi、nanfeng、nanfeng、Nitin-Kashyap、PaiVallishPai、Petrichor、plat1ko、py023、q763562998、qidaye、QiHouliangQi、ranxiang327、realize096、rohitrs1983、sdhzwc、seawinde、seuhezhiqiang、seuhezhiqiang、shee、shuke987、shysnow、songguangfan、Stalary、starocean999、SunChenyangSun、sunny、SWJTU-ZhangLei、TangSiyang2001、Tanya-W、taoxutao、Uniqueyou、vhwzIs、walter、walter、wangbo、Wanghuan、wangqt、wangtao、wangtianyi2004、wenluowen、whuxingying、wsjz、wudi、wudongliang、wuwenchihdu、wyx123654、xiangran0327、Xiaocc、XiaoChangmingXiao、xiaokang、XieJiann、Xinxing、xiongjx、xuefengze、xueweizhang、XueYuhai、XuJianxu、xuke-hat、xy、xy720、xyfsjq、xzj7019、yagagagaga、yangshijie、YangYAN、yiguolei、yiguolei、yimeng、YinShaowenYin、Yoko、yongjinhou、ytwp、yuanyuan8983、yujian、yujun777、Yukang-Lian、Yulei-Yang、yuxuan-luo、zclllyybb、ZenoYang、zfr95、zgxme、zhangdong、zhangguoqiang、zhangstar333、zhangstar333、zhangy5、ZhangYu0123、zhannngchen、ZhaoLongZhao、zhaoshuo、zhengyu、zhiqqqq、ZhongJinHacker、ZhuArmandoZhu、zlw5307、ZouXinyiZou、zxealous、zy-kkk、zzwwhh、zzzxl1993、zzzzzzzs
更多行业实践
智慧金融与政企:杭银消金|河北幸福消费金融|金融壹账通|平安人寿|奇富科技|同程数科|星云零售信贷|银联商务|招商信诺人寿|众安保险|360数科 |360企业安全浏览器
互联网与文娱:斗鱼|叮咚买菜|工商信息查询平台|货拉拉|荔枝微课|票务平台|奇安信|腾讯音乐|天眼查|网易互娱|网易严选|小米|小鹅通|约苗|字节跳动|知乎|360商业化
企业服务与新经济:橙联|度言|观测云|慧策|领健|领创|Moka BI|美联物业|拈花云科|思必驰|物易云通|云积互动|有赞|纵腾集团
往期推荐
