




Self-RAG(Self-Reflective Retrieval-Augmented Generation)是一种新型的检索增强生成框架,旨在提高大型语言模型(LLM)的生成质量和准确性。

Self-RAG通过引入“反思标记”(reflection tokens),使得模型能够根据具体需求动态决定是否进行信息检索。这种方法不仅减少了不必要的检索操作,还提高了生成内容的准确性和相关性。
与传统RAG相比,Self-RAG不仅增强了信息过滤和检索策略的灵活性,还能够更好地处理长尾问题和多样化信息需求,使得生成结果更加精准和高效。
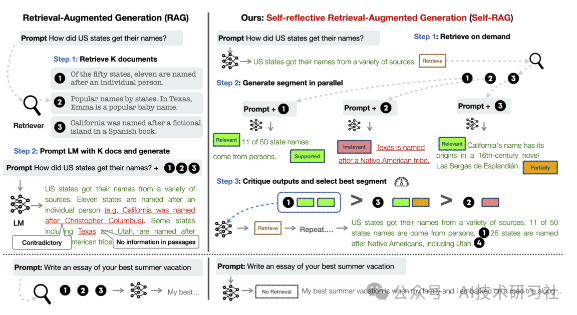
Self-RAG的工作流程主要包括以下几个步骤:
检索决策:
模型首先生成一个检索标记,以评估是否需要从外部资源检索信息。如果不需要检索,模型将直接生成答案;如果需要,则进行相关文档的检索。
生成内容:
在检索到相关文档后,模型会生成基于这些文档的内容,并使用批判标记(critique tokens)来评估生成的答案是否准确和有用。
自我评估:
Self-RAG还会对生成的内容进行自我评估,确保输出的质量和事实准确性。这种自我反思的机制使得模型能够在生成过程中不断优化其输出。
论文开源项目self-rag(https://github.com/AkariAsai/self-rag)实现了自反射RAG。可以从HuggingFace Hub下载Self-RAG。对于推理,该项目建议使用VLLM来提高推理的效率。其他更多内容,读者可访问该项目自行阅读。
from vllm import LLM, SamplingParamsmodel = LLM("selfrag/selfrag_llama2_7b", download_dir="/gscratch/h2lab/akari/model_cache", dtype="half")sampling_params = SamplingParams(temperature=0.0, top_p=1.0, max_tokens=100, skip_special_tokens=False)def format_prompt(input, paragraph=None):prompt = "### Instruction:\n{0}\n\n### Response:\n".format(input)if paragraph is not None:prompt += "[Retrieval]<paragraph>{0}</paragraph>".format(paragraph)return promptquery_1 = "Leave odd one out: twitter, instagram, whatsapp."query_2 = "Can you tell me the difference between llamas and alpacas?"queries = [query_1, query_2]# for a query that doesn't require retrievalpreds = model.generate([format_prompt(query) for query in queries], sampling_params)for pred in preds:print("Model prediction: {0}".format(pred.outputs[0].text))
此外,LangChain框架也实现了Self-RAG的应用,其中LangChain框架被用来处理检索增强生成(RAG)的复杂流程,LangGraph则是用于从头构建图工作流的工具。
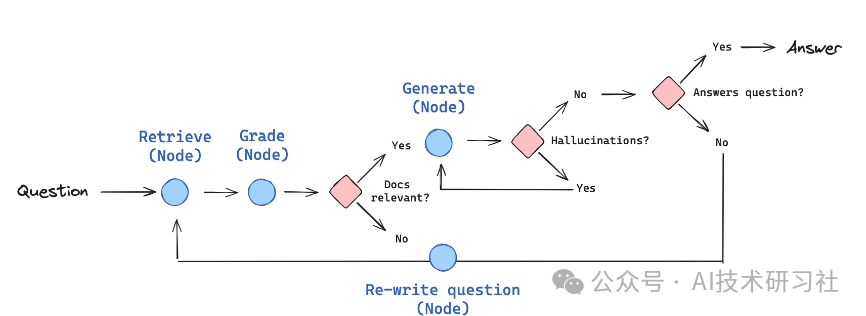
这种工作流的设计使得各节点可以独立处理不同的任务,并根据上下文动态调整执行顺序,提高了模型生成回答的质量和适应性。每个节点代表一个特定的处理步骤(如检索、生成、评估等),而边则定义了各步骤之间的依赖关系和数据流向。
关键代码:
def retrieve(state):"""Retrieve documentsArgs:state (dict): The current graph stateReturns:state (dict): New key added to state, documents, that contains retrieved documents"""print("---RETRIEVE---")question = state["question"]# Retrievaldocuments = retriever.get_relevant_documents(question)return {"documents": documents, "question": question}def generate(state):"""Generate answerArgs:state (dict): The current graph stateReturns:state (dict): New key added to state, generation, that contains LLM generation"""print("---GENERATE---")question = state["question"]documents = state["documents"]# RAG generationgeneration = rag_chain.invoke({"context": documents, "question": question})return {"documents": documents, "question": question, "generation": generation}def grade_documents(state):"""Determines whether the retrieved documents are relevant to the question.Args:state (dict): The current graph stateReturns:state (dict): Updates documents key with only filtered relevant documents"""print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")question = state["question"]documents = state["documents"]# Score each docfiltered_docs = []for d in documents:score = retrieval_grader.invoke({"question": question, "document": d.page_content})grade = score.binary_scoreif grade == "yes":print("---GRADE: DOCUMENT RELEVANT---")filtered_docs.append(d)else:print("---GRADE: DOCUMENT NOT RELEVANT---")continuereturn {"documents": filtered_docs, "question": question}def transform_query(state):"""Transform the query to produce a better question.Args:state (dict): The current graph stateReturns:state (dict): Updates question key with a re-phrased question"""print("---TRANSFORM QUERY---")question = state["question"]documents = state["documents"]# Re-write questionbetter_question = question_rewriter.invoke({"question": question})return {"documents": documents, "question": better_question}### Edgesdef decide_to_generate(state):"""Determines whether to generate an answer, or re-generate a question.Args:state (dict): The current graph stateReturns:str: Binary decision for next node to call"""print("---ASSESS GRADED DOCUMENTS---")state["question"]filtered_documents = state["documents"]if not filtered_documents:# All documents have been filtered check_relevance# We will re-generate a new queryprint("---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---")return "transform_query"else:# We have relevant documents, so generate answerprint("---DECISION: GENERATE---")return "generate"def grade_generation_v_documents_and_question(state):"""Determines whether the generation is grounded in the document and answers question.Args:state (dict): The current graph stateReturns:str: Decision for next node to call"""print("---CHECK HALLUCINATIONS---")question = state["question"]documents = state["documents"]generation = state["generation"]score = hallucination_grader.invoke({"documents": documents, "generation": generation})grade = score.binary_score# Check hallucinationif grade == "yes":print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")# Check question-answeringprint("---GRADE GENERATION vs QUESTION---")score = answer_grader.invoke({"question": question, "generation": generation})grade = score.binary_scoreif grade == "yes":print("---DECISION: GENERATION ADDRESSES QUESTION---")return "useful"else:print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")return "not useful"else:pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")return "not supported"
完整代码参考:https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_self_rag.ipynb
