




概述:RAG(检索增强生成)是一种结合信息检索和生成模型的技术,允许用户将自己的数据与大型语言模型(LLM)结合,生成更精确和上下文相关的输出。这篇文章将简要介绍RAG的基本概念,并提供一个简化的教程,帮助初学者从零开始构建RAG应用程序。
一、学习RAG的挑战
在快速变化的AI领域中,特别是关于RAG,存在大量噪音和复杂性。供应商往往将其过度复杂化,试图将他们的工具、生态系统和愿景注入其中。本教程旨在帮助初学者消除这些干扰,专注于从头构建一个简单的RAG系统。
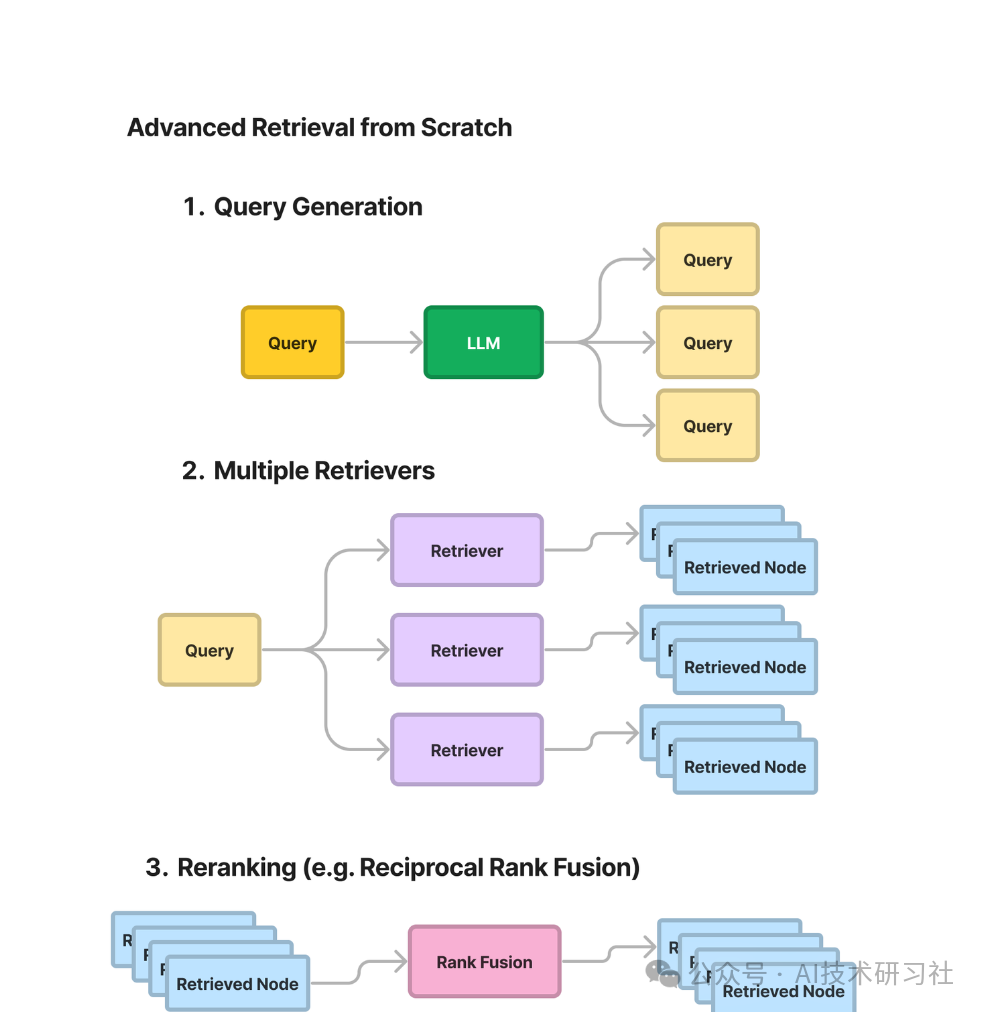
二、什么是检索增强生成(RAG)
RAG的核心思想是通过检索工具将用户的自有数据添加到传递给大型语言模型的提示中,以此生成输出。相比单纯依赖预训练模型,这种方法带来了多项优势:
避免幻觉:通过在提示中包含事实信息,减少LLM产生幻觉的风险。
参考事实:允许用户在回应查询时参考真实数据,验证潜在问题。
利用未训练数据:可以使用LLM未曾训练过的数据。
三、RAG系统的基本组件
一个RAG系统由以下几个组件构成:
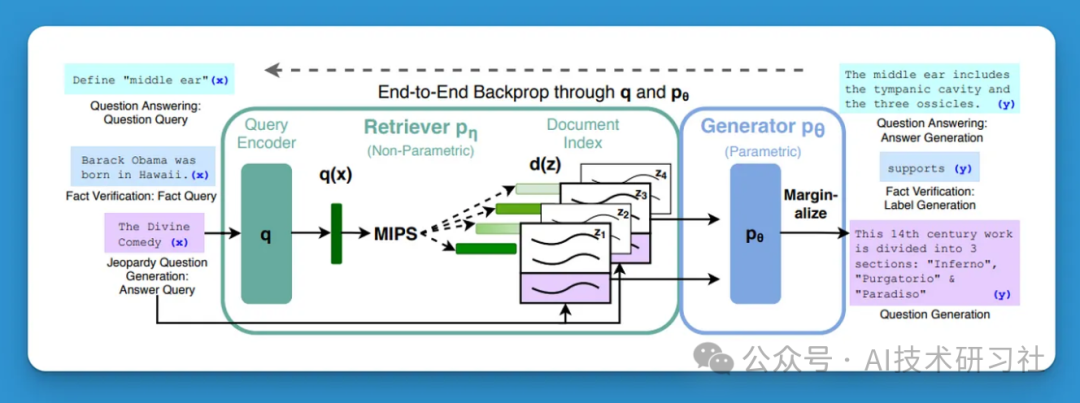
文档集合(语料库)
用户输入
文档集合与用户输入之间的相似性度量
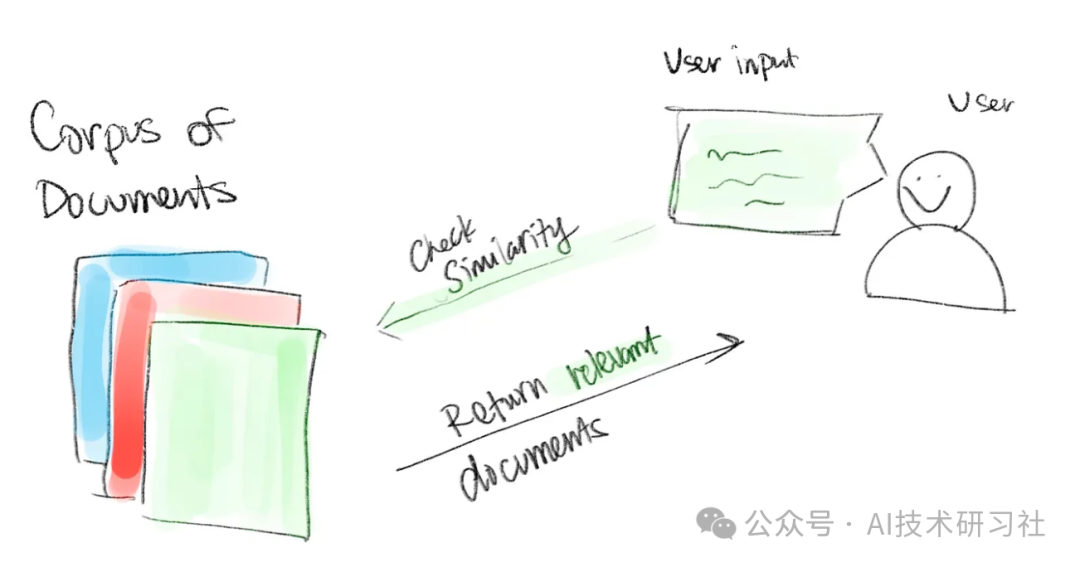
四、RAG系统的操作步骤
接收用户输入
执行相似性测量
对用户输入和检索到的文档进行后处理
初学者可以通过以下步骤从头构建一个RAG系统,并逐步学习复杂的变体。
五、示例:构建最简单的RAG系统
1. 获取文档集合
首先,我们定义一个简单的文档集合:
corpus_of_documents = ["Take a leisurely walk in the park and enjoy the fresh air.","Visit a local museum and discover something new.","Attend a live music concert and feel the rhythm.","Go for a hike and admire the natural scenery.","Have a picnic with friends and share some laughs.","Explore a new cuisine by dining at an ethnic restaurant.","Take a yoga class and stretch your body and mind.","Join a local sports league and enjoy some friendly competition.","Attend a workshop or lecture on a topic you're interested in.","Visit an amusement park and ride the roller coasters."]
文章转载自AI技术研习社,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
