




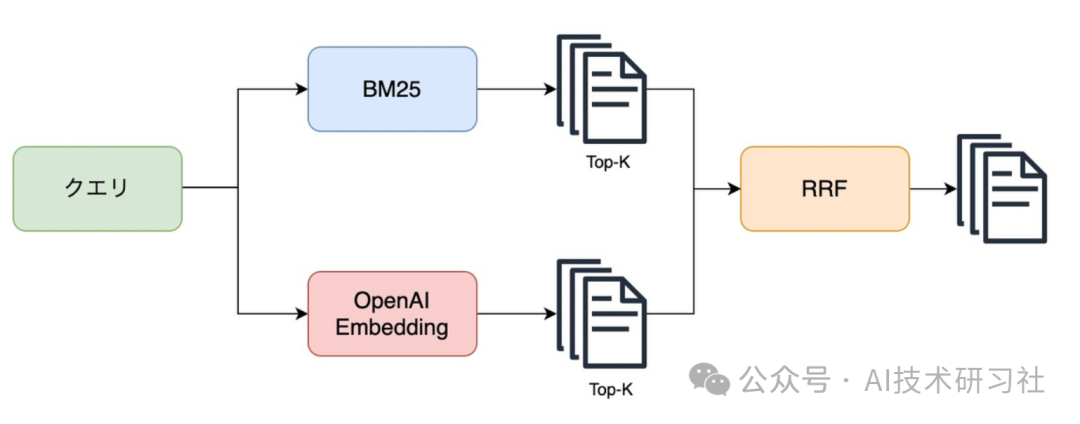
BM25(最佳匹配25)和RRF(倒数秩融合)是两种在检索增强生成(RAG)系统中用于改进大型语言模型(LLMs)检索步骤的技术。以下将详细介绍它们的工作原理及其在RAG流程中的作用。
BM25(最佳匹配25)
BM25是一种概率信息检索模型,它基于与查询的相关性对文档进行排名。作为传统TF-IDF模型的扩展,BM25在许多检索任务中表现出色,因此被广泛应用。
BM25的工作原理:
术语频率(TF):指一个术语在文档中出现的次数。BM25通过考虑文档长度来调整这一指标,避免较长的文档由于术语频繁出现而被错误地赋予更高权重。
反向文档频率(IDF):衡量一个术语在所有文档中出现的稀有程度。稀有术语会被赋予更高的权重,以反映其重要性。
规范化:根据文档长度进行调整,确保不同长度的文档之间可以公平比较。
在RAG中的应用:
索引:利用BM25对文档集合进行索引,预先计算术语频率和其他相关统计数据。
查询处理:当查询被发出时(例如,LLM需要额外的上下文信息),BM25根据与查询的相关性对每个文档进行评分。
排名:根据BM25评分对文档进行排序,并将评分最高的文档作为相关上下文供LLM使用。
RRF(倒数秩融合)
RRF是一种集成技术,能够将多个检索模型的结果组合在一起。尤其在不同检索模型各自擅长不同相关性方面的情况下,RRF非常有用。
RRF的工作原理:
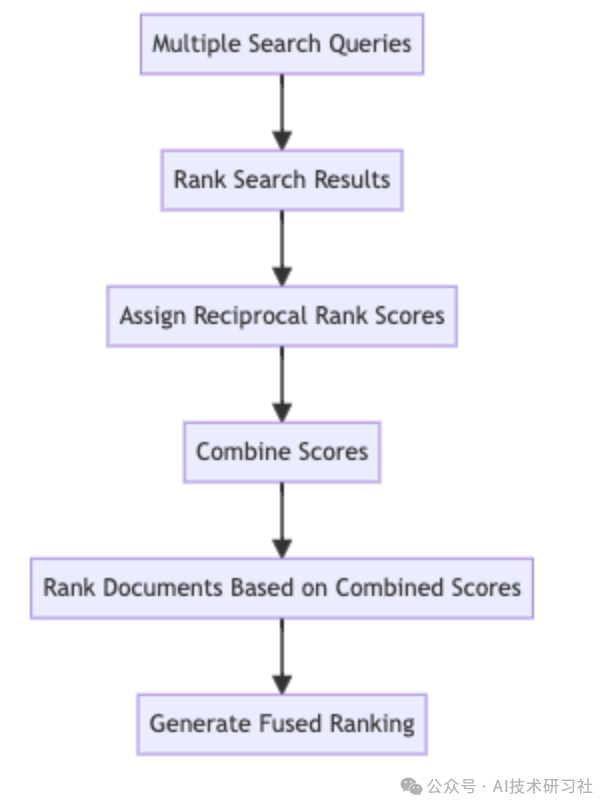
排名组合:每个检索模型生成一个文档的排名列表。RRF通过基于文档在每个排名列表中的位置为其分配分数,将这些排名列表结合在一起。
分数计算:文档的最终分数通过RRF公式计算得到。
融合:根据RRF综合分数对文档进行重新排名,生成一个包含各模型优势的最终文档列表。
score = 0.0for q in queries: # loop over queries send to different search enginesif d in result(q):score += 1.0 ( k + rank(result(q), d))return score# where# k is a ranking constant# q is a query in the set of queries# d is a document in the result set of q# result(q) is the result set of q# rank( result(q), d ) is d's rank within the result(q) starting from 1

def reciprocal_rank_fusion(queries, d, k, result_func, rank_func):return sum([1.0 / (k + rank_func(result_func(q), d)) if d in result_func(q) else 0 for q in queries])
在RAG中的应用:
多模型使用:使用多个检索模型(例如BM25、神经检索模型)独立检索并对查询文档进行排名。
秩融合:应用RRF合并这些模型的排名列表,生成一个更为稳健的相关文档排名列表。
上下文检索:将RRF融合后的排名靠前的文档提供给LLM,以生成更准确且相关的响应。
