




在docker创建mysql容器
docker pull mysql:5.7 拉取mysql容器
关系型数据库是依据关系模型来创建的数据库
a . 登录数据库 mysql -uroot -proot
b. 退出数据库 quit/exit
c.启动和停止mysql服务 net start mysql 启动服务 net stop mysql 停止服务
SQL:结构化查询语音
数据库中的表相当于Python中的类 ,如 学生类Student ---> 学生表student
数据库中数据表中的记录相当于Python中通过类创建的对象
Student("xiaoming",18,66)------------->xiaoming 18 66
数据库中的数据表中的字段相当于Python中定义的实例属性,如:name,age,score ------>
name varchar(20),age int, score int
SQL分类:
DDL:数据定义语言(Data Definition Language)
作用:针对数据库,数据表进行创建,修改和删除的操作
关键字:create alter drop
DML:数据操作语言(Data Manipulation Language)
作用:针对数据库的记录,字段进行增删改的操作
关键字:insert update delete/truncate
DQL:数据查询语言(Data Query Language)
作用:对数据库中的表,记录,字段进行查询
关键字:select ...from... where like order by group by having limit between...and
or in 等
DCL:数据库控制语言(Data Control Language)
作用:对数据库的安全级别和访问权限进行管理
关键字:begin commit rollback
DDL的用法
show databases; 查看已有的数据库
create database 库名; 创建数据库(建库)
create database 库名 character set 编码格式; 创建数据库的同时指定编码格式
create database 库名 charset 编码格式; 创建数据库的同时指定编码格式
create database if not exists 库名; 判断数据库是否存在,不存在才创建;
drop database 库名; 删除数据库【删库】
drop database if exists 库名; 判断数据库是否存在,存在才删除
alther database 库名 character set 编码格式; 修改数据库的编码格式
show create database 库名; 查询数据库的创建语句及编码格式
use 库名; 指定要使用的数据库【连接数据库】
select database(); 查看当前正在使用的数据库
DDL操作数据表
show tables; 查看当前数据库中所有的表;
create table 表名(字段名 字段类型 [约束],字段名 字段类型 [约束],...)
判断表是否已存在,不存在才创建;
create table if not exists 表名(字段名 字段类型 [约束],字段名 字段类型 [约束],...)
判断表是否已存在,不存在才创建
create table xxx (字段名 字段类型 [约束],字段名 字段类型 [约束],...) charset= xxx;
创建表,同时指明编码格式
drop table 表名; 删除表
drop table if exists 表名; 判断表是否已存在,存在才删除;
create table 新表名 like 被复制的表名; 复制表结构
alter table 旧表名 rename to 新表名; 修改表名
rename table 旧表名 to 新表名; 修改表名
show create table 表名; 查看表格的创建细节;
desc 表名; 查看表结构
修改表结构:(字段)
alter table 表名 add 新字段 字段类型 [约束]; 添加新字段
alter table 表名 character set; 新的编码格式
alter table 表名 drop 字段; 删除字段
alter table table_name modify 字段1 数据类型 first|after 字段2
first:设置成第一个
after 字段2:在指定字段2的后面
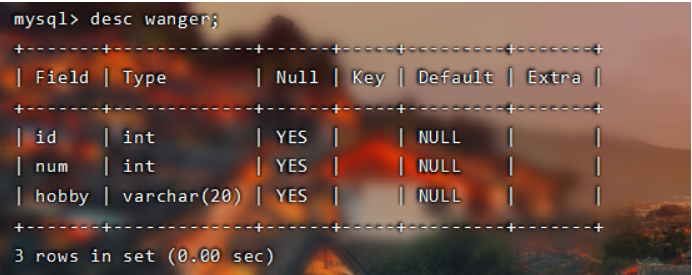
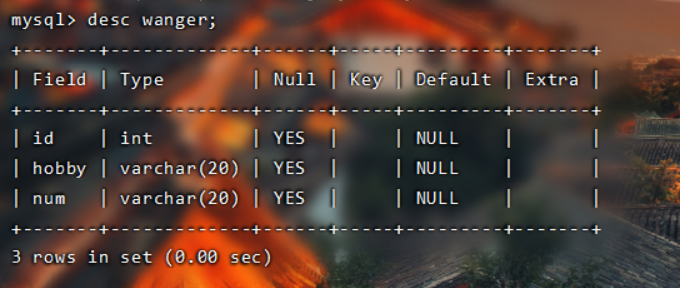
(alter table wanger modify num varchar(20) after hobby;) 修改字段的排名位置;

alter table 表名 modify 字段 类型; 修改字段数据类型
alter table 表名 change 旧字段名 新字段名 类型; 修改字段名
DML操作数据
select * from 表名 *---表示所有字段, 查询表中所有记录
insert 添加记录
insert into 表名 values(值1,值2,值3,...); 向所有字段添加数据
insert into 表名 (字段1,字段2,...) value (值1,值2,值3,); # values:插入单条数据
insert into 表名 (字段1,字段3, ...) values (值1,值2,....); # values:插入多条数据
向指定字段添加数据
insert into 表名 values (值1,值2,值3, ...),(值1,值2,值3,...)........;
批量添加 (所有字段)
删除记录delete
delete from 表名; 删除表中所有记录
truncate table 表名; 删除表中所有记录
delete from 记录表名 where 条件; 根据条件删除指定
[MySQL删除表的三种方式]
drop table drop是直接去除表信息,速度最快,但是无法找回数据
例如:删除user表--------------------drop table user;
truncate table truncate是删除表数据,不删除表的结构,速度排第二,但不能与where 一起使用
例如:删除user表---------------------truncate table user;
delete from delete 是删除表中的数据,不删除表结构,速度最慢,但可以与where 连用,可以删除指
定的行 例如:删除user表的所有数据 delete from user;
删除user表的指定记录 delete from user where use_id = 1;
希望删除表结构时,用drop;
希望保留表结构,但要删除所有记录时,用truncate;
希望保留表结构,但要删除部分记录时,用delete;
update 表名 set 字段名1 = 字段值1,字段名2 = 字段值2,... where 条件; 根据条件修改指定记录
update 表名 set 字段名1= 字段值1,字段名2= 字段值2,.... 修改所有记录
select database () 查看当前正在使用的数据库
(update stu set score=0 where score is null)
(update stu set score+10,grade='No' where score=0 )
DQL数据查询语言
查询返回的结果集是一张虚拟表
SELECT 列名 FROM 表名【WHERE ---> GROUP BY ---> HAVING----> ORDER BY]
select * from 表名; 查询全部
select 字段名1,字段名2,.... from 表名; 根据指定字段查询
create table emp( -> empno int, -> emoname varchar(30), -> gender varchar(10), -> job varchar(10), -> leaderno int, -> birth date, -> salary int, -> extra int, -> deptno int -> );
1.查询工资在2000~3000之间的员工信息
select * from emp where salary between 2000 and 3000;
select * from emp where salary>=2000 and salary <= 3000;
2.查询部门10中的员工信息
select *from emp where deptno=10;
3.查询工资为2000,3000,4000,5000的员工信息
select * from emo where salary=2000 or salary=3000 or salary=4000 or salary=5000;
select * from emp where salary in (2000,3000,4000,5000);
4.查询工资不为2000,3000,4000,5000的员工信息
select * from emp where salary not in (2000,3000,4000,5000);
5.查询没有奖金的员工信息
select * from emp where extra is null;
6.查询性别不为male的员工信息
select * from emp where gender<>'male';
select * from emp where gender!='male';
7.查询性别为'female'且在30号部门的员工信息
select * from emp where gender='female' and deptno=30;
8.查询性别为'male'或在10号部门的员工信息
select * from emp where gender='male' or deptno=10;
条件查询-where
主要结合where子句使用,在where关键字后跟上条件,查询时根据条件进行筛选
逻辑运算符
and、or、not
&&、||、!
关系运算符
大于、大于等于、小于、小于等于、等于(=)、不等于(!=、<>)
指定范围之内
between ... and … 注意:包头包尾【闭区间】
在指定列表中
in (值1,值2,值3,...)
not in不在指定列表中
空和非空
判断为空 is null
判断不为空 is not null
模糊查询-like
where等于子句号(=),用来精确匹配工作,如 author='习大大‘。但也有可能,我们要求过滤掉所有的结果,author应包含的名称:"习"。这时需要使用where子句结合like子句使用
通配符:
_:可以匹配任意一个字符
%:任意0~n个字符【n大于等于1】
alter table emp change emoname empname varchar(32);
1.查询名字为4个字母的员工信息
select * from emp where empname like "";
2.查询名字由5个字母组成,并且以t结尾的员工信息
select * from emp where empname like "___t";
3.查询名字以s开头的员工信息
select * from emp where empname like "s%";
4.查询名字中第二个字母是a的员工信息
select * from emp where empname like "_a%";
5.查询名字中包含b的员工信息
select * from emp where empname like "%b%";
字段控制查询
as: 可以给表、字段起别名,为了区分,为了简化
用法:select 字段 as 别名
注意:as 可以省略
infnull():将null转化为其他数据
distinct: 去除重复记录
对多个字段同时去重,distinct只需要写一次,多个字段的值必须都相同才能同时去重
as 一般用于多表查询,子查询以及子连接中
select * from emp as e; 给表名起别名
select empname as n from emp;
select e.birth,e.empname from emp as e; 给字段起别名
select empname n from emp;
select empnaem 姓名,salary 工资 from emp;sel
# 2.distinct
insert into emp values(7566,'jones','female','managen',7839,'1981-04-02',2975,null,30);
insert into emp values(7654,'martin','male','salesman',7698,'1981-09-28',1250,1400,30);
# 只对一个字段去重
select distinct empno from emp;
# 对多个字段同时去重,distinct只需要写一次,多个字段的值必须都相同才能同时去重
select distinct empno,empname,salary from emp;
insert into emp values(7566,'aaaa','female','managen',7839,'1981-04-02',2975,null,30);
select distinct empno,empname,salary from emp;
# 3.ifnull()
select extra from emp;
select ifnull(extra,0) from emp;
select salary + ifnull(extra,0) as 实发工资 from emp;
排序-order by
我们已经看到使用SQL SELECT命令从MySQL表中获取数据。当选择数据行,MySQL服务器可以自由地返回它们的顺序,除非有指示它按照怎样的结果进行排序。但是排序结果可以通过增加一个ORDER BY子句设定列名称或要排序的列。
order by :指定数据返回的顺序,用法:select * from 表 order by 字段 排序方式
asc:升序【Ascending】,默认
desc:降序【Descending】
select * from emp order by salary asc;
select * from emp where gender='male' and empname like '_l%' order by salary asc;
select avg(salary) from emp where gender = 'female' group by deptno order by avg(salary);
分组查询-group by
group by:分组查询
where :当。。。。表示条件
having:有….,表示条件
注意:分组之后查询的字段格式应该是:分组字段,聚合函数
【面试题】where和having 的区别
a.where表示在分组之前条件限制条件,having表示在分组之后添加限制条件
b.where之后不能跟聚合函数,但是,having后可以使用聚合函数进行筛选
# 1.查询每个部门的平均工资
select deptno,avg(salary) from emp group by deptno;
# 2.查询男员工和女员工的最高收入
select gender,max(salary) from emp group by gender;
# 3.查询每个部门女性员工的平均工资,以平均工资进行降序排序
select deptno,avg(salary) from emp where gender='female' group by deptno order by avg(salary) desc;
# 4.查询平均工资高于2500的部门
select deptno,avg(salary) from emp group by deptno having avg(salary)>2500;
# 5.查询每个部门男性员工的平均工资大于2800的部门
select deptno,avg(salary) from emp where gender='male' group by deptno having avg(salary)>2800;
分页查询-limit
limit:用来限定查询结果的起始行,以及总行数
语法:limit i,n
说明:i表示起始的索引,n表示需要查看的条数
# 1,查询前两条数据
select * from emp limit 2;
select * from emp limit 0,2;
# 2.从索引为2的位置开始,向后查询两条
# 或者 从第三条开始,查询两条
select * from emp limit 2,2;
select * from emp limit 5,4;
