




关于相关的链路追踪介绍,大家可以直接看阿里官网的介绍,比较详细,我这里搬运一下了!感谢阿里云官网的提供介绍!
建议直接看阿里云官网的介绍:https://help.aliyun.com/document_detail/90277.html
我这里主要提炼一下关键概念来帮助自己梳理:
1 链路追踪作用
分布式集群微服务化下系统问题定位 追踪请求的完整调用链路 收集链路中的性能数据 提供了完整的调用链路还原 调用请求量统计 链路拓扑、应用依赖分析 收集的链路可直接用于日志分析
2 链路追踪步骤
代码埋点 数据上报 数据存储 查询展示
3 分布式追踪协议(OpenTracing)
特点:统一接口与平台,语言无关
一些概念理解:
Trace(调用链):对一个链路调用链的定义,也可以表述为代表一个事务或者流程在(分布式)系统中的执行过程;
Span(归属调用链中某个过程的执行过程):是一个逻辑执行单元,它代表调用链中被命名并计时的连续性执行片段。
一条 Trace 可以认为一个有多个 Span 组成的有向无环图(Directed Acyclic Graph-简写:DAG图)
Span之前存在父子层级的概念
Childof 描述的是谁是谁的子层Span
FollowsFrom描述的是 我是来自哪个父层Span
References:Span之间的关系
OpenTracing数据模型
关于Tracer接口:
作用:
用于创建Span(startSpan函数) 解析上下文(Extract函数) 透传上下文(Inject函数)
关于Span对象:
来自官网的图:

Operation name:操作名称 (也可以称作Span name)。
Start timestamp:起始时间。
Finish timestamp:结束时间。
Span tag:一组键值对构成的Span标签集合。键值对中,键必须为String,值可以是字符串、布尔或者数字类型。
Span log:一组Span的日志集合。每次Log操作包含一个键值对和一个时间戳。键值对中,键必须为String,值可以是任意类型。
SpanContext: Span上下文对象。每个SpanContext包含以下状态:
要实现任何一个OpenTracing,都需要依赖一个独特的Span去跨进程边界传输当前调用链的状态(例如:Trace和Span的ID)。 Baggage Items是Trace的随行数据,是一个键值对集合,存在于Trace中,也需要跨进程边界传输。 References(Span间关系):相关的零个或者多个Span(Span间通过SpanContext建立这种关系)。
4 数据上报

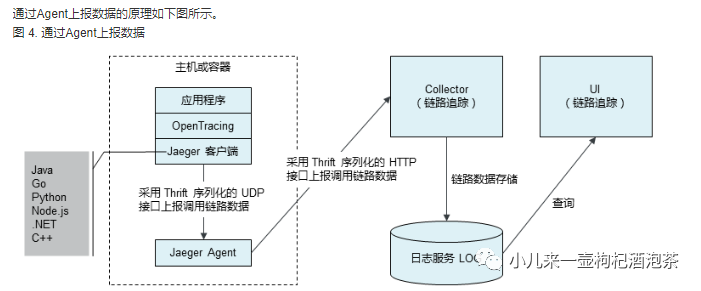
5 链路追踪产品:
Zipkin Jaeger skywalking
不做对比,使用为主。
6 Jaeger-实践记录(通过agent上报方式)
6.1 Jaeger一些概念介绍
Jaeger 架构图:
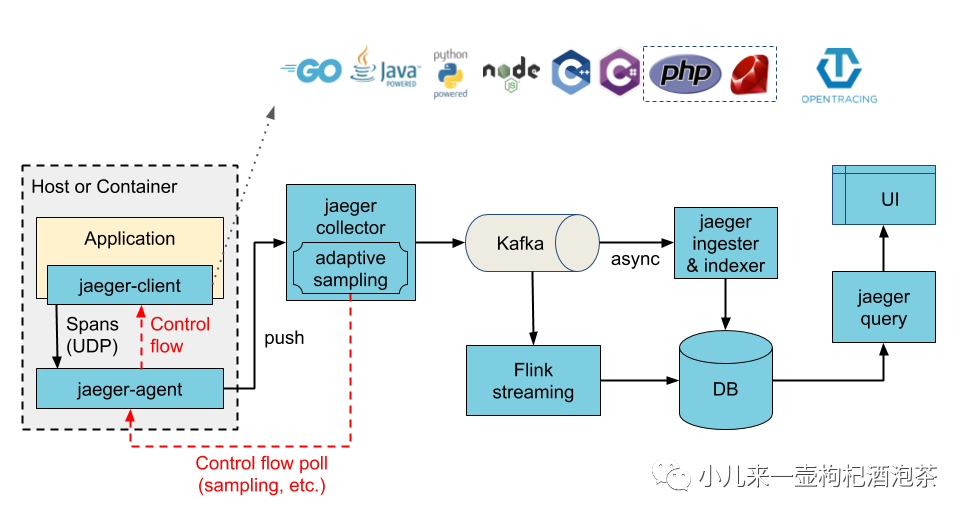
来自官网的图:
一些概念:
Jaeger Client - 为不同语言实现了符合 OpenTracing 标准的 SDK。应用程序通过 API 写入数据,client library 把 trace 信息按照应用程序指定的采样策略传递给 jaeger-agent。
Agent - 是一个监听在 UDP 端口上接收 span 数据的网络守护进程,它会将数据批量发送给 collector。它被设计成一个基础组件,推荐部署到所有的宿主机上。Agent 将 client library 和 collector 解耦,为 client library 屏蔽了路由和发现 collector 的细节。
Collector - 接收 jaeger-agent 发送来的数据,然后将数据写入后端存储。Collector 被设计成无状态的组件,因此您可以同时运行任意数量的 jaeger-collector。
Data Store - 后端存储被设计成一个可插拔的组件,支持将数据写入 cassandra、elastic search。
Query - 接收查询请求,然后从后端存储系统中检索 trace 并通过 UI 进行展示。Query 是无状态的,您可以启动多个实例,把它们部署在 nginx 这样的负载均衡器后面。
采样速率
生产环境系统性能很重要,所以对于所有的请求都开启 Trace 显然会带来比较大的压力,另外,大量的数据也会带来很大存储压力。
为此,jaeger 支持设置采样速率,根据系统实际情况设置合适的采样频率。
Jaeger 官方提供了多种采集策略,使用者可以按需选择使用
const,全量采集,采样率设置0,1 分别对应打开和关闭 probabilistic ,概率采集,默认十份之一,0~1之间取值 rateLimiting ,限速采集,每秒只能采集一定量的数据 remote ,一种动态采集策略,根据当前系统的访问量调节采集策略
关于采样率
另一种文字解释说法,当前支持四种采样率设置:
固定采样(sampler.type=const)sampler.param=1 全采样, sampler.param=0 不采样; 按百分比采样(sampler.type=probabilistic)sampler.param=0.1 则随机采十分之一的样本; 采样速度限制(sampler.type=ratelimiting)sampler.param=2.0 每秒采样两个traces; 动态获取采样率 (sampler.type=remote) 这个是默认配置,可以通过配置从 Agent 中获取采样率的动态设置。
6.2 实践
安装Jaeger 服务
使用对应Jaeger客户端进行对接
6.2.1 安装Jaeger 服务
生产环境的话,需要考虑的问题比较多,如果为了方便进行实验,直接的使用Docker进行安装all-in-one。
$ docker run -d --name jaeger \
-e COLLECTOR_ZIPKIN_HTTP_PORT=9411 \
-p 5775:5775/udp \kaixiao
-p 6831:6831/udp \
-p 6832:6832/udp \
-p 5778:5778 \
-p 16686:16686 \
-p 14268:14268 \
-p 9411:9411 \
jaegertracing/all-in-one:latest
另一个快速方式是:
docker run -d --name=jaeger -p6831:6831/udp -p16686:16686 jaegertracing/all-in-one:latest
然后访问:
http://localhost:16686/
但:这个docker镜像封装的jaeger是把数据放在内存中的,仅用于测试,正式使用需指定后端存储。
其实官网也提供了all-in-one一个window下的一个exe的,当然这个也是为了方便,仅用于测试的。为了方便,我这里使用exe的。


然后启动我们的服务:必须使用cmd的方式启动:
D:\code\开发工具\jaeger-1.28.0-windows-amd64.tar(1)\jaeger-1.28.0-windows-amd64>jaeger-all-in-one.exe
然后访问我们
http://localhost:16686

6.2.2 使用对应Jaeger-python客户端进行对接
PS:all-in-one的模式下使用的agnet的上报数据的方式!
然后这里参考来自阿里云的示例应用进行实验:
步骤1:安装依赖包
jaeger-client==4.8.0
opentracing==2.4.0
步骤2:启动测试示例
import logging
import time
from jaeger_client import Config
def construct_span(tracer):
with tracer.start_span('AliyunTestSpan') as span:
span.log_kv({'event': 'test message', 'life': 42})
print("tracer.tages: ", tracer.tags)
with tracer.start_span('AliyunTestChildSpan', child_of=span) as child_span:
span.log_kv({'event': 'down below'})
return span
if __name__ == "__main__":
log_level = logging.DEBUG
logging.getLogger('').handlers = []
logging.basicConfig(format='%(asctime)s %(message)s', level=log_level)
config = Config(
config={ # usually read from some yaml config
'sampler': {
'type': 'const',
'param': 1,
},
'local_agent': {
# 注意这里是指定了JaegerAgent的host和port。
# 根据官方建议为了保证数据可靠性,JaegerClient和JaegerAgent运行在同一台主机内,因此reporting_host填写为127.0.0.1。
'reporting_host': '127.0.0.1',
'reporting_port': 6831,
},
'logging': True,
},
#这里填写应用名称
service_name="mytest3",
validate=True
)
# this call also sets opentracing.tracer
tracer = config.initialize_tracer()
span = construct_span(tracer)
time.sleep(2) # yield to IOLoop to flush the spans - https://github.com/jaegertracing/jaeger-client-python/issues/50
tracer.close() # flush any buffered spans
步骤3:查看我链路控制台信息
查看一个trace流程:
选择要查看的服务:

可以选择要查看一个过程,也可以不选,默认全部

然后点击查讯链路:
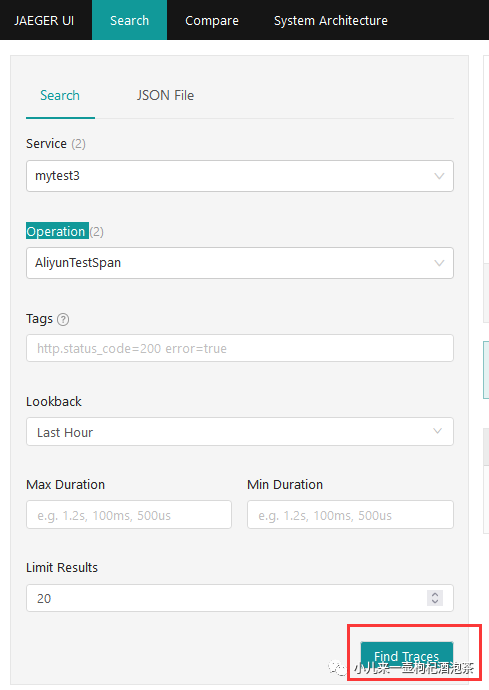
查看结果:
点击查看结果明细信息:

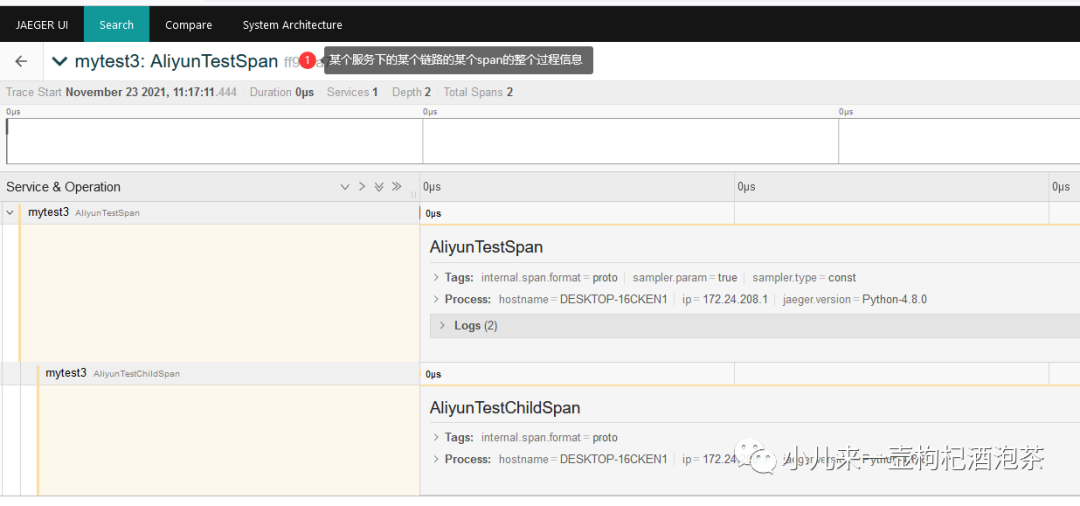

6.2.3 业务链路耗时分析
完整代码:
import logging
import time
from jaeger_client import Config
def construct_span(tracer):
# 定义span的名称为AliyunTestSpan:
with tracer.start_span('AliyunTestSpan') as span:
# 设置这个span传递的日志信息
span.log_kv({'event': 'test message', 'life': 42})
print("tracer.tages: ", tracer.tags)
time.sleep(1)
# 定义AliyunTestSpan的子Span,类似第一个追踪的数据的子层级
with tracer.start_span('AliyunTestChildSpan-1', child_of=span) as child_span:
time.sleep(2)
span.log_kv({'event': 'down below'})
child_span.log_kv({'event': 'child_span-down below'})
with tracer.start_span('AliyunTestChildSpan-2', child_of=span) as child_span:
time.sleep(3)
span.log_kv({'event': 'down below'})
child_span.log_kv({'event': 'child_span-down below'})
with tracer.start_span('AliyunTestChildSpan-3', child_of=child_span) as Span3_child_span:
time.sleep(4)
span.log_kv({'event': 'down below'})
Span3_child_span.log_kv({'event': 'Span3_child_span-down below'})
return span
if __name__ == "__main__":
# 定义日志输出的登记
log_level = logging.DEBUG
logging.getLogger('').handlers = []
# 配置日志默认输出格式
logging.basicConfig(format='%(asctime)s %(message)s', level=log_level)
# Jaeger配置信息
config = Config(
# usually read from some yaml config---意思是配置信息其实可以从某个yaml文件进行读取
config={
# sampler 采样
'sampler': {
'type': 'const', # 采样类型
'param': 1, # 采样开关 1:开启全部采样 0:关闭全部
},
# 配置链接到我们的本地的agent,通过agent来上报
'local_agent': {
# 注意这里是指定了JaegerAgent的host和port。
# 根据官方建议为了保证数据可靠性,JaegerClient和JaegerAgent运行在同一台主机内,因此reporting_host填写为127.0.0.1。
'reporting_host': '127.0.0.1',
'reporting_port': 6831,
},
'logging': True,
},
#这里填写应用名称---服务的名称
service_name="mytest3",
validate=True
)
# this call also sets opentracing.tracer
tracer = config.initialize_tracer()
#创建一个自定义的额span
span = construct_span(tracer)
# 根据官网提示 这里是必须的存在,因为它是基于tornado的异步的方式来处理数据上报!
time.sleep(2) # yield to IOLoop to flush the spans - https://github.com/jaegertracing/jaeger-client-python/issues/50
tracer.close() # flush any buffered spans
查看我们的链路追踪图示:
查看span数:

查看链路的业务耗时:

7 fastapi整合追踪链路
刚好之前有网友提取聊起关于fastapi整合链路追踪的问题,他说他使用的框架是:fastapi_contrib,我翻开了一下它源码,主要是它刚好了整合了我们的相关链路追踪,其实仔细的深入一下,也只是依赖我们的上面安装的库,无非是对它使用中间件进行了封装。不过这个库封装的质量挺不错的!值的学习学习哟!
为了保持原样,我这里直接使用这个来实践:
步骤1:安装依赖库
pip install fastapi_contrib[all]
顺便安装一下:
pip install uvicorn
步骤2:示例编写:
#!/usr/bin/evn python
# -*- coding: utf-8 -*-
from fastapi import FastAPI
from fastapi_contrib.tracing.middlewares import OpentracingMiddleware
from fastapi_contrib.tracing.utils import setup_opentracing
app = FastAPI()
@app.on_event('startup')
async def startup():
setup_opentracing(app)
app.add_middleware(OpentracingMiddleware)
if __name__ == '__main__':
# 启动服务
import uvicorn
uvicorn.run('fasmain:app', host='0.0.0.0', port=19085,reload=True, access_log=False, workers=1, use_colors=True)
步骤3:分析源码配置
1 : setup_opentracing - 再启动时候进行相关追踪实例化,并注册到应用上下文中
2 : 里面配置其实和我们的上面的简单示例一样是进行相关的初始化的操作,唯一的区别就是使用了异步的支持。
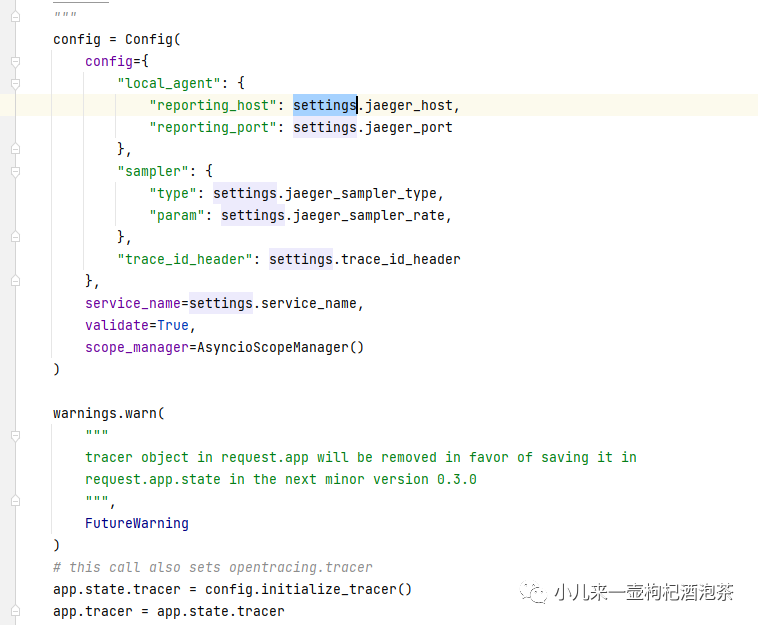
3 : 配置我们的项目信息
Jaeger 官方提供了多种采集策略,使用者可以按需选择使用
const,全量采集,采样率设置0,1 分别对应打开和关闭 probabilistic ,概率采集,默认时份之一,0~1之间取值 rateLimiting ,限速采集,每秒只能采集一定量的数据 remote ,一种动态采集策略,根据当前系统的访问量调节采集策略
为了方便我们默认全量采集:
然后上代码:
from fastapi import FastAPI
from fastapi_contrib.tracing.middlewares import OpentracingMiddleware
from fastapi_contrib.tracing.utils import setup_opentracing
from fastapi_contrib.conf import settings
app = FastAPI()
@app.on_event('startup')
async def startup():
# 'reporting_host': '127.0.0.1',
# 'reporting_port': 6831,
settings.jaeger_host = '127.0.0.1'
settings.jaeger_port = 6831
settings.service_name = "fastapi_contrib"
settings.trace_id_header = "X-TRACE-ID"
settings.jaeger_sampler_type = "const"
settings.jaeger_sampler_rate= 1
setup_opentracing(app)
app.add_middleware(OpentracingMiddleware)
@app.get("/getas")
def ceshi():
return "ok"
if __name__ == '__main__':
# 启动服务
import uvicorn
uvicorn.run('fasmain:app', host='127.0.0.1', port=19085,reload=True, access_log=False, workers=1, use_colors=True)
开始启动我们的接口请求,发现请求的链路一直没记录,没出现。!!!
奇葩!各自安装其他可以之后:
pip install Starlette-Opentracing -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install opentracing-instrumentation -i https://pypi.tuna.tsinghua.edu.cn/simple
然后回复到原来的代码。查看链路可以出现了!!!!有点奇葩!不知道是不是我的服务问题还是啥!!
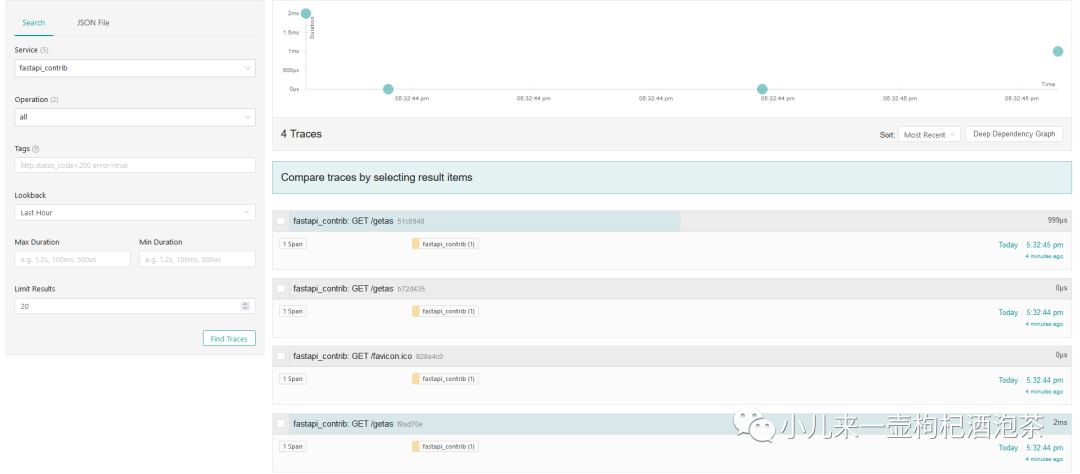
然后接下就是跨服的传递我们的链路:
A接口请B接口的事情:
步骤1:拷贝两份我们的服务,分别该相关的端口启动后:
请求A接口某个接口的时候----》使用request请求B服务的某个接口,然后观察我们的链路:
首先A接口的示例代码如下:
#!/usr/bin/evn python
# -*- coding: utf-8 -*-
from fastapi import FastAPI
from fastapi_contrib.tracing.middlewares import OpentracingMiddleware
from fastapi_contrib.tracing.utils import setup_opentracing
from fastapi_contrib.conf import settings
from fastapi import Request
from opentracing.propagation import Format
import requests
app = FastAPI()
@app.on_event('startup')
async def startup():
# 'reporting_host': '127.0.0.1',
# 'reporting_port': 6831,
settings.jaeger_host = '127.0.0.1'
settings.jaeger_port = 6831
settings.service_name = "fastapi_contrib"
settings.trace_id_header = "X-TRACE-ID"
settings.jaeger_sampler_type = "const"
settings.jaeger_sampler_rate= 1
setup_opentracing(app)
app.add_middleware(OpentracingMiddleware)
@app.get("/getas")
def ceshi(request:Request):
'''测试服务间调用'''
url = 'http://127.0.0.1:19086/getas2'
# 拿到当前生效的tracer
tracer = request.state.opentracing_tracer
# 拿到当前有效的span
span = request.state.opentracing_span
# inject span 进 requests header
headers = {}
# 跨度上下文呢 (SpanContext),SpanContext负责子微服务系统边界传递数据。它主要包含两部分:
# 和实现无关的状态信息,例如Trace ID,Span ID
# 行李项 (Baggage Item)。如果把微服务调用比做从一个城市到另一个城市的飞行,
# 那么SpanContext就可以看成是飞机运载的内容。Trace ID和Span ID就像是航班号,而行李项就像是运送的行李。每次服务调用,用户都可以决定发送不同的行李。
# SpanContext:
# - trace_id:"abc123"
# - span_id:"xyz789"
# - Baggage Items:
# - special_id:"vsid1738"
#
# OpenTracing定义了两个方法Inject和Extract用于SpanContext的注入和提取。
tracer.inject(span, Format.HTTP_HEADERS, headers)
# inject之后,实际 headers = {'uber-trace-id': '6997ed0a6a74f050:bf49be2de63d86e7:e02975aab05fd358:1'}
print(headers)
res = requests.get(url, headers=headers)
print(res.text)
return "ok"
if __name__ == '__main__':
# 启动服务
import uvicorn
uvicorn.run('fasmain:app', host='127.0.0.1', port=19085,reload=True, access_log=False, workers=1, use_colors=True)
然后是B接口的服务:
#!/usr/bin/evn python
# -*- coding: utf-8 -*-
"""
-------------------------------------------------
文件名称 : fasmain
文件功能描述 : 功能描述
创建人 : 小钟同学
创建时间 : 2021/11/23
-------------------------------------------------
修改描述-2021/11/23:
-------------------------------------------------
"""
from fastapi import FastAPI
from fastapi_contrib.tracing.middlewares import OpentracingMiddleware
from fastapi_contrib.tracing.utils import setup_opentracing
from fastapi_contrib.conf import settings
app = FastAPI()
@app.on_event('startup')
async def startup():
# 'reporting_host': '127.0.0.1',
# 'reporting_port': 6831,
settings.jaeger_host = '127.0.0.1'
settings.jaeger_port = 6831
settings.service_name = "nihao"
settings.trace_id_header = "X-TRACE-ID"
settings.jaeger_sampler_type = "const"
settings.jaeger_sampler_rate= 1
setup_opentracing(app)
app.add_middleware(OpentracingMiddleware)
@app.get("/getas2")
def ceshi():
return "我是服务2"
if __name__ == '__main__':
# 启动服务
import uvicorn
uvicorn.run('fasmain2:app', host='127.0.0.1', port=19086,reload=True, access_log=False, workers=1, use_colors=True)
然后请A接口:
http://127.0.0.1:19085/getas
此时A接口里面请求了B接口的地址:
http://127.0.0.1:19086/getas2
再观察一下我们的链路记录请求情况:
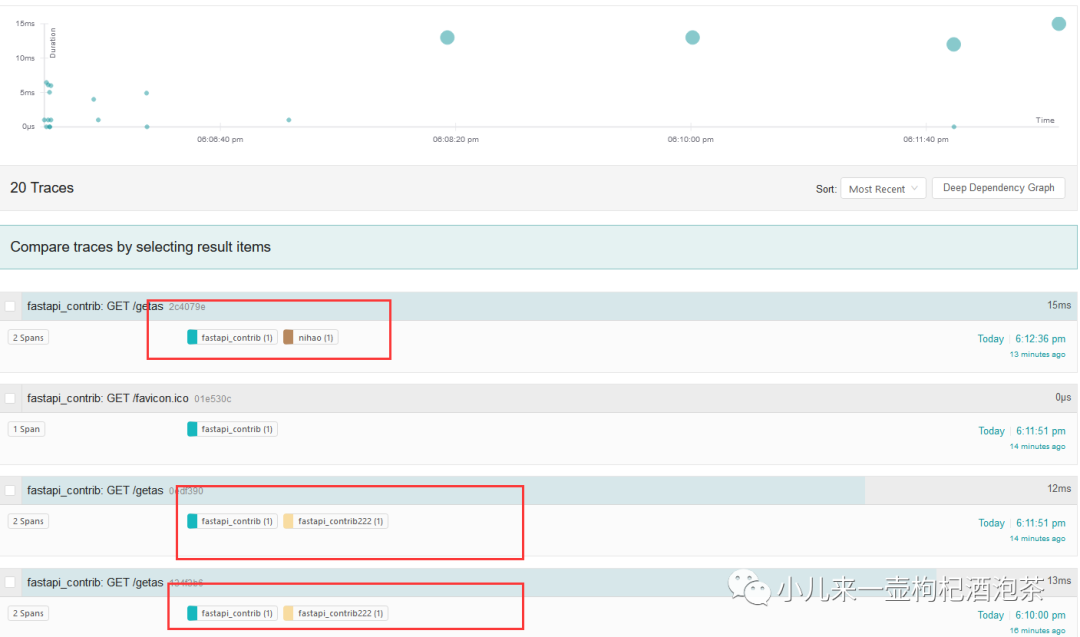 此时可以记录到我们的链路情况了
此时可以记录到我们的链路情况了
总结:
跨服都需要传递跨度上下文呢 (SpanContext),SpanContext负责子微服务系统边界传递数据 它主要包含两部分: 和实现无关的状态信息,例如Trace ID,Span ID 行李项 Baggage Item
资料来源:
【官网】 https://www.jaegertracing.io/docs/1.12/getting-started/
【链路追踪解释】 https://help.aliyun.com/document_detail/90277.html
【安装和介绍】https://blog.csdn.net/qq_27384769/article/details/109639915
【完整示例介绍】 https://blog.csdn.net/sc_lilei/article/details/107834597
总结
以上仅仅是个人结合自己的实际需求,做学习的实践笔记!如有笔误!欢迎批评指正!感谢各位大佬!
结尾
END
简书:https://www.jianshu.com/u/d6960089b087
掘金:https://juejin.cn/user/2963939079225608
公众号:微信搜【小儿来一壶枸杞酒泡茶】
小钟同学 | 文 【欢迎一起学习交流】| QQ:308711822
