






Raft 成员的本质是日志复制和状态机。Raft 成员之间通过复制日志来实现数据同步;Raft 成员在不同条件下切换自己的成员状态,其目标是选出 leader 以提供对外服务;
Raft 是一个表决系统,它遵循多数派协议,在一个 Raft Group 中,某成员获得大多数投票,它的成员状态就会转变为 leader。也就是说,当一个 Raft Group 还保有大多数节点(majority)时,它就能够选出 leader 以提供对外服务。
副本数目的选择
若 n 为奇数,该 Raft 组可以容忍 (n-1)/2 个成员同时发生故障;
若 n 为偶数,该 Raft 组可以容忍 n/2 -1 个成员同时发生故障。
避免造成存储空间的浪费:三成员可以容忍 1 成员故障,增加 1 个成员变为 4 成员后,也只能容忍 1 成员故障,容灾能力维持不变;
当成员数为偶数时,如果发生了一个网络隔离,刚好将隔离开的两侧的成员数划分为两个 n/2 成员的话,由于两侧都得不到大多数成员,因此都无法选出 leader 提供服务,这个网络隔离将直接导致整体的服务不可用;
当成员数为奇数时,如果发生了一个网络隔离,网络隔离的两侧中总有一侧能分到大多数的成员,可以选出 leader 继续提供服务。
想克服任意 1 台服务器的故障,应至少提供 3 台服务器;
想克服任意 1 个机柜的故障,应至少提供 3 个机柜;
想克服任意 1 个数据中心(机房)的故障,应至少提供 3 个数据中心;
想应对任意 1 个城市的灾难场景,应至少规划 3 个城市用于部署。

sync:同步复制,此时 DR 与 Primary 至少有一个节点与 Primary 同步,Raft 保证每条 log 按 label 同步复制到 DR;
async:异步复制,此时不保证 DR 与 Primary 完全同步,Raft 使用经典的 majority 方式复制 log;
sync-recover:恢复同步,此时不保证 DR 与 Primary 完全同步,Raft 逐步切换成 label 复制,切换成功后汇报给 PD。
当集群一切正常时,会进入同步复制模式来最大化的保障灾备机房的数据完整性;
当机房间网络断连或灾备机房发生整体故障时,在经过一段提前设置好的保护窗口之后,集群会进入异步复制状态,来保障业务的可用性;
当网络重连或灾备机房整体恢复之后,灾备机房的 TiKV 会重新加入到集群,逐步同步数据并最终转为同步复制模式;
当主机房整体故障且无法恢复时,使用灾备机房的副本重建集群来恢复一致性的数据。
异步切同步
1. PD 通过定时检查 TiKV 的心跳信息来判断 TiKV 是否恢复连接;
2. 如果宕机数小于 Primary/DR 各自副本的数量,意味着可以切回同步了;
3. PD 将 sync-recover 状态下发给所有 TiKV;
4. TiKV 的所有 region 逐步切换成双机房同步复制模式,切换成功后状态通过心跳同步信息给 PD;
5. PD 记录 TiKV 上 region 的状态并统计恢复进度:
A) 所有 Regoin 都恢复后,PD 将状态切换为 sync,将 sync 状态下发给所有 TiKV;
B) 如果在过程中又发生宕机,执行同步切异步流程。
当同步复制转异步复制后降级提供服务时,发生主机房整体故障的特殊情况,RPO 不为 0。
两机房网络断开时长小于 wait-store-timeout 所设置的时间时,RTO 为网络断开时间和 30s(基于默认的 Raft 心跳设置)中更大的那个;
两机房网络断开或灾备机房整体宕机时,RTO 为阻塞窗口 wait-store-timeout 所设置的时间;
主机房整体宕机时,RTO 为报警响应时间 + 重建 PD 操作时间(熟练 DBA 分钟级) + 恢复 TiKV 单副本时间(熟练 DBA 分钟级)+ 集群验证时间(用于验证数据库可用,应用连接顺畅),恢复后的单副本集群可以直接提供服务,后续的扩容以及扩副本操作可以在线执行。

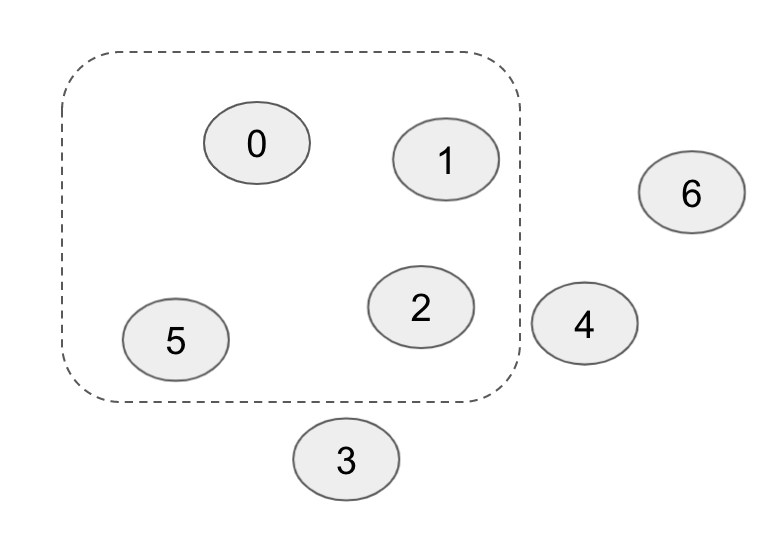
如图所示,0、1、2、5 成员在一个可用区,剩下的在另一可用区。一般的共识算法通过大多数成员(majority)来实现唯一修改提交并且容忍少数副本(minority)丢失。但是在跨双可用区的情况下,奇数成员的 majority 不一定能容忍可用区损坏。写入只同步在了0、1、2、5 这些成员时,此时足够形成 majority 提交写入。但若之后该可用区损坏,另一可用区上没有该写入,那么就造成了数据丢失。
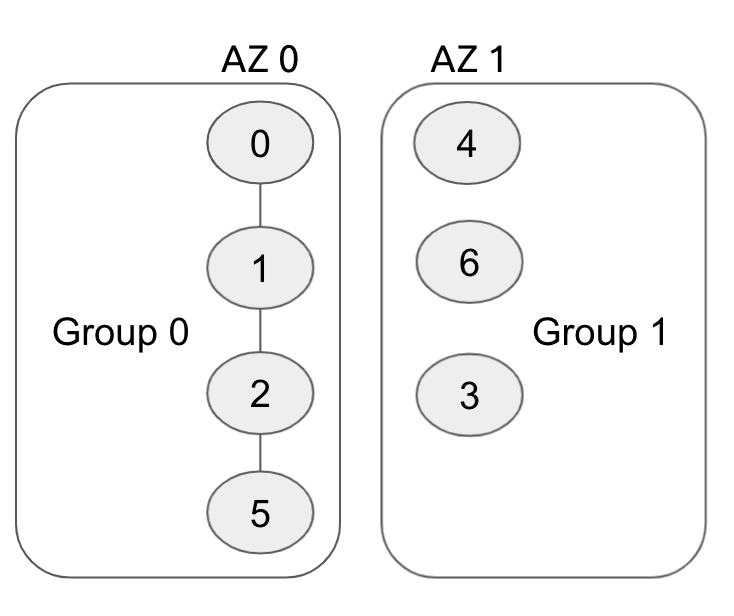
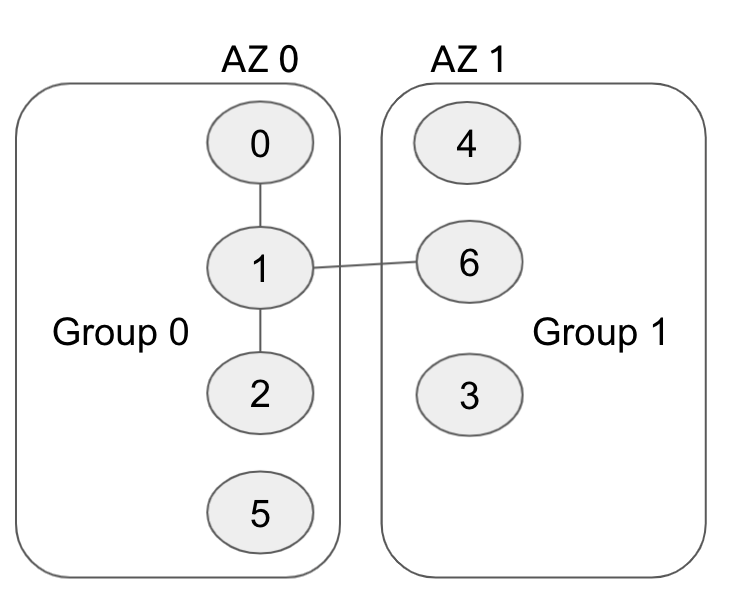
如图所示,图中的 0、1、2、6 就是一个合格的组合。它一共包含 4 个成员,满足了大多数成员落实的要求;这四个成员分布在两个不同的组 AZ 0、AZ 1 中,因此它是一个符合要求的组合。
当阻塞窗口设置为 0 时,两个可用区将保持在异步复制状态;
当阻塞窗口设置为 1 分钟时,网络断连或灾备可用区发生整体故障的最初 1 分钟内,主可用区会自动阻塞新的请求,来保障双可用区复制的同步性;
当阻塞窗口设置为一个足够大的时间时(如 1 年),网络断连或灾备可用区发生整体故障的 1 年内,都会阻塞新的请求,在实际使用中可以认为双可用区处于持久的同步复制状态。
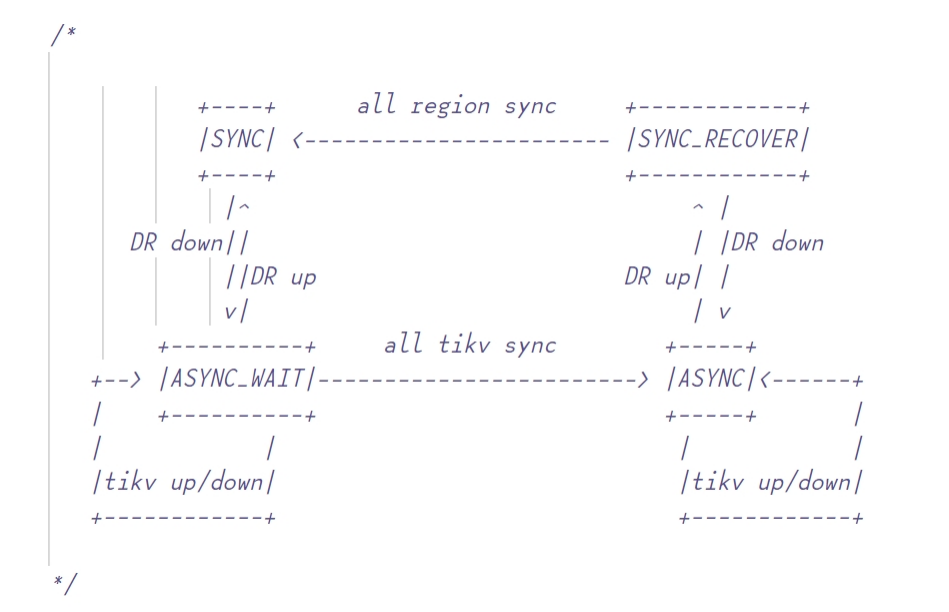
同步复制状态:即图中“双可用区同步模式”,此时 Raft 在提交组(commit group)模式下工作,以确保灾备可用区具备同步(RPO=0)的数据;
异步复制状态:即图中“大多数成员模式”,此时采用经典的 Raft 大多数成员(majority )模式做复制,不保证灾备可用区具备同步的数据;
恢复同步状态:即图中“恢复同步模式”,此时逐步追平数据,追数过程中不保证灾备可用区具备同步的数据。
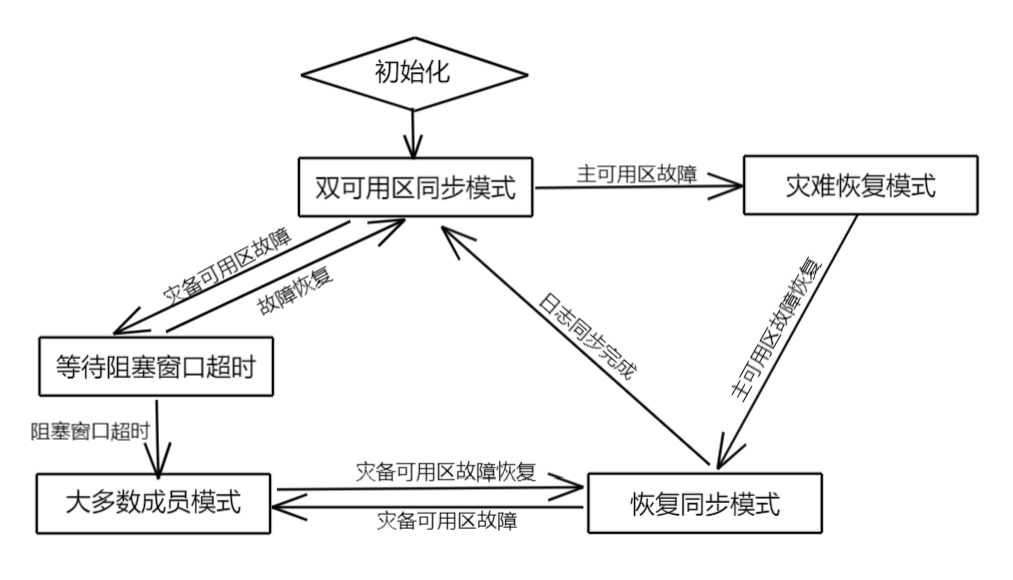
当集群一切正常时,会转换为同步复制状态来最大化保障灾备可用区的数据完整性;
当两个可用区间的网络断连或灾备可用区发生整体故障时,在经过一段提前设置好的阻塞窗口之后,集群会进入异步复制状态,来保障业务的可用性
当网络重连或灾备可用区整体恢复之后,灾备可用区的成员会重新加入到集群,逐步同步数据并最终转为同步复制模式;
当主可用区整体故障且无法恢复时,使用灾备可用区的成员来恢复一致性的数据。
前面我们知道了通过 Raft commit group 可以保证在灾备可用区至少有一个副本有最新的数据。当主可用区整体故障且无法恢复时,灾备可用区的剩余副本就可以继续提供一致性的服务。但有个问题是,灾备可用区只有少数派副本,按照 Raft 的多数派规则无法选出 Leader。
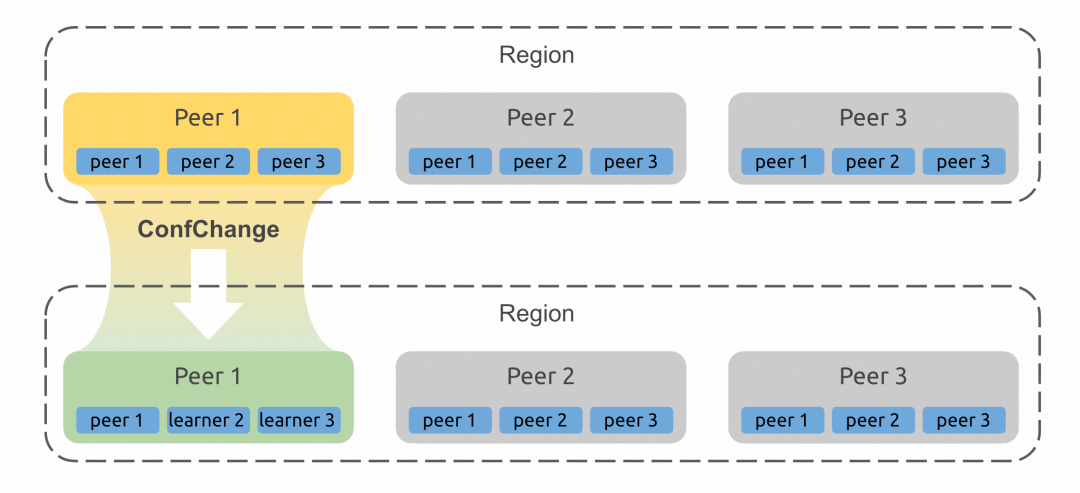
此时我们引入少数派灾难恢复的机制,通过 PD 收集灾备可用区上的所有副本信息,判断出来 Region 的哪个副本有最新数据,然后绕过 Raft 规则手动指派其为 Leader,并执行 Conf Change 将成员列表中主可用区的副本变成 Learner。Learner 不参与多数派的投票,那么之后灾备可用区的这些副本也能形成多数派正常提供服务。
如下图以三副本为例,对于该 Region 假设 Peer 2 和 Peer 3 在主可用区,Peer 1 在灾备可用区。当主可用区故障后,Peer 1 和 Peer 2 不可用,从 Peer 1 的视角看,整个 Raft Group 有三个成员,此时无法形成多数派选举处 Leader。当手动指定了 Peer1 为 Leader 后,它就可以执行 Conf Change 将 Peer 2 和 Peer 3 变成 Learner,那么 Peer 1 自己即是多数派,后面能正常的提供服务。

同城只有双中心;
网络延迟低且稳定的环境(两个数据中心距离在 50 km 以内,通常位于同一个城市或两个相邻城市,数据中心间的网络连接延迟小于 1.5 ms,且网络质量可保证无频繁丢包)。
具备同城双数据中心高可用和容灾能力;
当处于同步复制状态(sync)的集群发生单 IDC 不可用时,可进行 RPO = 0 的数据恢复;
如果从数据中心发生故障,丢失了少数 Voter 副本,能自动切换成 async 异步复制模式,此时主中心业务访问不受影响;
少数 Voter 副本发生异常不可访问,可自动发起 leader election,并在 20s 内自动恢复服务;
DR DC Voter 可以根据实际情况驱逐 region leader,避免 leader 跨数据中心访问,主要控制 PD 的 Leader 节点所在的 IDC。
运维管理和故障场景处理相对复杂;
跨 region 读写数据场景极端场景可能出现 ACID 保障不了,需要借助应用层对账措施双重保障;
当不处于同步复制状态(sync)的集群发生了灾难,DR 不能保证满足 RPO = 0 进行数据恢复;
如果主数据中心发生故障,丢失了大多数 Voter 副本,但是从数据中心有完整的数据,可在从数据中心恢复数据,此时需要人工介入,通过专业工具进行内部一致性校验,判断是否存在不一致的情况,并对数据进行一致性恢复(故障时间段数据更新越多,校验时间越久,业务高峰期异常和业务低峰期异常的耗时不同),从数据中心对 2 个副本进行角色重新定义,并继续提供读写服务;
Primary IDC 故障后,DR IDC 的 PD 集群需要重建。
同城三中心;
网络延迟低且稳定的环境。
所有数据的副本分布在三个数据中心,同时具备高可用和容灾能力,且故障发生时能自动切换;
任何一个数据中心失效后,不会发生任何数据丢失(RPO=0);
任何一个数据中心失效后,其它两个数据中心会自动发起 leader election,并在 20s 以内自动恢复对外服务。
对于写入的场景,由于多节点间基于 Raft 协议同步数据,所有写入的数据需要同步复制到集群内至少 2 个数据中心,TiDB 写入过程使用两阶段提交,故写入延迟至少 2 倍数据中心间的延迟;
对于读请求来说,如果数据 leader 与发起读取的 TiDB 节点不在同一个数据中心,如果此时网络不稳定,读请求的效率也会受网络延迟影响;
TiDB 中的每个事务都需要向 PD leader 获取 TSO,当 TiDB 与 PD leader 不在同一个数据中心时,由于每个写入的事务请求会获取两次 TSO,所以 TiDB 实例上运行的事务性能会受网络延迟的影响。
同城双中心+异地中心;
网络延迟低且稳定的环境。
异地跨城级高可用能力,可以应对异地城市级自然灾害;
任何一个数据中心失效后,不会产生任何数据丢失 (RPO = 0)(异地跨城 IDC 的网络延迟较大,异地 IDC 的数据会有所丢失);
任何一个数据中心失效后,其他两个数据中心会自动发起 leader election,并在 20s 自动恢复服务。
对于写入的场景,所有写入的数据需要同步复制到至少 2 个数据中心,由于 TiDB 写入过程使用两阶段提交,故写入延迟至少需要 2 倍数据中心间的延迟;
对于读请求来说,如果数据 leader 与发起读取的 TiDB 节点不在同一个数据中心,也会受网络延迟影响;
TiDB 中的每个事务都需要向 PD leader 获取 TSO,当 TiDB 与 PD leader 不在同一个数据中心时,它上面运行的事务也会因此受网络延迟影响,每个有写入的事务会获取两次 TSO。

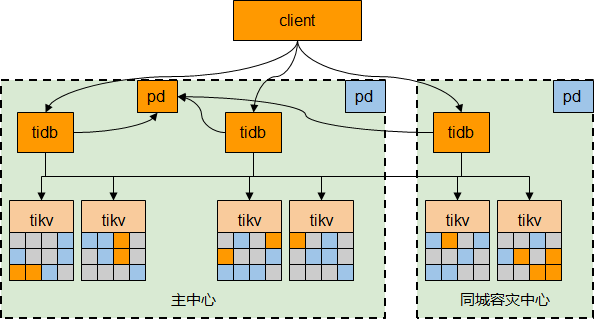
TiDB DR-Auto-Sync 同城双中心高可用实践丨银行核心背后的落地工程体系







