




paper1

第一篇文章发表在 VLDB'16。它考虑的场景是:给定数据图和一批查询图,算法要处理所有的查询。这篇工作的优化思路是:假设两个或者多个查询图有公共子图。在这种情况下,算法可以先计算出这个公共子图匹配结果。它的匹配一定是这批查询的部分匹配。我们再将这个结果拓展成其他的查询的结果。这样,我们减少了公共子结构的重复计算,从而达到优化的目的。为了达成这样的优化方式,我们需要解决的一个重要问题是:如何挖掘查询图之间的公共子图。
一种比较自然的想法是:先利用一些比较简单的特征对查询图进行分类。再在每个类别里计算公共子图。这篇工作定义了 TLS(Tri-Vertex Label Sequence) 特征,简单来说就是查询图所有 2 跳标签的集合。例如下图:。为了防止重复, 去除了对称的三元组(例如 和 对称)。
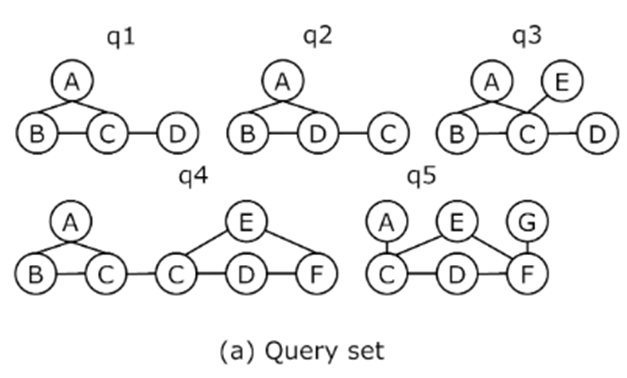
所有在中的频率之和记为。给定两个图和,我们用表示。例如:上图中的和。. 我们用表示与中的对应的的最大实例子图中的实例数。最后我们可以定义group factor: . group factor 可以理解为是对 归一化的值。它越大,两个图的最大公共子图往往也越大。计算两两查询图之间的 group factor,可以得到一个矩阵。如下图(b).

我们可以设置一个阈值,作为判断两个图是否相似的基线:如果 表示 相似。通过设置阈值,我们把 group factor 矩阵转化为了一个 01 矩阵,如上图(c). 根据这个 01 矩阵,算法会构建一个查询图的包含关系图,叫做PCM,如下图(d)。PCM的构建方法是:算法把01矩阵看作一个图的邻接矩阵,在这个图中找到所有的团。团内随机两两配对,计算它们的最大公共子图,然后连接包含关系。这组产生最大公共子图又作为下一层次的组。重复以上步骤。直到组里面的图只剩一个图。
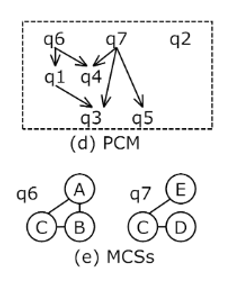
PCM 是一个 DAG,我们可以根据 PCM 的拓扑序进行子图匹配。例如,计算完 q6 和 q7 ,他们的结果就可以用来加速 q4 查询处理。文章提到了如何调整执行顺序来减少中间结果的缓存大小,简单来说,策略就是尽可能的值缓存之后会用的查询结果。
最后,文章还设计了一个数据结构CLL,用来压缩缓存结果。
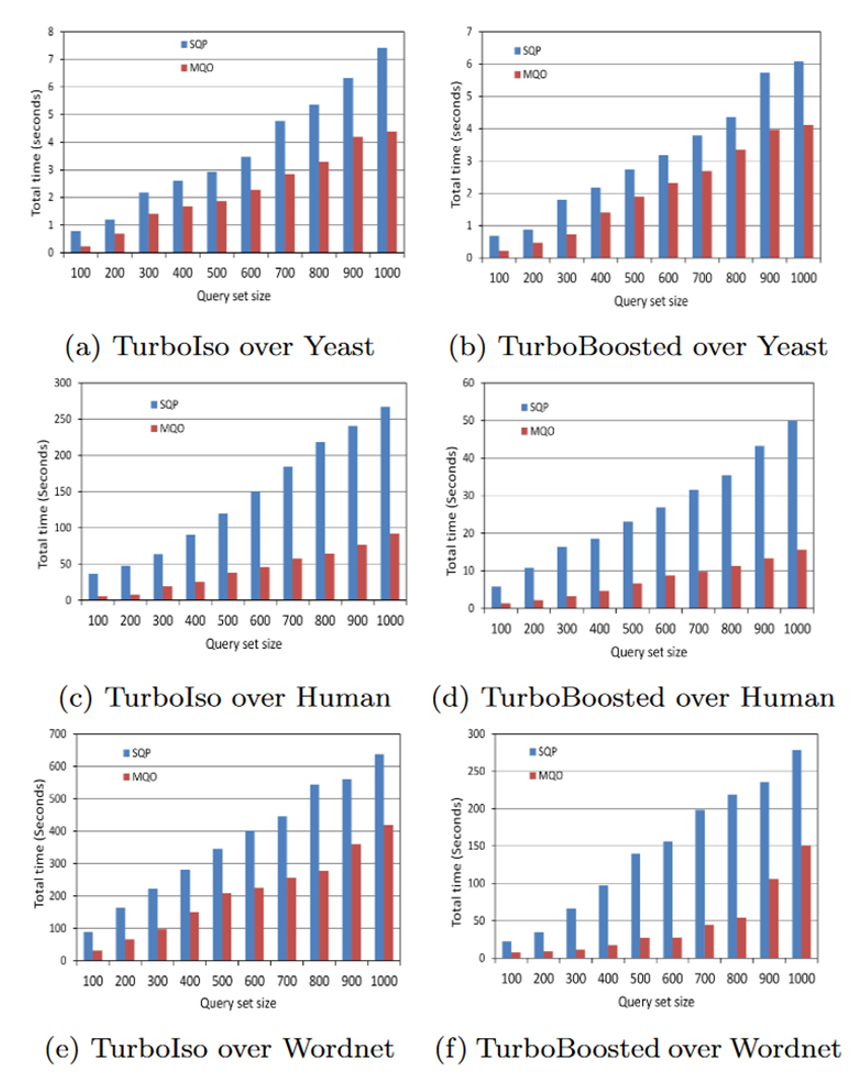
以上是实验结果,可以看到相对于当时的最优单查询子图匹配算法,mqo 还是有所提升。
paper2

第二篇文章发表在 vldb‘20。以下是它的算法框架,它的主要思路是:处理查询流时,将处理完的查询进行缓存,并通过 MPNN 为该查询图生成 embedding,作为索引。由于查询图之间的相似性与它们的embedding之间的相似性相关,算法在处理新的查询时,会通过它的embedding找到和它相似的k个缓存查询(通过 KNN),然后再在它们中找到最相似的缓存查询来加速新查询。
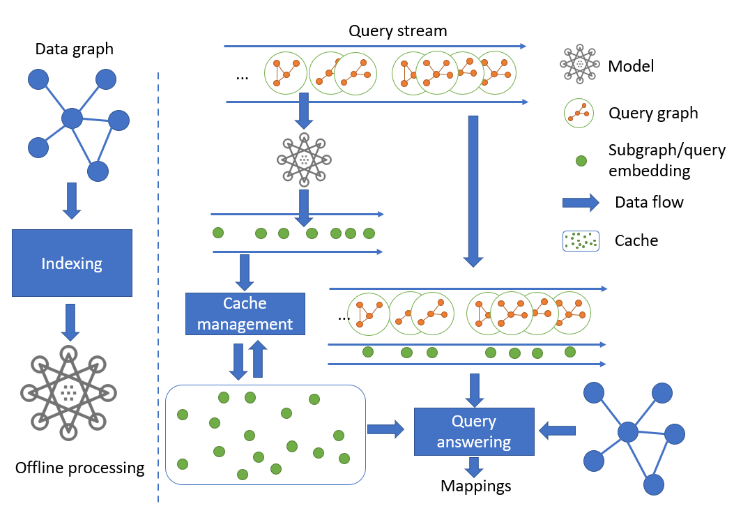
通过相似的缓存查询w来加速新查询q的方法不同于上一篇工作:这篇工作不要求 w 是 q 的子图。当 w 和 q 有交集,但是 w 不是 q 的子图时,算法依然可以进行加速。具体方法是在 [1] 中提出的。
除此之外,这篇工作还设计了一套缓存机制来提高缓存利用率。
实验展示了 embedding 的相似性和图之间的相似性的相关性。图之间的相似性通过编辑距离和最大公共子图衡量。
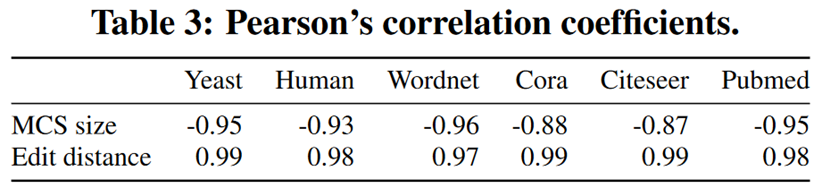
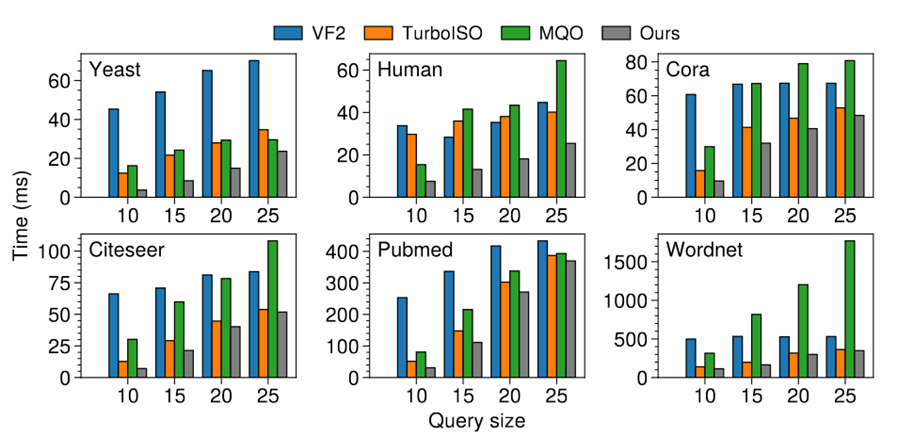
在效率方面,这篇工作和上篇工作以及 TurboISO 进行了比较。展示了该方法良好的性能以及和可拓展性。
paper3

第三篇工作发表在 vldb'23。这篇工作设计了一种高效的过滤器,用于在子图匹配搜索过程中进行剪枝。并且这种过滤器可以利用过去查询的匹配结果构建,来剪枝未来查询的搜索空间。下面是一个过滤器的例子:d是数据图,q是查询图,(b) 和 (c) 是两个过滤器,(b) 表示在数据图中有哪些节点会出现在一个三角形子图中。而 (c) 表示在数据图中有哪些节点会出现在一个四边形子图中。当处理查询 q 时,节点 a 既出现一个三角形中,又出现在一个四边形中,所以可以用 (b) 和 (c) 两个过滤器进行过滤。只有 2 和 5 满足这样的条件。
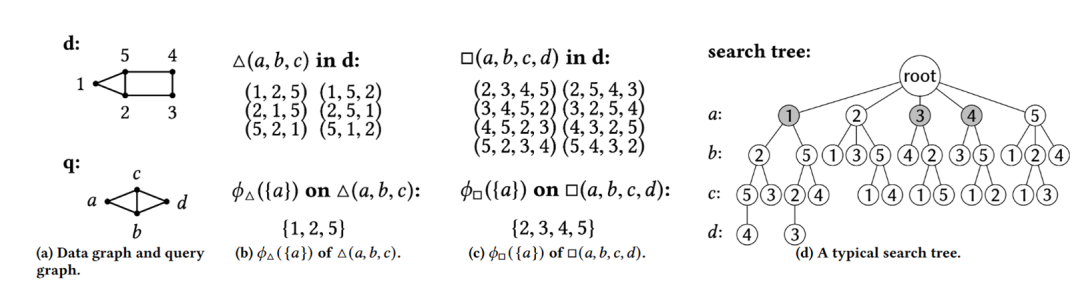
过滤器的结果形如 ,其中 表示模式, 表示键的形式。过滤器通过把 q 在 d 上的匹配结果按照 进行投影,构成一些匹配子序列,再将这些匹配子序列构建成一个 bloomfilter。因此,它是用来检验一个匹配子序列是否存在。
这篇工作基于这样的过滤器设计了一个框架 SUFF,以下是该框架的流程图:
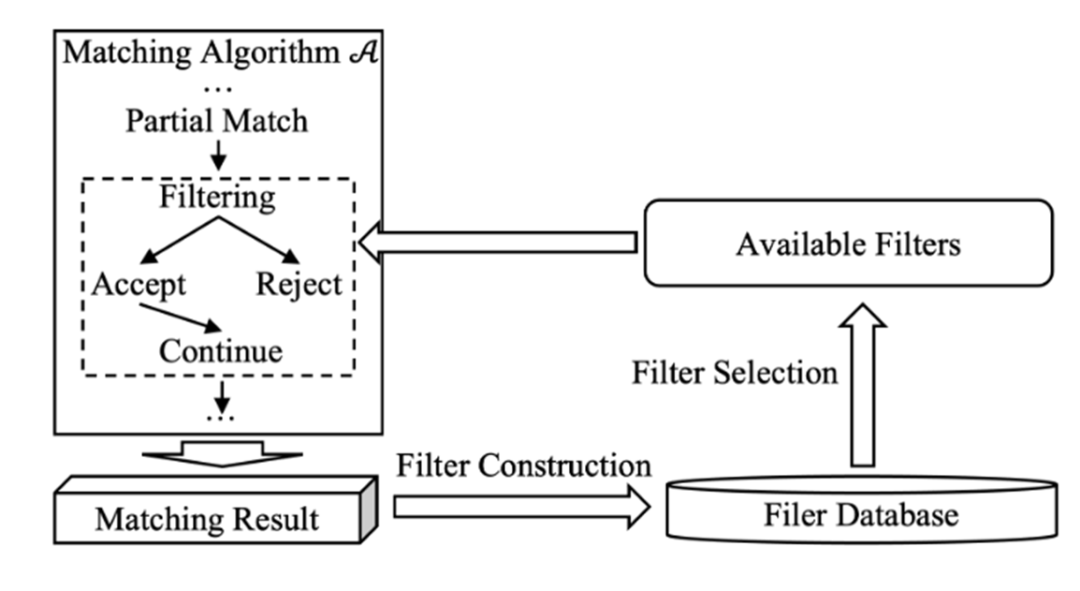
其中有三个关键问题:
Filtering. 如何使用过滤器进行查询优化? Filter Selection. 当有新的查询请求时,如何从过滤器数据库里选出合适的过滤器进行查询优化? Filter Construction. 查询完成后,如何从该查询中构建一些过滤器?
当 是 的子图的时候,可以使用 来进行剪枝。下图是在一个常规的子图匹配搜索算法中加入过滤器剪枝的方法:预处理阶段会进行过滤器的筛选,为每层选取最有效的过滤器。在搜索过程中,当当前的部分匹配被过滤器拒绝时,直接返回。

SUFF会为搜索的每一层都选取 k 个过滤器,选取过滤器原则是——尽可能覆盖未被验证的边。这是一个组合优化问题,被证明了是 NP-hard的。文章中给出了证明,并且提供了一个贪心算法。
当查询处理完成之后,SUFF基于这个查询的构建过滤器。由于子图匹配的结果往往很多,如果将匹配结果都构建成过滤器,一方面时间开销比较大,另一方面会影响 bloomfilter 的假阳性,从而影响剪枝效果。为了平衡过滤效果和存储空间,SUFF 会根据一个 a 值构建以下两类过滤器:
前缀型: 单点型:
总共 个过滤器,其中 a 是由用户设定的。
文章还提出了一些策略来删除一些过滤器而不太影响过滤器数据库的过滤能力。
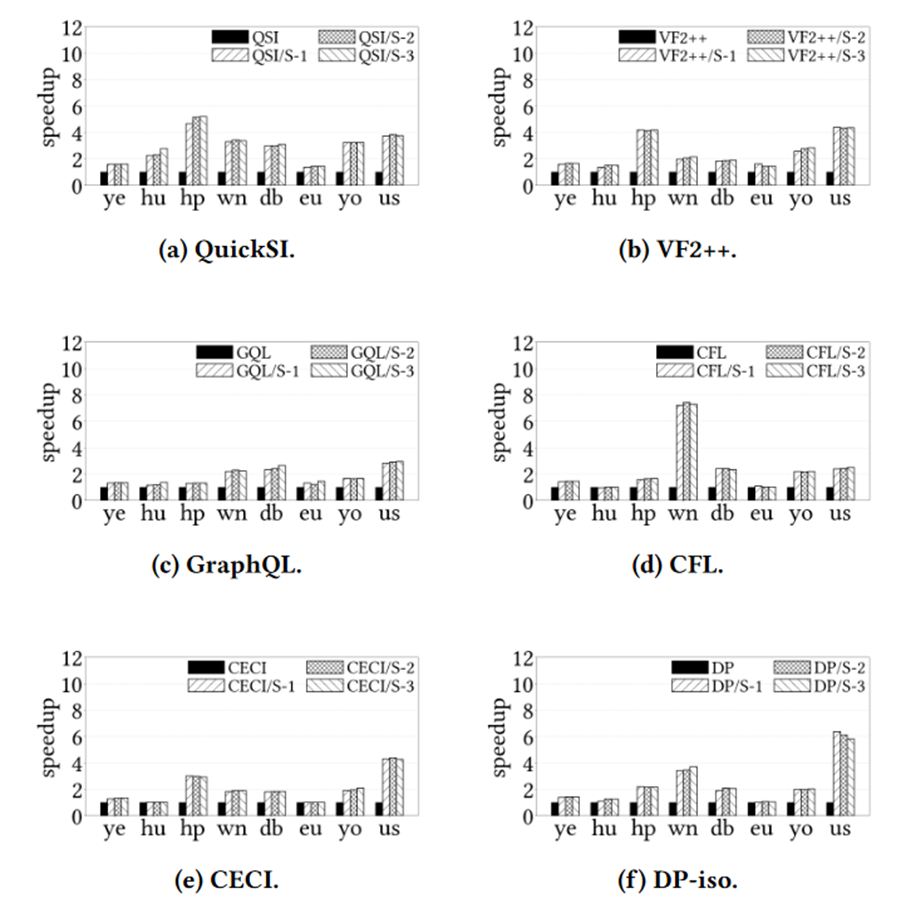
实验方面,SUFF 能够非常有效地提高子图匹配算法的效率。
总结
通过查询之间的信息优化子图匹配有类似的模式:算法会检测查询的公共模式,并缓存这些公共模式的查询结果。当算法处理相似的查询结果时,就会复用缓存结果来加速查询。但是,这三篇工作的各个部分采取的方法基本上都不一样。我认为这是因为这三篇工作利用了不同的查询信息来进行查询优化。而我认为处理查询时还有更多值得挖掘的信息可以优化后续查询(例如:匹配顺序)。
另一方面,通过查询之间的信息优化子图匹配涉及多个查询,在查询引擎中,处理多个查询往往会启动多个线程。所以,我认为在多线程环境下考虑通过查询之间的信息优化子图匹配是有意义的。
参考文献
[1] Liang, Yongjiang, and Peixiang Zhao. "Workload-aware subgraph query caching and processing in large graphs." 2019 IEEE 35th International Conference on Data Engineering (ICDE). IEEE, 2019.
[2] Jian, Xun, Zhiyuan Li, and Lei Chen. "Suff: accelerating subgraph matching with historical data." Proceedings of the VLDB Endowment 16.7 (2023): 1699-1711.
[3] Duong, Chi Thang, et al. "Fast and Accurate Efficient Streaming Subgraph Isomorphism." 47th International Conference on Very Large Data Bases (VLDB). 2020.
[4] Ren, Xuguang, and Junhu Wang. "Multi-query optimization for subgraph isomorphism search." Proceedings of the VLDB Endowment 10.3 (2016): 121-132.


欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
gStore官网:https://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore

