




可以有效减少单条记录的处理时间(通常可以由毫秒级降到0.1毫秒级),在无法通过增加并发数提升吞吐的应用中(例如有些业务需要单线程消费MQ),可以通过Batch操作有效的提升吞吐; 合并事务日志的提交等,降低数据库的负载。
多语句与Batch
insert into t1 (c1,c2) values (1,1);insert into t1 (c1,c2) values (2,2);
insert into t1 (c1,c2) values (1,1),(2,2);
多语句的各个子句之间,是要串行执行的(标准就是这样定义的,各个子句之间是允许存在依赖关系的),一条执行完才能执行下一条。因此,多语句只能节省客户端到数据库之间的网络RTT(1次RTT即可),无法节省数据库内部之间的一些开销(比如数据库主备之间,写入操作每个子句都需要至少一次RTT)。 Batch,各个记录之间,数据库是可以并行去写入的(对于PolarDB-X来说,各记录是并行写入的;对于MySQL来说,各个记录还是串行的写入的);主备之间(PolarDB-X的leader和follower之间),整个Batch只有一次RTT。
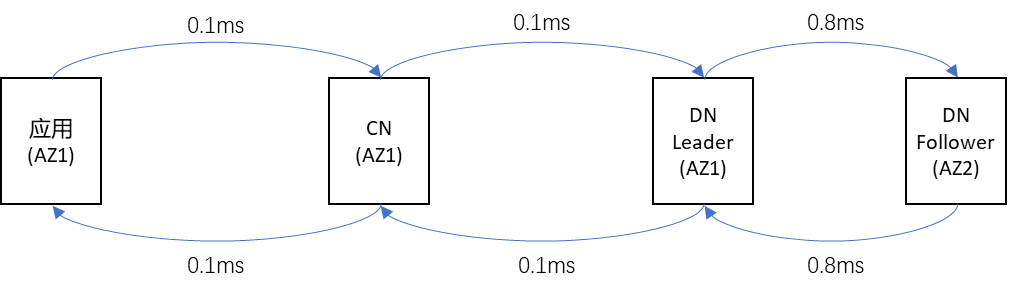
如果是多语句,只考虑网络上的延迟,理论上的耗时至少是(0.1ms+(0.1ms+0.8ms+0.8ms+0.1ms)*1000+0.1ms)= 1800.2ms; 如果是Batch,只考虑网络上的延迟,理论上的好是至少是(0.1ms+(0.1ms+0.8ms+0.8ms+0.1ms)+0.1ms)=2ms(当然,实际上肯定会比2ms大,但会远远小于1800ms)。
Batch Insert
INSERT INTO t1 (c1,c2) VALUES (1,1),(2,2);
使用PreparedStatement的addBatch()、executeBatch()接口(注意,不是addBatch(String sql),这是多语句):
Connection conn = xxx;PreparedStatement pstmt = conn.prepareStatement("INSERT INTO t1 (c1,c2) VALUES (?,?)");pstmt.setInt(1, 1);pstmt.setInt(2, 1);pstmt.addBatch();pstmt.setInt(1, 2);pstmt.setInt(2, 2);pstmt.addBatch();pstmt.executeBatch()
应用(包括mybatis)直接将语句拼成Batch的形式,这样mysql-connector-java接收到的语句就是Batch的形式,就不依赖rewriteBatchedStatements的值了。以mybatis为例: <!-- 批处理插入 --><insert id="batchInsert">INSERT INTO t1 (c1, c2) VALUES<foreach collection="list" item="item" separator=",">(#{item.c1}, #{item.c2})</foreach></insert>
最常见的错误形式是,使用PreparedStatement的addBatch()、executeBatch()接口,例如:
Connection conn = xxx;PreparedStatement pstmt = conn.prepareStatement("UPDATE t1 SET c1 = ? WHERE id = ?");pstmt.setInt(1, 1);pstmt.setInt(2, 1);pstmt.addBatch();pstmt.setInt(1, 2);pstmt.setInt(2, 2);pstmt.addBatch();pstmt.executeBatch()
使用CASE WHEN,例如:
UPDATE t1SETc1 = CASE idWHEN 1 THEN 1WHEN 2 THEN 2END,c2 = CASE idWHEN 1 THEN 1WHEN 2 THEN 2ENDWHERE id IN (1,2)如果用mybatis,例如: <!-- 批处理更新 --><update id="batchUpdate">UPDATE t1SETc1 = CASE id<foreach collection="list" item="item" separator=" ">WHEN #{item.id} THEN #{item.c1}</foreach>END,c2 = CASE id<foreach collection="list" item="item" separator=" ">WHEN #{item.id} THEN #{item.c2}</foreach>ENDWHERE id IN<foreach collection="list" item="item" separator="," open="(" close=")">#{item.id}</foreach></update>
语句冗长不好看; WHERE中使用主键的in操作,容易导致全表扫描等;
使用INSERT ... ON DUPLICATE UPDATE(简称upsert),例如:
INSERT INTO t1 (id,c1) VALUES (1,1), (2,2) ON DUPLICATE KEY UPDATE c1 = VALUES(c1)如果用mybatis,例如: <!-- 使用upsert批量更新 --><update id="batchUpdate">INSERT INTO t1 (c1, c2) VALUES<foreach collection="list" item="item" separator=",">(#{item.c1}, #{item.c2})</foreach>ON DUPLICATE KEY UPDATE c1 = VALUES(c1)</update>
该形式与Batch Insert类似,注意:
不更新的列无需写在values和update中(即使它不允许为null);
如果是分区表,记得把分区键也写在values中(但不必写到update中);
该方法有一定的限制,它要求更新的数据必须是存在的(如果不存在它就会给你插进去一条,可能与业务语义不符);
该形式也可以使用Batch Insert中的rewriteBatchedStatements=true这种形式去实现,但不推荐。
该形式SQL比较精炼,是最高效的形式。
Batch Delete
Batch Delete相对比较简单,只有一种方式:
DELETE a FROM t1 a FORCE INDEX (PRIMARY) WHERE id IN (1,2)
如果是分区表,建议带上分区键:
DELETE a FROM t1 a FORCE INDEX (PRIMARY) WHERE (id,c2) IN ((1,1),(2,2))
注意几点:
控制一下in的数目,多了容易走全表扫描导致锁表,建议不超过500;
加上FORCE INDEX (PRIMARY);
为了第二点,还需要给t1增加一个别名,这个来源于MySQL一个很奇怪的限制:
“single-table delete”不支持force index,“mult-table delete”支持force index;
只要给表加个别名,这个delete就属于“mult-table delete”了。
如何判断是否走了Batch
无论使用了何种形式,建议通过以下方式判断一下是否真的走了Batch:
查看SQL审计;
如果没开SQL审计,可以在有业务流量的时候,查看PROCESSLIST(PolarDB-X中可以执行:SHOW FULL PROCESSLIST WHERE INFO IS NOT NULL),观察执行的SQL是否是Batch的;
有经验的话,看响应时间即可,一个1000条的Batch执行好几秒,那大概率是没走Batch的。
