





0. ENV
CentOS 7.6;
CM 7.4.4;
CDP 7.1.6。
1. 现象
测试环境CDP7.1.4升级到CDP7.1.6后,hive运行数小时后,HMS服务异常。在11月26日 18:16:26 HMS服务异常宕机,当前hive不可用。
HMS服务异常,其它服务正常:
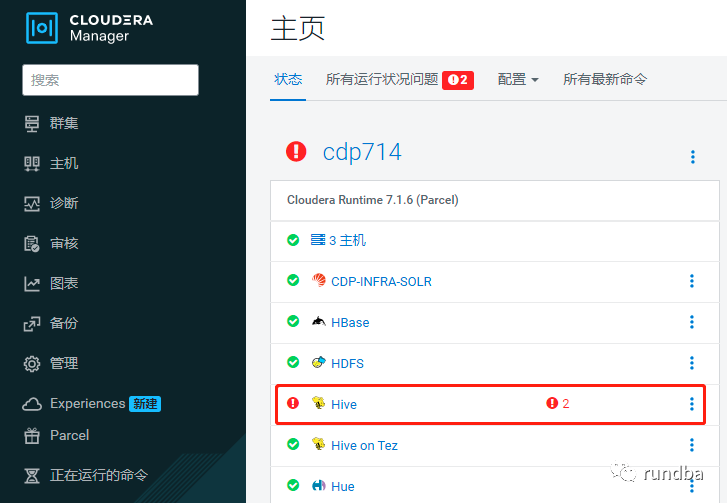
HMS服务异常宕机:
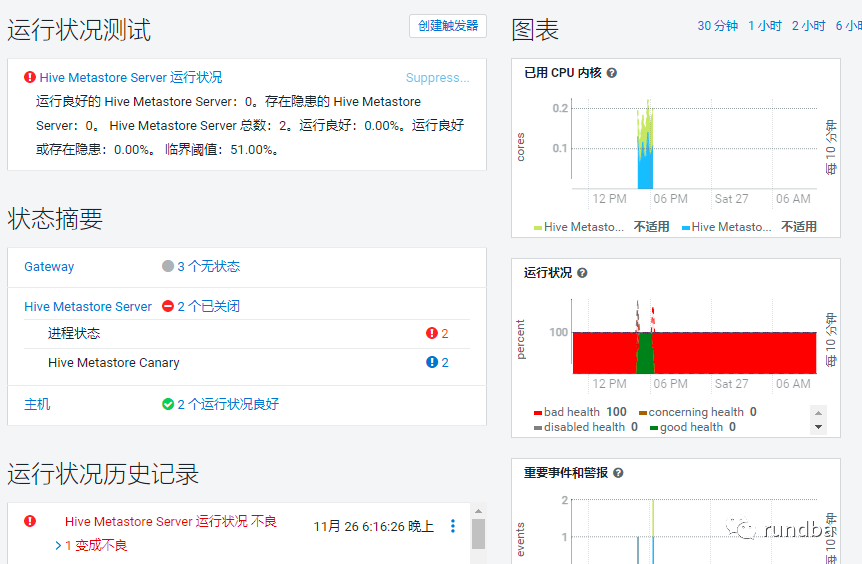
2. 处理过程
2.1 metastore进程查看
登录每台HMS主机,查看metastore进程是否存在:
[root@namenode01 hive]# ps -ef|grep metastoreroot 121490 106525 0 15:13 pts/0 00:00:00 grep --color=auto
metastore各HMS节点metastore进程均不存在。
2.2 网络验证
从HS2主机到HMS主机ping验证
HS2有两台主机:namenode01、namenode02,到对方HMS主机进行ping测试,确保网络畅通。
[in namenode01]:[root@namenode01 ~]# ping namenode02PING namenode02.rundba.com (192.168.80.123) 56(84) bytes of data.64 bytes from namenode02.rundba.com (192.168.80.123): icmp_seq=1 ttl=64 time=0.138 ms
2.3 收集堆栈跟踪-metastore进程存在时
如果HMS进程存在,收集HMS jstack文件进一步判断。
CM -> Hive -> 实例 -> 点击“Hive Metastore Server”连接 -> 操作 -> 收集堆栈跟踪(jstack).
近一步查看jstack文件,当前metastore进程不存在。
2.4 HMS服务端口是否正常--metastore进程存在时
从HS2验证HMS服务端口是否正常
HS2有两台主机:namenode01、namenode02。
[in namenode01]:[root@namenode01 ~]# telnet namenode02.rundba.com 9083Trying 192.168.80.123...telnet: connect to address 192.168.80.123: Connection refused
2.5 分析metastore日志
进入到hive日志目录
[root@namenode01 hive]# cd /var/log/hive/
查看所有HMS节点在故障时间所有hive metastore日志(非HIVESERVER2日志)
[root@namenode01 hive]# ls -l *HIVEMETASTORE*-rw-r--r--. 1 hive hive 8163265 Nov 27 17:19 hadoop-cmf-hive-HIVEMETASTORE-namenode01.rundba.com.log.out-rw-r--r--. 1 hive hive 8029833 Nov 22 12:50 hadoop-cmf-hive-HIVEMETASTORE-namenode01.log.out
查看日志,截止报错时间,无更多可用参考

2.6 分析HMS process日志文件
1) 查看HMS process日志文件
[root@namenode02 ~]# cd /var/run/cloudera-scm-agent/process/
2) 查看HMS process目录
[root@namenode02 process]# ls -ldt *HIVEMETASTORE*drwxr-x--x. 4 hive hive 500 Nov 27 15:45 653-hive-HIVEMETASTOREdrwxr-x--x. 3 hive hive 200 Nov 27 15:45 657-HIVE-HIVEMETASTORE-jstackdrwxr-x--x. 4 hive hive 500 Nov 26 16:43 651-hive-HIVEMETASTOREdrwxr-x--x. 4 hive hive 500 Nov 23 11:12 639-hive-HIVEMETASTOREdrwxr-x--x. 4 hive hive 500 Nov 22 15:21 610-hive-HIVEMETASTOREdrwxr-x--x. 4 hive hive 480 Nov 22 13:44 548-hive-HIVEMETASTOREdrwxr-x--x. 4 hive hive 400 Nov 22 13:27 508-hive-HIVEMETASTOREdrwxr-x--x. 4 hive hive 460 Nov 22 13:02 421-hive-HIVEMETASTOREdrwxr-x--x. 4 hive hive 420 Nov 22 10:28 321-hive-HIVEMETASTOREdrwxr-x--x. 4 hive hive 400 Oct 25 16:30 259-hive-HIVEMETASTOREdrwxr-x--x. 4 hive hive 400 Oct 25 16:08 235-hive-HIVEMETASTOREdrwxr-x--x. 4 hive hive 400 Oct 25 15:46 185-hive-HIVEMETASTOREdrwxr-x--x. 4 hive hive 420 Oct 25 14:27 164-hive-HIVEMETASTOREdrwxr-x--x. 4 hive hive 400 Oct 22 18:04 100-hive-HIVEMETASTOREdrwxr-x--x. 4 hive hive 400 Oct 22 17:19 90-hive-HIVEMETASTOREdrwxr-x--x. 4 hive hive 400 Oct 22 17:17 60-hive-HIVEMETASTORE
3) 通过接近报错时间查看日志
从HMS process日志来看, 由于java的OOM(out of memory)执行了HMS kill进程,导致了HMS宕机。
[root@yw-namenode02 process]# view 653-hive-HIVEMETASTORE/logs/stdout.log...2021-11-26 16:43:28: Starting Hive Metastore Serverjava.lang.OutOfMemoryError: Java heap spaceDumping heap to /tmp/hive_hive-HIVEMETASTORE-0146b4aa7626ce9e27ceae0c630ddefa_pid35634.hprof ...Heap dump file created [91207946 bytes in 0.683 secs]## java.lang.OutOfMemoryError: Java heap space# -XX:OnOutOfMemoryError="/opt/cloudera/cm-agent/service/common/killparent.sh"# Executing /bin/sh -c "/opt/cloudera/cm-agent/service/common/killparent.sh"...
说明:
/opt/cloudera/cm-agent/service/common/killparent.sh为HMS相关的进程,可通过已启动的HMS环境,使用ps -ef | grep metastore查看。

3. 问题解决
调大HMS的 Java Heap Size值,来避免OOM发生。
CM -> Hive -> Configuration -> Java Heap Size of Hive Metastore Server in Bytes(搜索java) ,调大为如8G,保存,重启hive服务。
注:Java Heap Size of Hive Metastore Server in Bytes默认为50M。

重启后,HMS恢复正常,运行并观察一段时间,再无报错。
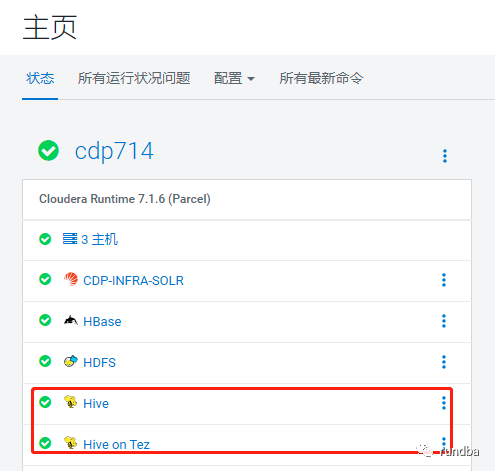
4. 小结
文中通过HMS服务异常,通过服务、网络、metastore日志、HMS process log逐层分析,定位到问题所在,最终解决问题,作为类似问题处理参考。
不足之处,还望抛砖。
作者:王坤,微信公众号:rundba,欢迎转载,转载请注明出处。
如需公众号转发,请联系wx: landnow。


