




作者介绍

Nebula Flink Connector 简介
1
NebulaGraph Flink Connector
NebulaGraph Flink Connector 是一款帮助 Flink 用户快速访问 NebulaGraph 的连接器,支持从 NebulaGraph 中读取数据,或者将其他外部数据源读取的数据写入 NebulaGraph.
适用于以下场景:
读取 NebulaGraph 数据进行分析计算; 分析计算完的数据写入 NebulaGraph; 迁移数据。
2
Apache Flink
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。
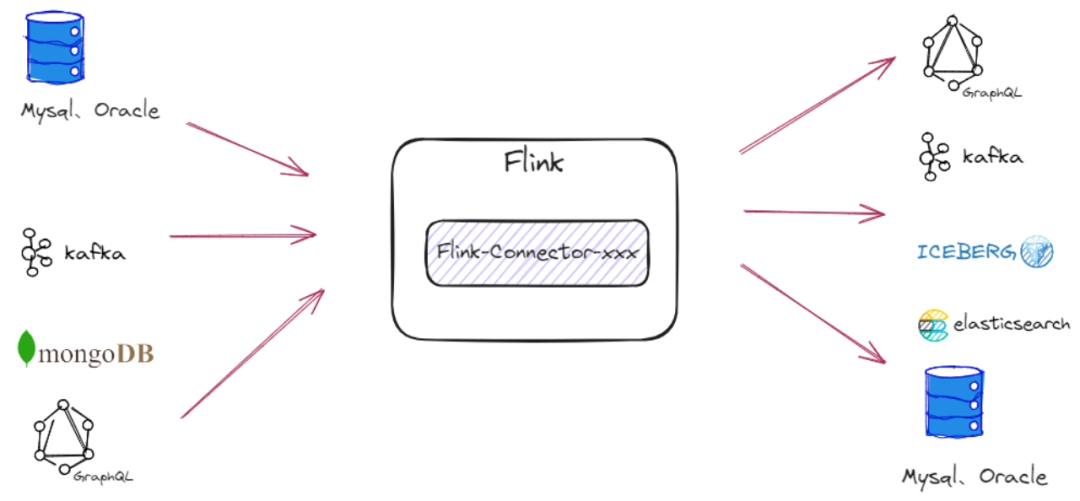
从上图中我们能发现 Flink 能从不同的第三方存储引擎中读取数据,并进行处理,再写入另外的存储引擎中。
那 Flink 又是如何读取外部系统的数据呢,其实是通过 Flink Connector,它的作用就相当于一个连接器,连接 Flink 计算引擎跟外界存储系统。
流计算中经常需要与外部存储系统交互,比如需要关联 MySQL 中的某个表,都需要通过连接器来读取外部系统的数据。Nebula Flink Connector 采用类似 Flink 提供的 Flink Connector 形式,支持 Flink 读写 NebulaGraph.
Nebula Flink Connector 中的 Source
Nebula Flink Connector 的 Source 即 NebulaGraph.通过轮训的方式来不断读取 NebulaGraph 中的数据,直至数据读取完毕。
Flink 提供了丰富的 Connector 组件允许用户自定义数据源来连接外部数据存储系统。Nebula Flink Connector 是基于 Flink 老版本的 API SourceFunction 实现的,我们知道一个完整的 Flink程序包含至少包含 Source、Sink .
那 Source 就是由下面的方式添加的:
StreamExecutionEnvironment.addSource(sourceFunction)
ExecutionEnvironment.createInput(inputFormat)
本文从 SourceFunction 开始介绍。
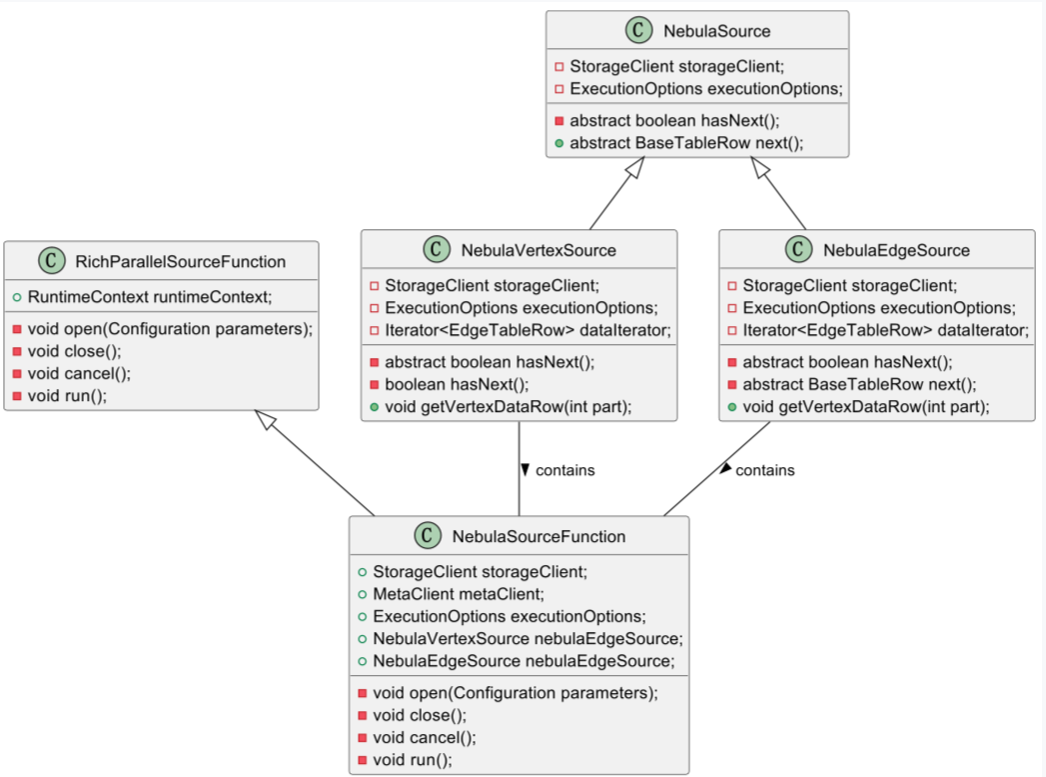
首先,让我们更详细地介绍 Source 组件中类的关系图,其中核心类或者接口包含下面 5 个:
1
NebulaSource 接口
NebulaSource 是一个定义了获取 NebulaGraph 数据的接口。这个接口在 Source 组件中扮演着核心的角色,因为它定义了如何从 NebulaGraph 获取数据的基本方法。
该接口有两个实现类:NebulaVertexSource 和 NebulaEdgeSource .这两个类分别负责从 NebulaGraph 中获取顶点(Vertex)数据和边(Edge)数据。
2
NebulaVertexSource 和 NebulaEdgeSource:
这两个类实现了 NebulaSource 接口,并提供了获取点或边数据的具体实现。
例如,NebulaVertexSource 会包含特定于顶点的逻辑,而 NebulaEdgeSource 则包含特定于边的逻辑。
3
RichParallelSourceFunction 抽象类:
4
NebulaSourceFunction 类
它继承了 RichParallelSourceFunction 类,并重写了关键的方法,包括 open 、 run 和 cancel .
open 方法用于初始化资源,例如连接 NebulaGraph 的客户端。
run 方法是核心,在 run 方法中创建了 NebulaSource 对象,这个对象主要用来读取 NebulaGraph 中的数据。
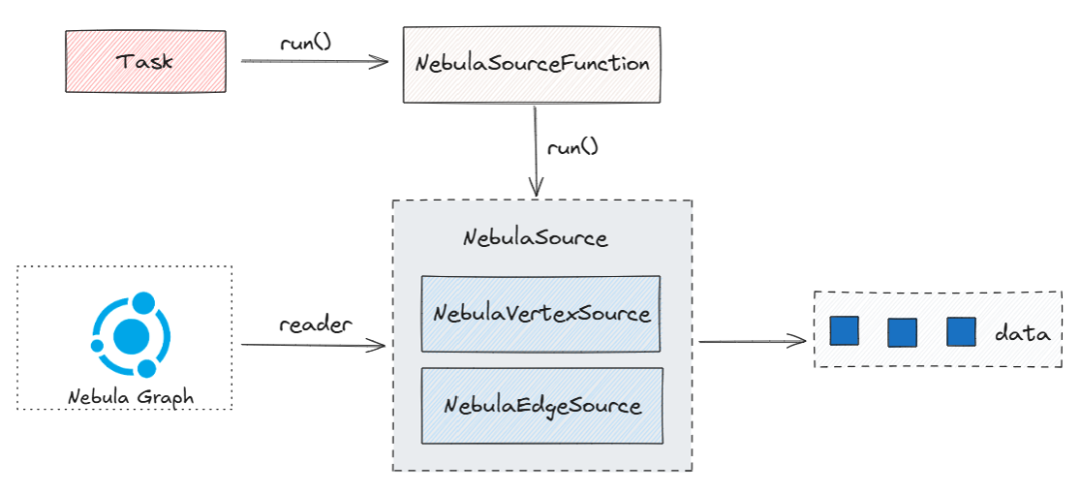
在 Nebula Flink Connector 的 Source 组件中,最核心的逻辑是 NebulaSourceFunction 的 run 方法,在此方法中不断读取 NebulaGraph 中的数据。那会有不少看官疑惑这个 run 方法在什么时候运行呢,下面就来一一道来。
熟悉 Flink 的都知道,Flink 中的任务是执行的基本单元。它是执行 operator 的每个并行实例的地方。那 StreamTask 是 Flink 流处理引擎中所有不同任务子类型的基础。因为任务是执行 operator 并行实例的实体,它的生命周期与 operator 的生命周期紧密集成。因此,我们将浅浅的讨论 operator 生命周期的基本方法。
以下是按每个方法被调用的顺序列出的方法。
鉴于 operator 可以有用户定义函数(UDF),在每个 operator 方法下,我们还提供它调用的 UDF 生命周期中的方法。这些方法在您的 operator 扩展了 AbstractUdfStreamOperator 时可用,它是执行 UDF 的所有 operator 的基本类。
// initialization phaseOPERATOR::setupUDF::setRuntimeContextOPERATOR::initializeStateOPERATOR::openUDF::open// processing phase (called on every element/watermark)OPERATOR::processElementUDF::runOPERATOR::processWatermark// checkpointing phase (called asynchronously on every checkpoint)OPERATOR::snapshotState// notify the operator about the end of processing recordsOPERATOR::finish// termination phaseOPERATOR::closeUDF::close
本文介绍几个对于我们理解 Nebula Flink Connector 的方法。
open() 方法,open() 方法执行任何 operator 特定的初始化,例如在 AbstractUdfStreamOperator 的情况下打开用户定义的函数。其实会执行到我们自定义的 NebulaSourceFunction 中的 open() 方法。在 open() 方法中我们主要是初始化 storageClient 和 metaClient 等。
run() 方法,然后会调用到 NebulaSourceFunction 中的 run() 方法,在这个方法中创建了 NebulaSource 这个对象,这个对象负责读取 NebulaGraph 中的数据,以轮训的方式获取数据。
Flink 是以 StreamTask 形式运行在 TaskManager 上,通过 StreamTask 的生命周期得知最终会先运行 operator 的 open() 方法和 run() 方法。
在 NebulaSourceFunction 中 open() 做了初始化赋值,只会运行一次(不考虑重视的情况下)。然后就会运行 run() 方法来读取 NebulaGraph 中的数据,在 run() 方法中创建了 NebulaSource 这个对象,这个对象负责读取 NebulaGraph 中的数据,以轮训的方式获取数据。
StreamTask 的执行流程图如下图,我们这里省略的 open() 方法。
Nebula Flink Connector 中的 Sink
Nebula Flink Connector 的 Sink 组件负责将 Flink 中 Source 组件获取的数据写入到 NebulaGraph 数据库中。以下是对该组件的详细介绍,包括其核心类和接口的作用与关系。在 Nebula Flink Connector 中,Sink 组件的作用是关键的一环,它确保了数据从 Flink 环境流向 NebulaGraph.
以下是内容的重组和详细说明。我们的 Nebula Flink Connector 是基于 Flink 的老版本 API SinkFunction 实现的。
在使用时,通过调用 Flink 算子的 addSink() 方法来添加一个 Sink 函数。
例如:operator.addSink(sinkFunction)
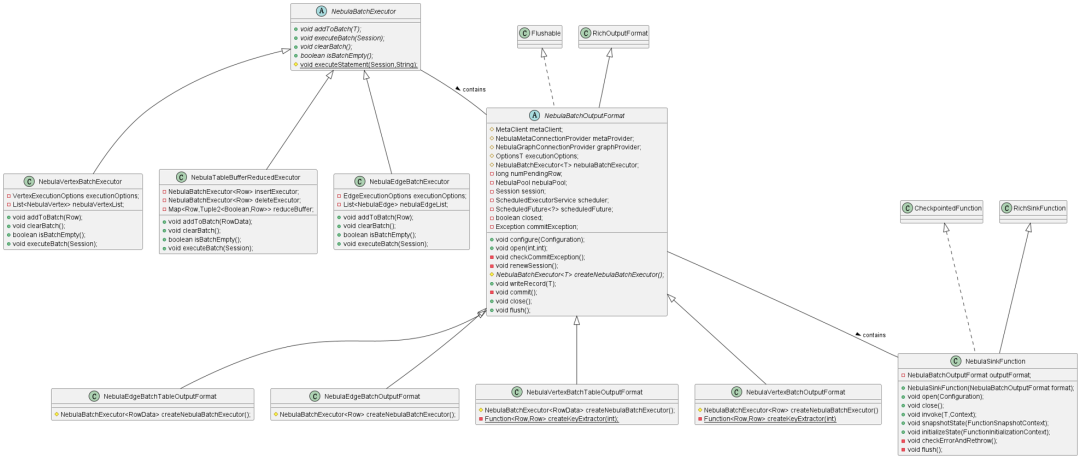
Nebula Flink Connector 中 Sink 组件的核心类关系图如上图,以下是三个核心的类和接口的详细介绍:
1
NebulaSinkFunction 类:
这是一个继承了 RichSinkFunction 抽象类的实现类。它重写了父类的方法,并在其内部包含了一个 NebulaBatchOutputFormat 属性。
在构造 NebulaSinkFunction 时,会对 NebulaBatchOutputFormat 对象进行赋值。
该类有两个重要方法:open() 和 invoke()
open() 用于初始化参数,调用 NebulaBatchOutputFormat 对象的 open() 方法。 invoke() 负责调用 outputFormat.writeRecord(value) 将数据写入 NebulaGraph.
2
NebulaBatchOutputFormat 抽象类:
NebulaBatchOutputFormat 继承自 RichOutputFormat 类,主要用于获取 RuntimeContext 对象。
它有四个实现类:
NebulaEdgeBatchOutputFormat
NebulaEdgeBatchTableOutputFormat
NebulaVertexBatchOutputFormat
NebulaVertexBatchTableOutputFormat
分别处理边和点的数据。
该类包含两个核心方法:
open() 方法:初始化了 Nebula 的 Session 对象,并创建了一个定时任务,用于执行 commit() 方法。commit() 方法通过调用 nebulaBatchExecutor.executeBatch(session) 将数据写入 NebulaGraph。
writeRecord(Trow) 方法:将数据添加到批处理中,最终通过 executeBatch 方法写入数据库。
3
NebulaBatchExecutor 抽象类
NebulaBatchExecutor 是一个抽象类,有三个实现类:
NebulaEdgeBatchExecutor
NebulaTableBufferReducedExecutor
NebulaVertexBatchExecutor
分别负责将边和点的数据写入 NebulaGraph
该类有两个核心方法:
addToBatch(Row record) 方法:将数据缓存到内存中。
executeBatch(Session session) 方法:将缓存中的数据实际写入数据库。
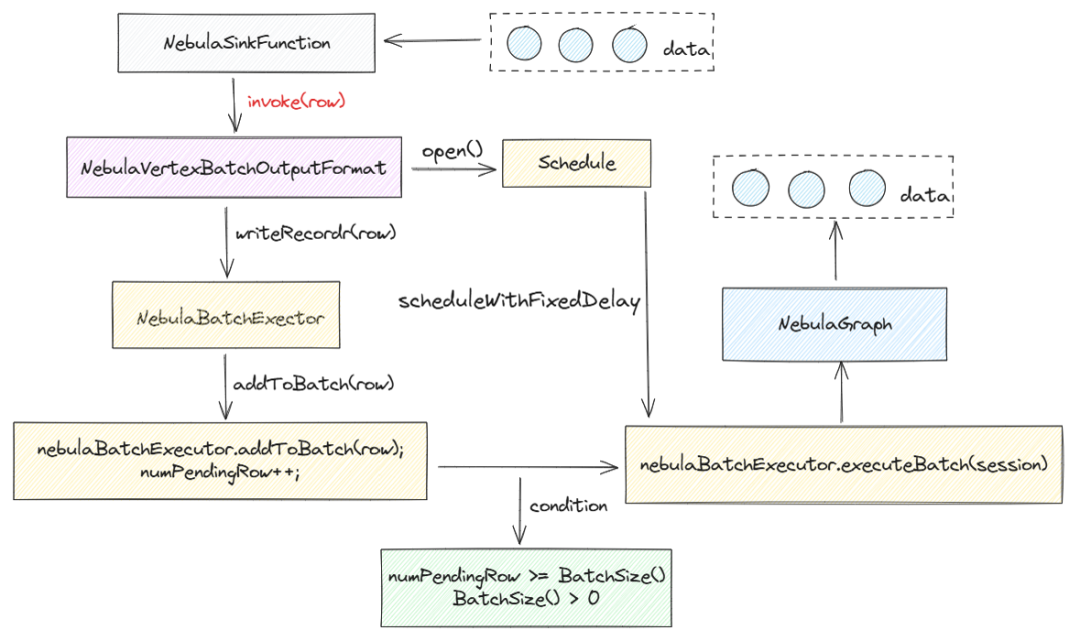
当我们观察 Flink 中的数据如何写入到 NebulaGraph 时,可以概括为以下几个关键步骤:
数据流入与处理:
StreamTask 在 TaskManager 上运行,一旦有数据流入,它将触发 operator 的 invoke() 方法。这个调用链最终会传导至 NebulaSinkFunction 的 invoke() 方法内部。
在 NebulaSinkFunction 的 invoke() 方法中,数据通过调用 outputFormat.writeRecord(value) 方法被处理,这是数据写入流程的起点。
批处理与条件触发:
随后, numPendingRow (待处理记录数)会进行累加。当累加的记录数达到配置的批量大小(即 executionOptions.getBatchSize() > 0 )而且达到批处理的最大容量时,将触发 nebulaBatchExecutor.executeBatch(session) 方法的调用。
执行批量写入:
NebulaBatchExecutor 中的 executeBatch(Session session) 方法是一个抽象方法,具体的实现由其子类提供。
在子类的实现中,会将缓存在内存中的数据封装成可执行的 SQL 批量语句,然后通过调用自身的 executeStatement() 方法执行这些语句。
实际上, executeStatement() 方法内部是通过 session.execute(statement) 调用,将缓存的数据批量写入到 NebulaGraph 数据库中。
通过这个过程,可看到 Nebula Flink Connector 的 Sink 组件如何将数据从 Flink 转到 NebulaGraph. 这一流程的每个环节都由特定的类和方法负责,确保了数据传输的高效和可靠。
为了更直观地理解这一流程,可以参考下图所示的流程图,它形象地展示了数据写入到 NebulaGraph.
Nebula Flink Connector 的实践
Nebula Flink Connector 是一款基于 Apache Flink API 开发的连接器,旨在为 Flink 提供与 NebulaGraph 数据库的集成方案。该连接器使得数据可以在 Flink 和 NebulaGraph 之间无缝流动,支持实时的数据处理和分析,具有下面 3 个特性。1.数据读取:Nebula Flink Connector 提供了 Source 连接器,允许 Flink 程序从 NebulaGraph 中读取数据。
2.数据写入:同时,它也提供了 Sink 连接器,用于将 Flink 处理后的数据写入到 NebulaGraph.
3.独立性:作为一个独立的 jar 包,Nebula Flink Connector 本身不包含 Flink 运行时环境,因此无法独立运行。
为了使用 Nebula Flink Connector 需要和 Flink 进行集成,我们需要遵循以下步骤:
1、构建 Flink 程序:
需要利用 Flink 的 API 编写一个 Flink 程序,确保程序中至少包含 Source 和 Sink 组件。
在程序中, Source 组件可以从 NebulaGraph 读取数据,而 Sink 组件则负责将数据写入NebulaGraph.
在构建 Flink 程序时,需要将 Nebula Flink Connector 的 jar 包添加到项目的依赖中。
根据需要配置连接 NebulaGraph 的参数,如数据库地址、认证信息、数据模型等。
开发完成后,使用 Flink 客户端将 Flink 程序打包并提交到资源调度系统上执行。支持的资源调度系统包括但不限于 YARN(Yet Another Resource Negotiator)和 K8S(Kubernetes)
提交过程中,可以指定资源需求、并行度等运行时参数,以确保程序的高效执行。
NebulaGraph Source 应用实践
// 构造 NebulaGraph 客户端连接需要的参数NebulaClientOptions nebulaClientOptions = new NebulaClientOptions.NebulaClientOptionsBuilder().setAddress("127.0.0.1:45500").build();// 创建 connectionProviderNebulaConnectionProvider metaConnectionProvider = newNebulaMetaConnectionProvider(nebulaClientOptions);// 构造 NebulaGraph 数据读取需要的参数List<String> cols = Arrays.asList("name", "age");VertexExecutionOptions sourceExecutionOptions = newVertexExecutionOptions.ExecutionOptionBuilder().setGraphSpace("flinkSource").setTag(tag).setFields(cols).setLimit(100).builder();// 构造 NebulaInputFormatNebulaInputFormat inputFormat = new NebulaInputFormat(metaConnectionProvider).setExecutionOptions(sourceExecutionOptions);// 方式 1 使用 createInput 方式注册 NebulaGraph 数据源DataSource<Row> dataSource1 = ExecutionEnvironment.getExecutionEnvironment().createInput(inputFormat);// 方式 2 使用 addSource 方式注册 NebulaGraph 数据源NebulaSourceFunction sourceFunction = newNebulaSourceFunction(metaConnectionProvider).setExecutionOptions(sourceExecutionOptions);DataStreamSource<Row> dataSource2 =StreamExecutionEnvironment.getExecutionEnvironment().addSource(sourceFunction);
NebulaGraph Sink 应用实践
/// 构造 NebulaGraphd 客户端连接需要的参数NebulaClientOptions nebulaClientOptions = new NebulaClientOptions.NebulaClientOptionsBuilder().setAddress("127.0.0.1:3699").build();NebulaConnectionProvider graphConnectionProvider = newNebulaGraphConnectionProvider(nebulaClientOptions);// 构造 NebulaGraph 写入操作参数List<String> cols = Arrays.asList("name", "age")ExecutionOptions sinkExecutionOptions = newVertexExecutionOptions.ExecutionOptionBuilder().setGraphSpace("flinkSink").setTag(tag).setFields(cols).setIdIndex(0).setBatch(20).builder();// 写入 NebulaGraphdataSource.addSink(nebulaSinkFunction);
遇到的问题
1
通过 FlinkSQL 将数据写入到 Nebula 的边和点的问题
我们是用 Nebula Flink Connector 写 FlinkSQL 将数据写入到 NebulaGraph 中会出现下面两个问题。
1、写入到 NebulaGraph 的边中,创建表的时候,源点索引和目标点索引必须在第一位和第二位
CREATE TABLE `friend` (sid BIGINT,-- 第一位必须是源点的iddid BIGINT,-- 第二位必须是目标点的idrid BIGINT,col1 STRING,col2 STRING) WITH ('connector' = 'nebula','meta-address' = '127.0.0.1:9559','graph-address' = '127.0.0.1:9669','username' = 'root','password' = 'nebula','graph-space' = 'flink_test','label-name' = 'friend','data-type'='edge','src-id-index'='0','dst-id-index'='1','rank-id-index'='2')
我们看到上面的SQL, src-id-index 是源点的索引位置对应的是 sid , dst-id-index 是目标点的索引位置对应的是 did ,这俩值必须是 0 和 1 .
我们去代码中发现,在获取属性列表时发现这里的下面从 2 开始,也就是把 0 和 1 作为源点和目标点。
for (int i = 2; i < columns.size(); i++) {if (config.get(RANK_ID_INDEX) != i) {positions.add(i);fields.add(columns.get(i).getName());}}
我们进行了下面的改造就支持了 src-id-index 和 dst-id-index 可以放在任意位置。
for (int i = 2; i < columns.size(); i++) {if (config.get(RANK_ID_INDEX) != i) {if(i == srcIndex || i == dstIndex){continue;}positions.add(i);fields.add(columns.get(i).getName());}}
CREATE TABLE `person` (vid BIGINT,-- 这个必须放在首位col1 STRING,col2 STRING,col3 BIGNT) WITH ("'connector' = 'nebula','meta-address' = '127.0.0.1:9559','graph-address' = '127.0.0.1:9669','username' = 'root','password' = 'nebula','data-type' = 'vertex','graph-space' = 'flink_test','label-name' = 'person');
我们从上面的 SQL 中发现,这个源点 id 是 vid 必须放在首位。我们在代码中发现,这个封装属性时下标是从 1 开始,默认把首位作为源 id。
if (config.get(DATA_TYPE).isVertex()) {for (int i = 1; i < columns.size(); i++) {positions.add(i);fields.add(columns.get(i).getName());}}
if (config.get(DATA_TYPE).isVertex()) {for (int i = 1; i < columns.size(); i++) {if(idIndex == i){continue;}positions.add(i);fields.add(columns.get(i).getName());}}
2
接入FlinkCDC的Source时,无法处理删除的数据
我们知道通过 FlinkCDC 采集到的数据流入 Flink,通过 Nebula Flink Connector 写入到 NebulaGraph 中,我们知道 FlinkCDC 集到的数据的 RowKind 有可能是 DELETE .
然而在构建 NebulaVertexBatchOutputFormat 对象时传入 executionOptions 对象,在构建 executionOptions 对象时,我们设置了 WriteMode , 这时 WriteMode 已经固定了,也就是说 NebulaVertexBatchOutputFormat 对象只能处理一种流。
final int DELETE_FLAG = 0;final int INSERT_FLAG = 1;GraphConfig graphConfig = buildGraphConfig();SinkFunction sinkFunction = SinkFunctionLoader.load(graphConfig);NebulaSinkFunction<Row> deleteFunction =sinkFunction.getSinkFunction(DELETE_FLAG);NebulaSinkFunction<Row> insertFunction =sinkFunction.getSinkFunction(INSERT_FLAG);SingleOutputStreamOperator<Row> changeOperator = dataStream.process(newOutputProcessFunction());DataStream<Row> deleteOperator =changeOperator.getSideOutput(Descriptors.DELETE_TAG);deleteOperator.addSink(deleteFunction);changeOperator.addSink(insertFunction);
@Overridepublic void processElement(Row record,ProcessFunction<Row, Row>.Context ctx, Collector<Row>out) throws Exception {if (record.getKind() == RowKind.DELETE) {log.info("NebulaGraph's sink received deleted data, the data is:{}",record);ctx.output(delegateOutputTag, record);} else {out.collect(record);}}
✦
如果你觉得 NebulaGraph能帮到你,或者你只是单纯支持开源精神,可以在 GitHub 上为 NebulaGraph 点个 Star!每一个 Star 都是对我们的支持和鼓励✨
https://github.com/vesoft-inc/nebula
✦
✦

扫码添加
可爱星云
技术交流
资料分享
NebulaGraph 用户案例集
案例推荐:
知识图谱案例:
苏宁基于 NebulaGraph 构建知识图谱的大规模告警收敛和根因定位实践
金融风控案例:
360数科:基于 NebulaGraph 打造智能化的金融反欺诈系统
NebulaGraph 助力金蝶征信产业图谱深挖企业关系链,实现银行批量获客
智能运维案例:
58 同城基于 NebulaGraph 一键部署运维架构的实践
苏宁基于 NebulaGraph 构建知识图谱的大规模告警收敛和根因定位实践
大数据/图平台:
OPPO:通过 NebulaGraph 建设全局图数据库平台
数据治理:
微众银行:利用 NebulaGraph 进行全局数据血缘治理的实践
安全:
