




一、测试环境
虚拟机环境:本次测试使用的服务器配置为操作系统为CentOS 7.6。
openGauss版本:openGauss 6.0 LTS 轻量版。

二、功能测试
安装与部署
首先,我们从openGauss官网【传送门】下载了最新版本的安装包,然后按照官方文档的指引进行了安装。整个安装过程比较顺利,仅涉及到一个问题。
the maximum number of SEMMNI is not correct, the current SEMMNI is xxx. Please check it.
su - rootvi etc/sysctl.conf增加如下语句 kernel.sem = 250 32000 100 999 然后执行sysctl -p

安装完成后,我们对openGauss进行了基本的配置,如创建用户、分配权限等。
性能测试
为了评估新版本的性能,我们采用了业界通用的TPC-C基准测试。在测试过程中,我们设置了不同的并发用户数,从100到1000不等。结果显示,随着并发用户数的增加,openGauss的处理能力呈现出线性增长的趋势,表现出了很好的扩展性。此外,我们还对比了新版本与旧版本的性能差异,发现新版本在处理速度和吞吐量方面都有了明显的提升。
兼容性测试
我们对openGauss进行了兼容性测试。测试内容包括openGauss 6.0.0 LTS 版本正式上线中提到的生态兼容性增强。
支持删除表时忽略视图和表的依赖。删除表时,如果一个视图是基于该表创建的,那么删除可以正常执行,该视图会被设为非法状态,查询视图时直接报错。
你可以使用以下步骤来创建一个表和一个引用该表的视图。
创建表
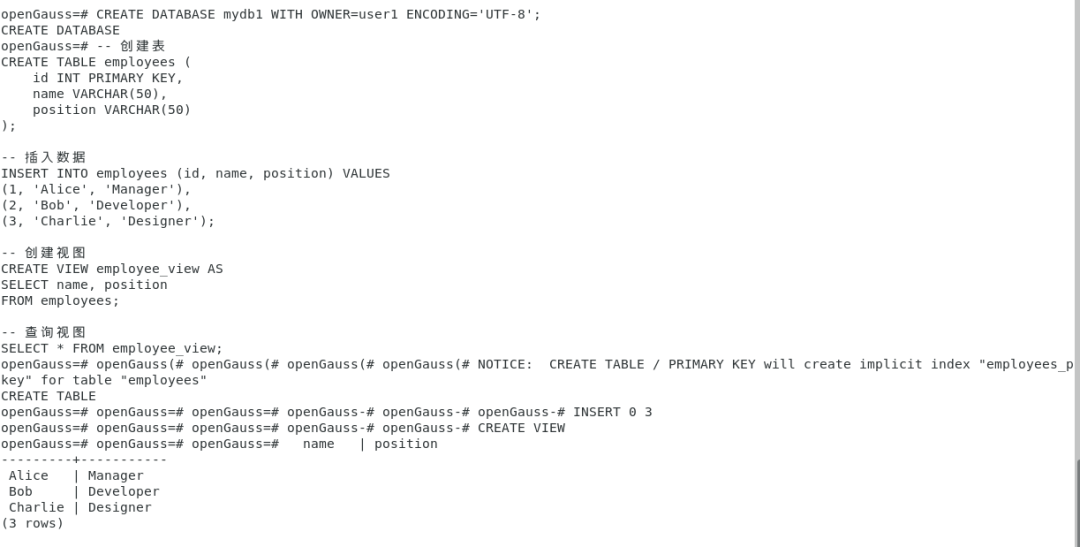
首先,我们创建一个示例表。假设我们要创建一个名为 employees
的表,包含员工的 ID、姓名和职位。
CREATE TABLE employees (id INT PRIMARY KEY,name VARCHAR(50),position VARCHAR(50));
插入数据
接下来,我们可以向表中插入一些示例数据。
INSERT INTO employees (id, name, position) VALUES(1, 'Alice', 'Manager'),(2, 'Bob', 'Developer'),(3, 'Charlie', 'Designer');
创建视图
现在,我们创建一个视图,这个视图将引用刚才创建的 employees
表。假设我们希望创建一个只显示员工姓名和职位的视图。
sql复制代码CREATE VIEW employee_view ASSELECT name, positionFROM employees;
查询视图
最后,我们可以查询这个视图,以查看其内容。
sql复制代码SELECT * FROM employee_view;
openGauss=# DROP TABLE IF EXISTS employees CASCADE;NOTICE: drop cascades to view employee_viewDROP TABLE
删除成功!
支持straight_join,在内连接中强制左右表的顺序,以左表驱动右表,而不是以开销大小驱动优化器选择执行顺序。
在 MySQL 中,STRAIGHT_JOIN
关键字用于强制优化器按照指定的表顺序进行连接操作。默认情况下,MySQL 的查询优化器会根据统计信息选择最优的执行计划,但有时你可能希望强制优化器按照特定的顺序进行连接,以确保性能或调试目的。
以下是使用 STRAIGHT_JOIN
的语法示例:
SELECT e.*,d.*FROM student as eSTRAIGHT_JOIN teacher as d ON a.tid = d.id;
在这个例子中,STRAIGHT_JOIN
强制优化器首先扫描 studetnt
,然后根据 student
的结果集来驱动对 teacher
的扫描。
在这个查询中,即使优化器认为扫描 teacher
表更高效,它也会按照 student
表的顺序进行连接操作。
注意事项
使用
STRAIGHT_JOIN
可能会影响查询性能,因为优化器通常会选择最佳的执行计划。在大多数情况下,建议让优化器自行决定执行计划,除非你有充分的理由相信手动指定表的顺序会提高性能。
通过这种方式,你可以控制连接操作的顺序,从而更好地满足特定需求或进行性能调优
支持interval内部表达式运算、列引用用法。
内部表达式基本用法
openGauss=# SELECT NOW(); -- 当前时间SELECT NOW() + INTERVAL '1 day'; -- 当前时间加一天SELECT NOW() - INTERVAL '1 hour'; -- 当前时间减一小时now-------------------------------2024-10-21 23:52:24.266345-07(1 row)openGauss=# ?column?-------------------------------2024-10-22 23:52:24.284025-07(1 row)openGauss=# ?column?-------------------------------2024-10-21 22:52:24.286283-07(1 row)
使用列引用
假设有一个表 <font style="color:rgb(67, 67, 107);">events</font>
,包含一个 <font style="color:rgb(67, 67, 107);">event_date</font>
列:
openGauss=# CREATE TABLE events (id INT PRIMARY KEY,event_name VARCHAR(255),event_date TIMESTAMP);CREATE TABLEopenGauss=#INSERT INTO events (id, event_name, event_date) VALUES(1, 'Event A', '2023-10-01 10:00:00'),(2, 'Event B', '2023-10-02 12:00:00');INSERT 0 2
查询事件日期加一天的结果:
openGauss=# SELECT id, event_name, event_date, event_date + INTERVAL '1 day' AS new_event_dateFROM events;openGauss-# id | event_name | event_date | new_event_date----+------------+---------------------+---------------------1 | Event A | 2023-10-01 10:00:00 | 2023-10-02 10:00:002 | Event B | 2023-10-02 12:00:00 | 2023-10-03 12:00:00(2 rows)
动态生成间隔表达式
有时你可能需要根据不同的条件动态生成间隔表达式。例如,根据用户输入的天数来计算新的日期:
openGauss=# DO $$DECLAREdays_to_add INTERVAL := '5 days'; -- 假设用户输入的天数是5BEGINRAISE NOTICE 'Current Time: %', NOW();RAISE NOTICE 'Future Date: %', NOW() + days_to_add;END $$;openGauss$# NOTICE: Current Time: 2024-10-21 23:58:14.986436-07NOTICE: Future Date: 2024-10-26 23:58:14.986436-07ANONYMOUS BLOCK EXECUTE
通过这些示例,你可以了解如何在openGauss中使用 INTERVAL
进行内部表达式运算、列引用以及动态生成间隔表达式用法。
performance、shrink关键字从保留字降级为非保留(不能是函数或类型)关键字。使得其可以作为表名/列名来使用。
在openGauss中,performance
和 shrink
这两个关键字已经从保留字降级为非保留(不能是函数或类型)关键字。这意味着它们可以作为表名、列名或其他标识符来使用。以下是一些示例,展示了如何在openGauss中使用这些关键字作为表名和列名:
创建包含 performance
和 shrink
的表
CREATE TABLE performance (id SERIAL PRIMARY KEY,name VARCHAR(255) NOT NULL,score INT);INSERT INTO performance (name, score) VALUES('John Doe', 90),('Jane Smith', 85);SELECT * FROM performance;
创建包含 performance
和 shrink
的列
假设有一个表 students
,我们可以在其中添加包含这些关键字的列:
CREATE TABLE students1 (id SERIAL PRIMARY KEY,name VARCHAR(255) NOT NULL,performance INT,shrink DECIMAL(5, 2));INSERT INTO students (name, performance, shrink) VALUES('Alice Johnson', 88, 0.25),('Bob Williams', 92, 0.40);SELECT * FROM students1;
通过以上测试用例,我们可以全面验证openGauss数据库在MySQL生态中的兼容性。通过这些测试用例,可以确保openGauss不仅在技术上与MySQL生态兼容,而且在实际应用中能够满足企业级用户的需求,为其平滑迁移到openGauss平台提供有力保障。
点击阅读原文跳转作者文章
