





本篇是2024 DA大会演讲《数智平台重回“战国时代“ - 新一代DA平台架构的设计原则与演进思路》 下篇,回顾上篇请查看《关涛:数智平台重回“战国时代“ - 新一代DA平台架构的设计原则与演进思路(上)》
本篇的主旨问题
AI的兴起可能会带来AI infra的兴起,那数据infra和AI infra的关系是怎样的? 他们两个应该是独立的自建? 还是应该合并到一起?
面向Data+AI,新一代数据平台架构演进思路
当AI进入数据领域后,数据平台该如何结合AI的力量?
回顾过去50年,一直到2020年,数据平台所处理的对象只有一种,那就是结构化数据,主要是二维关系表。而数据平台的处理能力,也几乎局限在对二维关系表的操作。
AI的出现,首次赋予了我们高效处理文本和图形数据的能力
在此之前,如果你把一个PDF文档交给大数据平台或数据库系统,它们充其量只能做一个倒排索引,帮你检索文档,而无法真正理解内容。同样,面对一张图片,它们也束手无策,还需要借助深度学习模型,提取出一系列标签,才能初步理解图片内容。
如今,大模型技术和多模态技术的崛起,使得我们能够轻松理解和处理各类非结构化、半结构化数据。这意味着,我们的数据处理架构,正从过去的"一对一"模式,转变为"多对多"的新范式。
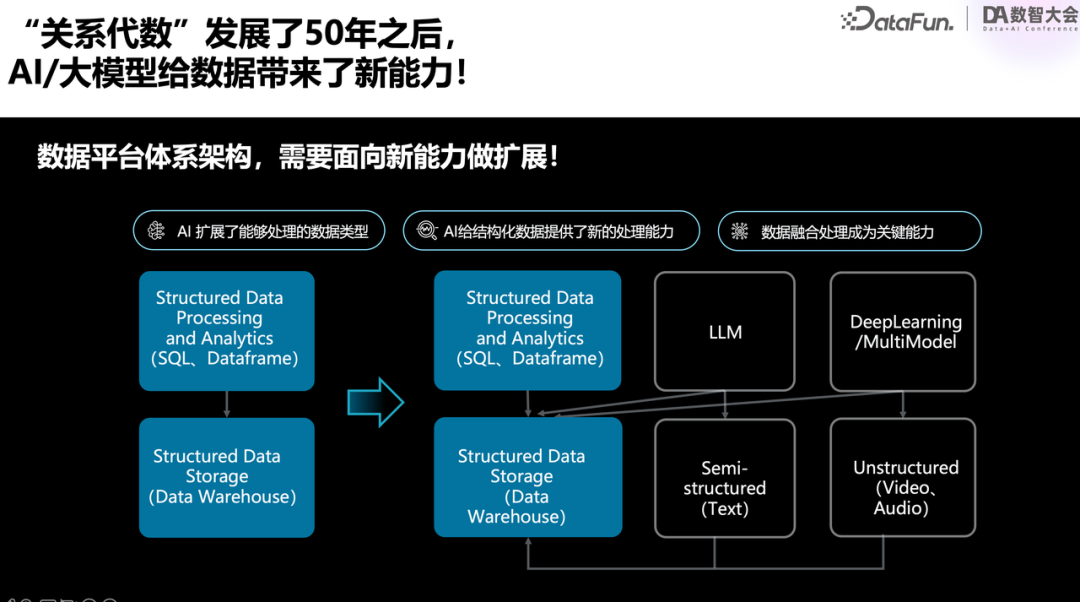
事实上,我们认为,文本数据可能只占全部数据量的10%到20%。而大量尚未被开发利用的"暗数据",恰恰是图片、视频等非结构化数据。因此,借助AI,我们所能处理的数据种类,将扩大10倍之多;与之对应,数据处理能力也会实现10倍以上的飞跃。
整个系统架构,也随之发生深刻变革。以前是"一对一"的紧耦合设计,所以数据仓库更为流行。而现在,随着"多对多"架构渐成主流,数据湖和湖仓一体化的趋势日益明显。
这背后的深层原因,正是AI大模型为数据领域注入的革命性力量。我们之所以将其视为第三次数据革命的起点,就在于它再次触及了"10倍能力"的边界。
如何构建Data+AI的数据系统,从数据的表达形式说起
那么,当我们真正拥有了这样的能力,该如何构建与之匹配的系统呢?在回答这个问题之前,不妨先来看看数据的不同表达形式。
下面是一段描述Meta公司过去三年营收的文本。我们可以清晰地从这段100个字节左右的文字中,获取所需信息。
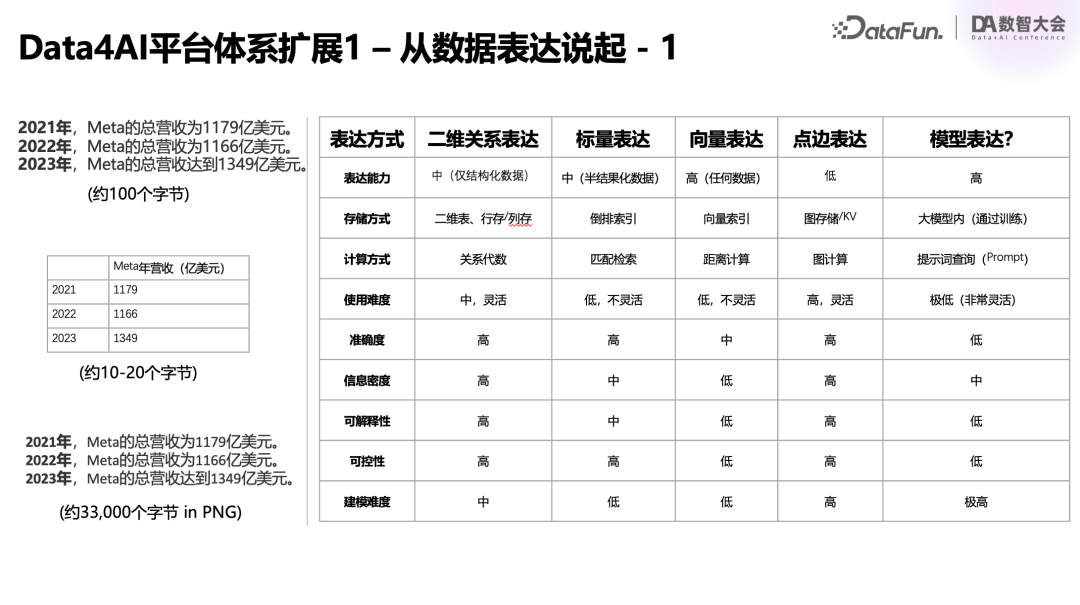
如果我将同样的内容抽象为一张二维表,你会发现它的结构更加清晰,数据量也进一步压缩到10-20个字节。这种列式存储和列式计算的方式,在数据压缩上有着出色的表现。
接着,我们把它以图片的形式呈现。虽然蕴含的信息没有改变,但数据量一下子暴增到了33KB。
由此可见,同样一组数据,在不同的表达形式下,呈现出迥然不同的面貌。今天,我们不妨梳理一下几种主要的数据表达方式:
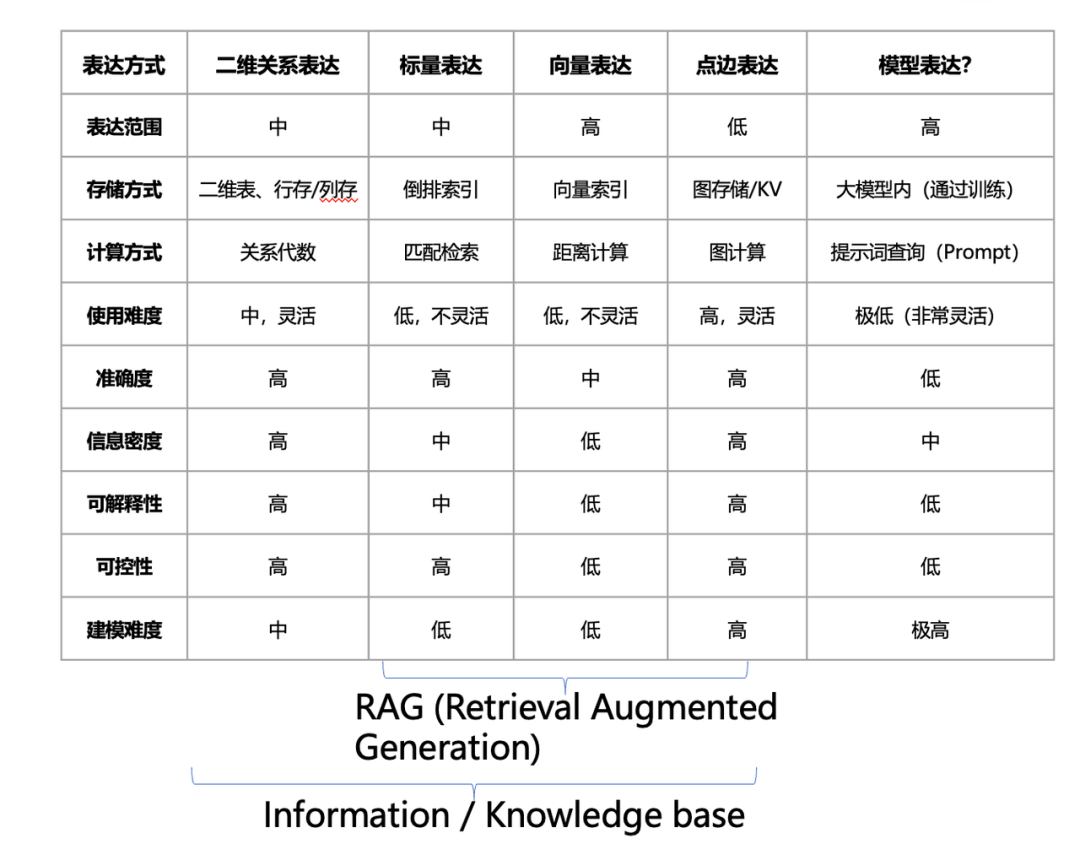
二维关系表达,对应的就是传统的表格化数据;
其次是标量表达,本质上是一种文本检索;
再有向量表达,虽然它是一串数字序列,但对普通人来说可能不太直观;
第四种称为点边表达,主要用于图计算领域,通过点和边来建模,在社交网络分析等场景有广泛应用;
最后一种是模型表达,它虽然还不是一个非常成熟和标准化的范式,但已在许多应用中崭露头角。它的核心思想,是把数据直接用于训练模型,然后通过向模型提问的方式获取所需信息。这在电商推荐领域越来越常见,比如最近Meta的一篇论文就介绍了他们的做法:将用户过去两年的所有浏览记录灌入大模型进行训练,然后直接用训练好的模型来预测每个用户下一步最可能观看的视频,取得了远超传统方法的效果。这就是一个典型的"模型即数据"的案例。
数据表达的演进方向
技术的演进,特别是AI的发展,极大地扩展了数据处理的边界。过去,我们只能处理结构化数据,但现在,借助AI技术,我们可以轻松理解和分析各种非结构化数据,如文本、图像和视频等。这意味着,我们所能处理的数据种类,将比以前多出10倍以上,数据处理能力也会实现10倍以上的飞跃。
同一份数据可以有多种不同的表达方式。可以用文本描述、二维表呈现,也可以可视化为图表。在数据处理系统中,这些不同的表达方式各有其独特价值。一个先进的数据处理系统,应该能够支持数据的多元表达,并在不同表达形式之间实现无缝转换。
随着数据处理技术的发展,数据表达正朝着更高的准确性、信息密度和可解释性方向演进。过去,为了追求处理效率,我们常常把数据直接喂给模型来训练,而忽略了数据本身的质量和语义。然而,这种做法存在很多问题,如无法对数据访问权限进行精细控制,模型输出结果缺乏可解释性等。因此,未来的数据处理系统必须在提高效率的同时,更加注重数据质量、语义和可解释性。这也是数据平台与AI平台要深度融合的重要原因之一。

这是前两天我看到阿里巴巴和中国科学院发表的一篇论文,其核心思想就体现在这张橙色的图上。论文提出,你可以有图(Graph)、目录(Catalogue)、块(Chunk)、算法(Algorithm)、表(Table)等多种数据表示形式,至于具体采用哪种形式,可以通过一个路由器(Router)来选择。这与前面提到的"同一份数据可以有多种表达方式"不谋而合。系统可以根据需求,自动选择最合适的数据表达,然后利用统一的基础架构(Infrastructure)来支撑整个处理过程,最终得到想要的结果。
存储的演进方向
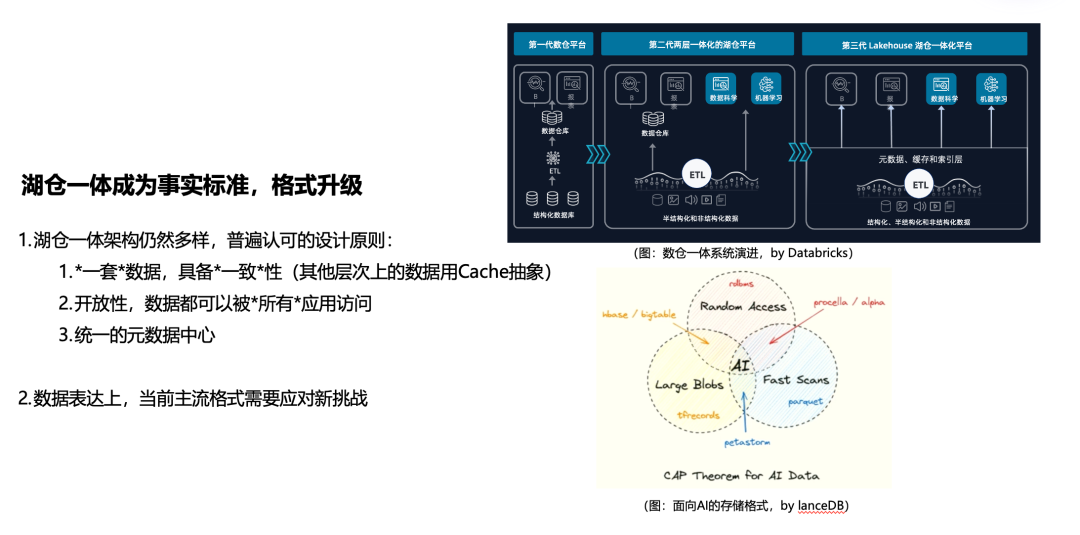
存储系统的发展趋势是湖仓一体化架构,这一点业界已有共识。而在存储格式方面,虽然Parquet目前是数据平台上最流行的格式,但业界正在探索更适合AI系统的新格式。比如Lance就尝试兼顾Parquet的快速扫描能力、tfrecord的大对象存储能力以及数据库系统的随机访问能力。虽然Lance最终能否成为标准还未可知,但这种融合不同系统优势的方向是明确的。随着海量半结构化和非结构化数据的涌入,对大对象存储和随机访问能力的需求日益增长。Parquet社区正积极讨论如何演进,以更好地处理这些AI场景下的数据。
元数据管理的演进方向
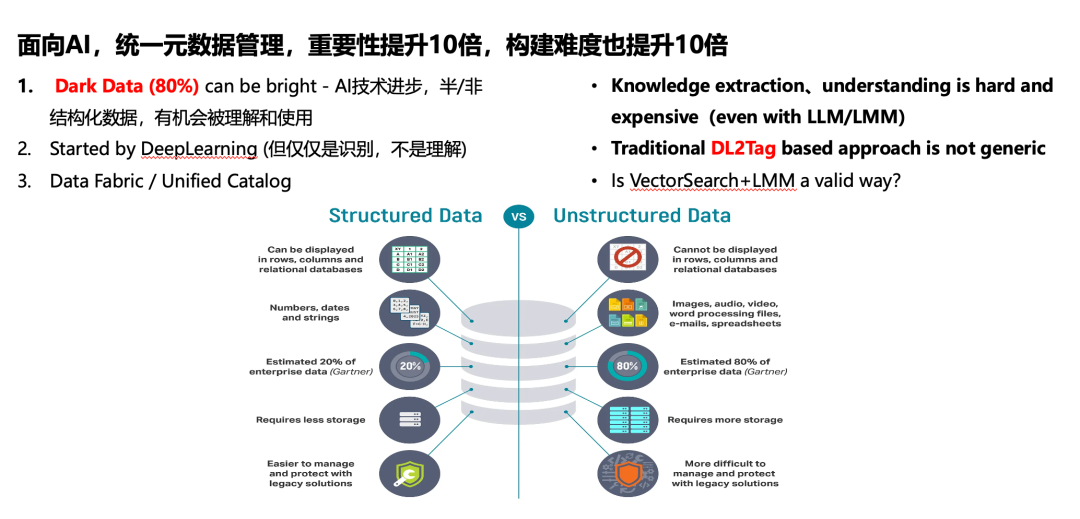
元数据系统是另一个关键的扩展方向。对于结构化数据,元数据管理相对简单,因为它们天然带有模式(schema)信息。但对于半结构化和非结构化数据,元数据管理却极具挑战。设想你有10万张图片或文档,如果把它们作为独立对象存储,你会发现它们几乎无法使用,除了做模型训练之外别无他用。而苹果等公司正在努力解决这一问题,本质上就是元数据管理。当你能很好地管理系统中各种数据,特别是半结构化和非结构化数据的元数据时,系统的能力就会得到极大提升。比如,你可以轻松找到所有与财务或HR相关的信息。良好的元数据管理可以让数据变得非常灵活可用。业界已有许多相关尝试,如Databricks开源的Unified Catalog、Snowflake开源的Polaris等。虽然目前还没有统一的标准,但面向AI的统一元数据系统已成为业界必争的领域,它的重要性可以提升10倍,但难度也会提升10倍,因为从半结构化和非结构化数据中提取和管理元数据本身就是一个挑战。
ETL Pipeline的演进方向
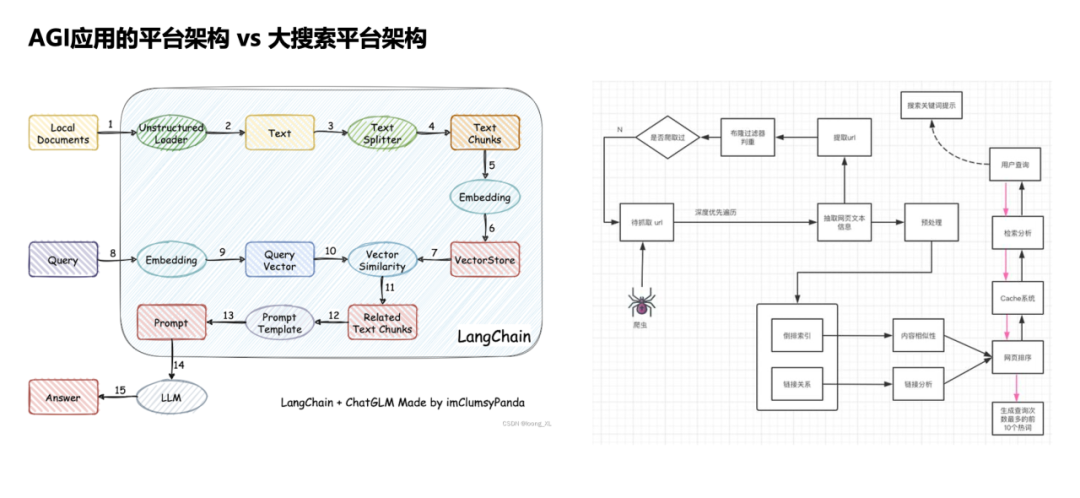
最后一个扩展方向是Pipeline。左图展示了一个典型的AGI系统架构:数据经过分块(chunking)、嵌入(embedding)后存入向量库,当查询(query)到来时,也做嵌入,然后到向量库中召回(recall),形成提示(prompt)输入大模型。有意思的是,这与20年前的搜索引擎架构(如右图)几乎一模一样。爬虫爬取网页,对新网页做分块和预处理,建立索引存入库中,查询来临时也做分词,然后召回、融合排序,最后返回结果。可以看出,这两种架构在数据处理流程上惊人地相似。
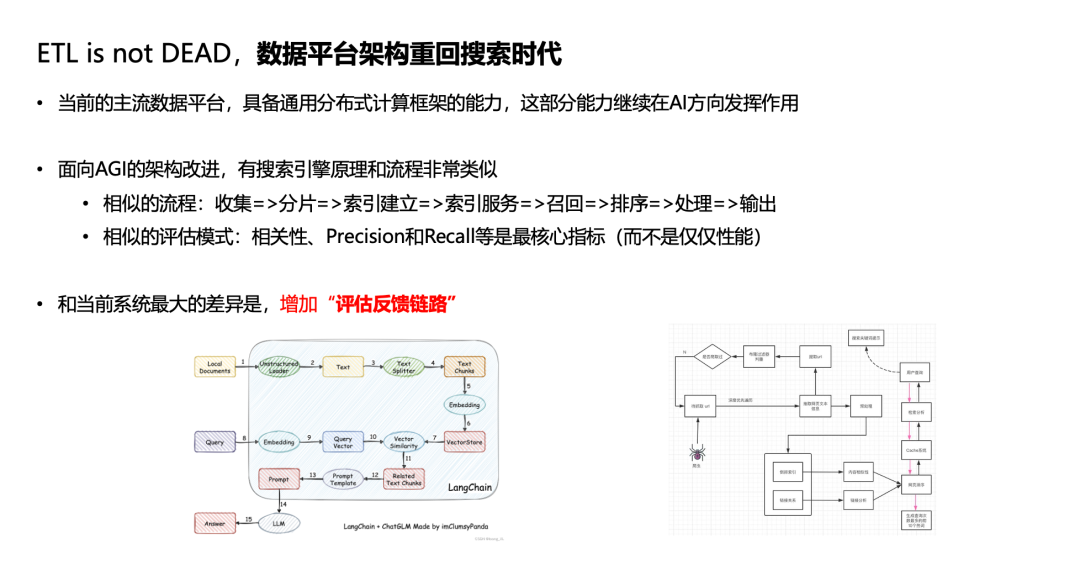
那么,在面向未来的数据平台架构中,哪些环节可以复用,哪些是新的呢?数据导入和处理流程都可以被重用,而反馈链路(如红字所示)则是新的关键环节。传统的大数据处理平台是一个从前到后的过程,数据处理完毕后生成报表,就算大功告成,报表是100%准确的。但面向AI时,就像搜索引擎一样,结果不可能100%准确,需要有一个评估反馈环节,再回馈到系统中不断迭代优化。这是当前面向ETL的数据平台需要做出的一个重大改进。
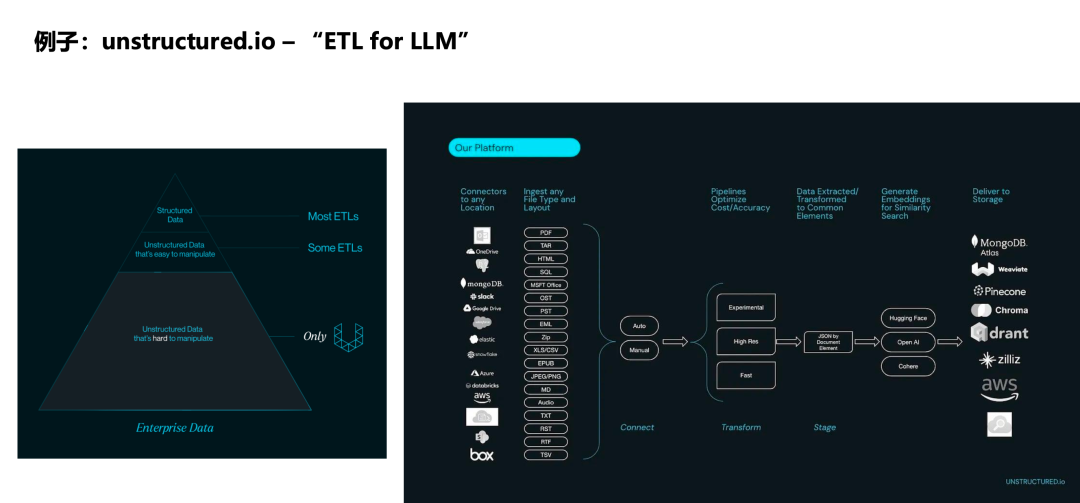
业界已有一些相关的尝试,比如一家叫做unstructured.io的创业公司,它的核心理念是为非结构化数据构建ETL Pipeline,名字叫做"ETL for LLM"。它的架构建议与大数据平台高度相似,也是由数据同步、数据处理、数据服务等环节构成,本质上是一个典型的ETL流程。随着大数据平台的演进,我们其实可以很容易地覆盖这些场景,因为像Spark这样的系统并不是单纯的数据库,而是一个通用的分布式计算框架,可以在上面实现任何功能。
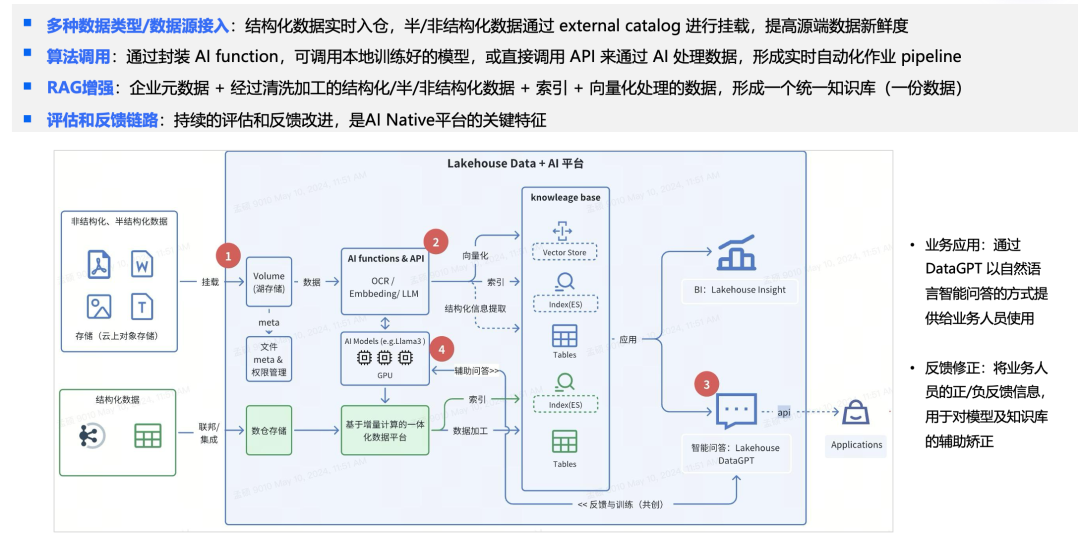
我们在自己的系统中也做了一些尝试,试图将结构化数据与半结构化、非结构化数据统一起来。我们引入了一个叫"Volume"的概念,用来表达数据湖中的半结构化和非结构化数据。此外,我们还集成了许多AI算法,可以调用云上的API服务,比如识别一篇文档并将结果存入系统。我们建立了一个统一的知识库(Knowledge Base),其中包含表格和其他各种数据表示形式,这些表示会被转化为不同的索引,如向量索引、标量索引等。最终,我们形成了一套服务,并构建了一个简单的反馈闭环,可以将反馈信息持续加入到系统中,优化系统性能。
以上就是这次分享的全部内容,感谢大家!

END
▼点击关注云器科技公众号,优先试用云器Lakehouse!
关于云器
往期推荐
