




今天分享的是ACL 2024大会的一篇论文:
Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs

论文链接:
https://aclanthology.org/2024.findings-acl.11.pdf
代码链接:

01
介绍
大型语言模型(LLMs)虽然表现出优异的性能,但也会产生幻觉,尤其是在知识密集型任务上。现有的研究通过从外部知识语料库中检索单个文本单元来增强LLMs,以缓解这个问题。然而,在许多领域,文本是相互关联的(例如,学术论文在文献图谱中通过引用和合作关系相互链接),这些文本构成了一个(带有文本属性的)图。这种图中的知识不仅编码在单个文本/节点中,还编码在它们的关联连接中。虽然检索增强广泛地用文本语料库作为外部知识来源,但其不能轻易地直接用图来增强LLMs,主要原因包括:
1. 结构上下文:RAG可以从图中找到单个节点/文本,这些节点/文本可以作为上下文来增强LLMs。然而,图上的知识也存在于不能被单个节点/文本捕获的结构中。
2. 图规模膨胀:虽然将局部子图结构转换为文本描述作为LLMs的输入上下文是可行的,但随着跳数的增加,局部子图的大小呈指数增长,导致上下文序列过长,这可能会导致LLMs陷入大量无关信息中。另外,序列过长可能会超过LLMs的输入长度限制。
为了解决上述问题,本文提出了 GRAPH-COT 框架,它通过链式推理逐步从图中获取关键信息,而非直接将整个子图作为上下文输入。通过这种方式,GRAPH-COT允许LLMs在图上进行链式推理,逐步获取关键信息,解决了传统RAG方法中的问题。
02
GRAPH-COT框架
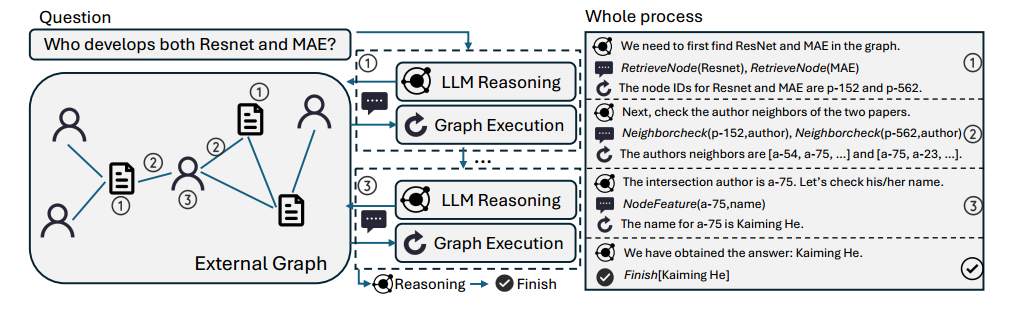
GRAPH-COT 是一个迭代框架(如上图所示),每次迭代包括三个步骤:推理、交互和执行。以下是每个步骤的详细解释:
1. 推理 (Reasoning)
步骤:在每轮迭代的开始,模型会基于问题或之前的上下文信息进行推理,以确定接下来需要从图中获取的外部信息,或者判断现有的图数据是否足够回答问题。
示例:例如,给定问题 “Language Models are Unsupervised Multitask Learners的作者是谁?”,模型应该推理出 “我们需要先在图中找到论文节点 {Language Models are Unsupervised Multitask Learners} 。”
推理步骤帮助模型在图上逐步缩小信息范围,选择有效的查询路径,并确保接下来的步骤能有针对性地获取信息。
2. 交互 (Interaction)
步骤:在推理的基础上,LLMs 生成一系列图函数调用,以便获取与问题相关的信息。此步骤通过以下预定义的函数实现与图的交互:
RetrieveNode(Text):通过语义搜索在图中定位相关节点。
NodeFeature(NodeID, FeatureName):提取图中指定节点的文本特征信息。
NeighborCheck(NodeID, NeighborType):返回图中指定节点的邻居信息。
NodeDegree(NodeID, NeighborType):返回特定节点的某种类型邻居的度。
示例:对于上一步的例子,本阶段LLMs应生成“RetrieveNode(Language Models are Unsupervised Multitask Learners)”。
这些预定义函数为 LLMs 提供了一个标准化的接口,使得模型能够有效地与图结构进行交互,获取问题所需的信息。
3. 执行 (Execution)
示例:在之前的例子中,图将执行 RetrieveNode(·) 函数并返回“最相关的论文节点ID是 p-4123”。然后当前迭代结束,并从“reasoning with LLMs”开始新一轮迭代。整个框架将不断迭代,直到LLM完成推理并输出最终答案。
03
总结

