一、首先我们要理解ticdc 原理
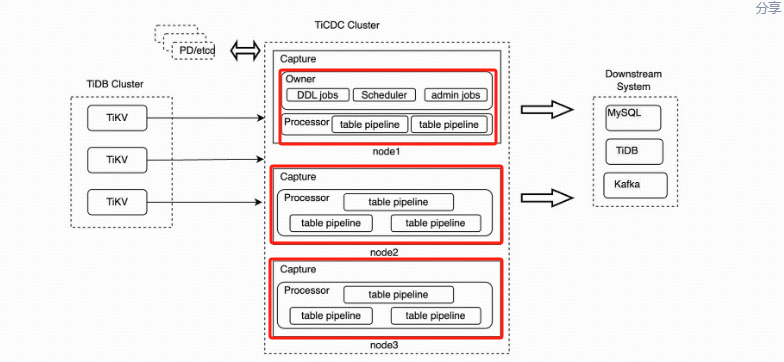
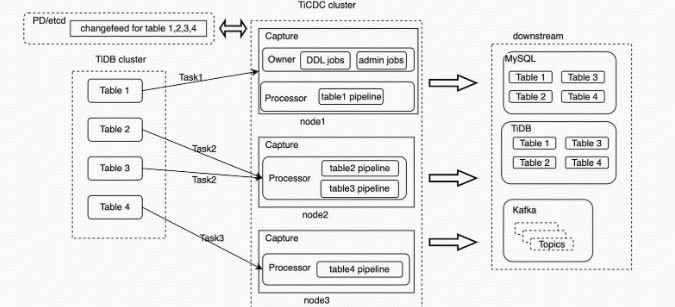
TiCDC 集群由多个对等节点组成,是一种分布式无状态的架构设计。当 TiDB 集群内部有数据变更的时候,就会产生 KV change log。
KV change log 是 TiKV 提供的隐藏大部分内部实现细节的的 row changed event,TiCDC 会实时从 TiKV 拉取这些 Event 完成扫描和拼装,再同步到下游节点。同步任务将会按照一定的调度规则被划分给一个或者多个 Capture 处理。
为了方便深入了解 Capture 的执行过程,需要理解一些概念:
- Owner 可以理解为是 TiCDC 集群的 leader 节点,它负责响应用户的请求、调度集群和同步 DDL 等任务。
- Processo Capture 内部的逻辑线程,一个 Capture 节点中可以运行多个 Processor。
- Table Pipeline Processor 内部的数据同步管道,每个 TablePipeline 负责处理一张表,表的数据会在这个管道中处理和流转,最后被发送到下游。
- Changefeed 是由用户启动同步任务,一个同步任务中可能包含多张表,这些表会被 Owner 划分为多个子任务分配到不同的 Capture 进行处理。每个 Processor 负责处理 ChangeFeed 的一个子任
- TiCDC 的 DML 同步流和 DDL 同步流是分开的。从上面的架构图中可以看到, DML 的同步是由 Processor 进行的,数据流从上游的 TiKV 流入经过 Processor 内的 TablePipeline ,最后被同步到下游。而 DDL 同步则是由 Owner 进行的,OwnerDDLPuller 拉取上游发生的 DDL 事件,然后在内部经过一系列的处理之后,通过 DDLSink 同步到下游。
- OwnerSchemaStorage:由 Owner 持有,维护了当前所有表最新的 schema 信息,这些表的 schema 信息主要会被 scheduler 所使用,用来感知同步任务的表数量的变化;此外,还会被 owner 用来解析 ddlPuller 拉取到的 DDL 事件。
- ProcessorSchemaStorage:由 Processor 持有,维护了当前所有表的多个版本的 schema 信息,这些信息会被 Mounter 用来解析行变更信息。
- BarrierTs:由 Owner 向 Processor 发送的控制信息,它会让 Processor 把同步进度阻塞到 BarrierTs 所指定的值。TiCDC 内部有几种不同类型的 BarrierTs,为了简化叙述,本文中提到的 BarrierTs 仅表示 DDL 事件产生的 DDLBarrierTs。
- OwnerDDLPuller:由 Owner 持有,负责拉取和过滤上游 TiDB 集群的 DDL 事件,并把它们缓存在一个队列中,等待 Owner 处理;此外,它还会维护一个 ResolvedTs,该值为上游 TiKV 发送过来的最新的 ResolvedTs,在没有 DDL 事件到来的时候,Owner 将会使用它来推进 DDLBirrierTs。
- ProcessorDDLPuller:由 Processor 持有,负责拉取和过滤上游 TiDB 集群的 DDL 事件,然后把它们发送给 Processor 去更新 ProcessorSchemaStorage。
- DDLSink:由 Owner 持有,负责执行 DDL 到下游。
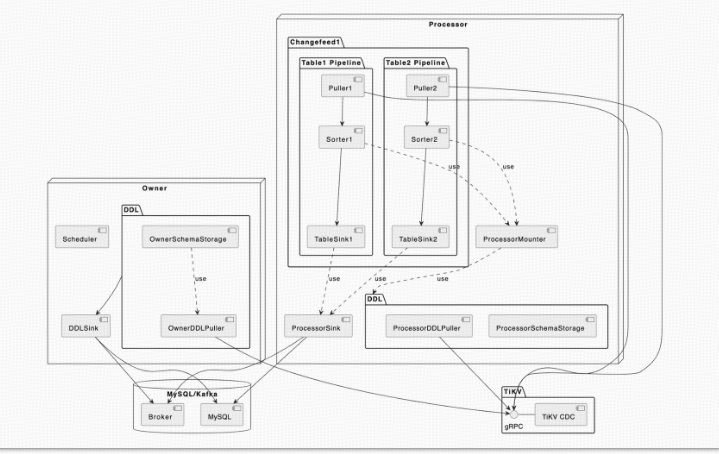
Table Pipeline
每个同步任务,负责同步一张或者多张表,TiCDC 的同步对于单表来说是单线程的,对于多表之间的同步是并行的。对于每个表的处理过程,会放在一个 Table Pipeline 流程内执行完成。TablePipeline 就是一个表数据流动和处理的管道。
TiCDC 的 Processor 接收到一个同步子任务之后,会为每一张表自动创建出一个 TablePipeline,它主要由 Puller、Sorter、Mounter 和 Sink 之间是串行的关系,组合在一起完成从上游拉取、排序、加载和同步数据到下游的过程。
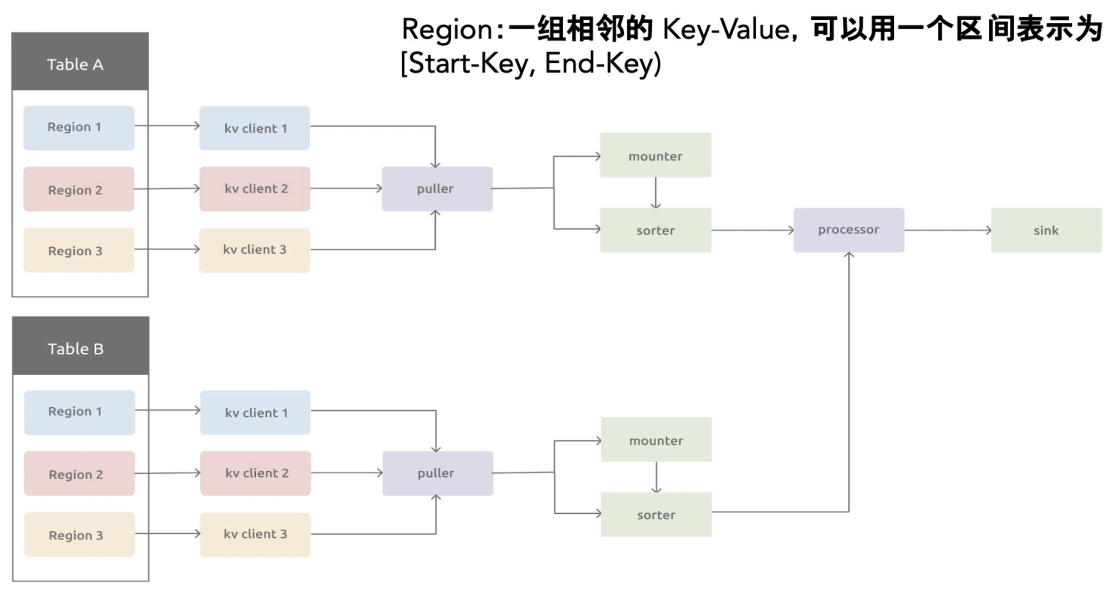
多表同步任务
假设我们创建一个 Changefeed 任务,要同步
test1.tab1、test1.tab2、test3.tab3和test4.tab4四张表。TiCDC 接收到这个命令之后的处理流程如下:- TiCDC 将这个任务发送给 Owner Capture 进程。
- Owner Capture 进程将这个任务的相关定义信息保存在 PD 的 etcd 中。
- Owner Capture 将这个任务拆分成若干个 Task,并通知其他 Capture 进程各个 Task 需要完成的任务。
- 各个 Capture 进程开始从对应的 TiKV 节点拉取信息,进行处理后完成同步。
resolved ts 的作用在 tikv 与 ticdc 里的 作用 :
cdc 的同步最主要是靠 resolved ts 作为标记推动数据同步
resolved ts 是仅包含时间戳的 event ,收到该 event 表明该时间戳之前行变更都已经发生了,对应的模块放心处理,不用担心数据的完整性,即后面不会有小于该时间的行变更到来由于具备上述的特性,resolved ts 在各个模块里面起到了推动数据流前进的作用
Puller 眼中的 resolved ts
tikv client 是按照 region 拿到 resolved ts,在 puller 中,会按照表为单位对 resolved ts 进行合并,计算出一表级别的 resolved ts。
注意,puer7 88= 的event ,但是会缓存并过滤(合并)或生成新的 resolved tsevent ,这会导sorter 会收到 cormmus>resolved ts 的行变更 event 。对于一张表,理论上,Puller 输出的 resolved ts 是不会发生回退的。下游Sorter 对此有一个 panic 的判断
sorter 眼中的 resolved ts
sorter 会按照 ts 所有的 event 进行排序(包含 resolved ts),因此典型排好序的数据如下:table1: event11event12 |resolved ts13|event14 |resolved ts 15| event 16 |event 17这时,对于 table1 最大的 resolved ts为resolved ts15.
Redo log 眼中的 resolved ts
Redo log 模块从 sorter 中取到某个 resolved ts event ,以表为单位将 commit ts 小于该 resolved ts 的数据写入到 S3 中,完成后,更新该表的 resolved ts ,如上例中的 ts13,注意此刻该 resolved ts<= sorter 中的resolved ts .
Sink 眼中的resolved ts
sink 模块以 resolved ts 为约束,将该 resolved ts 之前的数据都同步到下游,为了保证一致性,引入了barrier ts 来做全局讲度的约束。sink 模块的 resolved ts 计算方式: min( barrier ts.resolved ts fromsorter)。 其中 barrier ts 的计算方式可参考后面的内容。Processor 眼中的 resolved ts
processor 维护了当前节点的 local resolved ts,定期汇报给 owner ,owner汇总后计算出一个全局的global resolved ts。 local resolved ts 的计算的方式为査询当前节点上所有表的 resolved ts,得到最小的resolved ts ,对于每张表,如果开了 redo l0g ,就是redo l0g 维护的 resolved ts ,如果没开,就是 sorter 维护的 resolved ts 。
Owner 眼中的 resolved ts
owner 计算汇总所有的 processor 上报的 local resolved ts,计算得到一个最小的 resolved ts ,即 alobalresolved ts,将该 resolved ts 作为一种 barrierTs,发送给 processor。注意:全局最小的 resolved ts 可能会回退,场景:表发生迁移的时候,会用全局最小的 checkpoint 作为当前表的start ts ,resolved ts = start ts = global checkpoint ts< global resolved ts,此时该节点会重新计算local resolved ts ,根据前面的章节,我们可以得知新计算的得到的local resolved ts< alobal resolved ts,因此 global resolved ts 会发生回退Barrier ts
Barrier ts 产生的目的是产生一个 ts0 ,确保大于该 tso 的数据不能写入到下游,方式是用该 barrier ts 约束每个 Processor 节点上的 resolved ts 推进,即 sink 收到的 resolved ts < barrier ts。Barrier ts 由 owner 周期性产生,经过一系列复杂逻辑的计算(主要确保 resovled ts<barrierts),得到一个全局的 checkpoint ts和 Resolved ts,并将这个值广播给 Processor,Processor 会用 Resolved ts 产生barrier ts,更新所有 table 上的 sorter 和 sink barrier 对应的值。
目前有四种情况会产生 Barrierts,分别如下:
DDL Barrier ts
DDL barrier ts 是由 DDL puller 产生的,DDL puller 会从 tiky 侧接受 DDLevent,为了保证所有committs 大于该 ddl finished ts 的 DML不要先同步到下游,owner 会设置对每个 DDL 设置一个 barrier ts该 ts= ddl finished ts .
当所有的表都已经同步到 ddl barrier ts 时,owner 执行 ddl后,更新 ddl barrier ts 为下一个 DDL的finished ts ,这样就达到了上述目的。
Sync Point Barries ts
Sync Point 的工作原理和 DDL 比较类似,可以理解为定时产生一个 DDL,即定时设置一个 barrier ts,让所有的表都同步到该 ts 对齐之后,记录一个时间点,再继续往下同步。
说明:DDL& Sync Point 对齐所有表的进度的方式是通过判断 global checkpointts和 barrier ts 的关系来实现的。 DDL& Sync Point 设置了 barrier ts 后,sink 模块会严格限制所有表往下游写的 event 要<=barrier ts,当 global checkpoint ts= barrier ts 时,即表明所有的表中小于 barrier ts 发生的行变更都已经同步到下游了,而且不会有超过 barrier ts 的数据变更同步到下游了,因此该时刻下游处于一致性状态。
Redo log Barrier ts
Redo log 的作用是让下游恢复成上游的某个 tso 对应的 snapshot,因此会实时计算 min global resolvedts ,并以此 ts 为约束设置 barrier ts ,让所有的 sink不要下推超过此 ts的 event 。这样在恢复的时候,Redo l0g 可以 apply 所有处于(checkpoint ,resolved ts]之间的数据,这样将下游恢复为 global resolved ts对应的 snapshot.Gobalresolved ts
owner 计算所有 processor 上的 resolved ts ,得到一个最小 resolved ts,并设置为 barrier ts,目的是希望能保证所有表都能保持相同的 sink 进度。(该 barrier 在 6.4 版本之后已经去掉)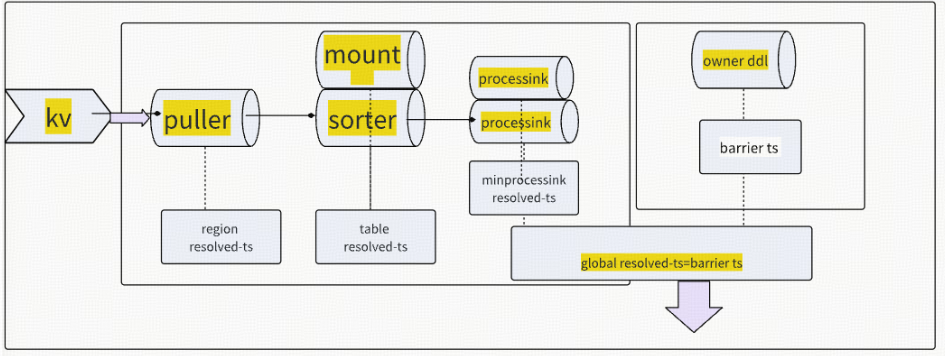
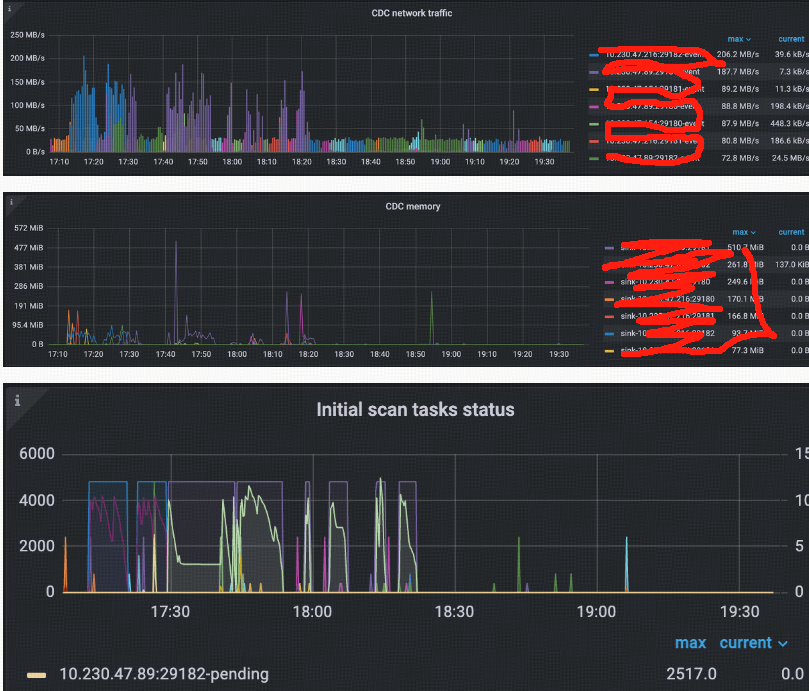
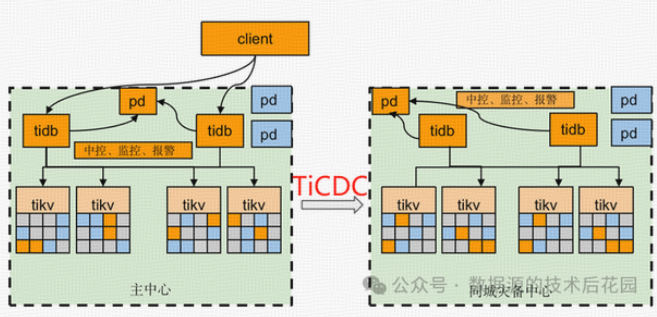
- 在很多金融用户中 大多采用 主从集群 通过cdc 同步 然后根据大部门客户实际使用场景来看 从集群作为一个读负载去使用, 从集群只能承接OLAP 类查询 ,主集群承担所有 oltp 类查询。cdc 有个默认的200ms 的等待时间我们从上面的原理中理解,cdc 有个统计全局推进时间的动作 ,此动作也受上游 KV 的一些时间影响 导致延迟 比如 大事务热点写入等 锁等待等 影响所以无法做到 实时同步 ,正常情况大概在1-7 秒的一个正常情况
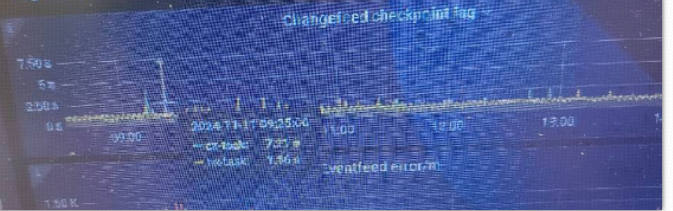
TiCDC 整体指标
Changefeed checkpoint lag:
同步任务上下游数据的进度差,以时间单位秒计算。如果 TiCDC 消费数据的速度和写入下游的速度能跟上上游的数据变更,该指标将保持在较小的延迟范围内,通常是 10 秒以内。如果 TiCDC 消费数据的速度和写入下游的速度跟不上上游的数据变更,则该指标将持续增长。
TiCDC checkpoint lag 增长的常见原因如下:
系统资源不足:如果 TiCDC 系统中的 CPU、内存或磁盘空间不足,可能会导致数据处理速度过慢,从而导致 TiCDC Changefeed checkpoint 过长。
网络问题:如果 TiCDC 系统中存在网络中断、延迟或带宽不足的问题,可能会影响数据的传输速度,从而导致 TiCDC Changefeed checkpoint 过长。
上游 QPS 过高:如果 TiCDC 系统需要处理的数据量过大,可能会导致数据处理超时,从而导致 TiCDC Changefeed checkpoint 增长,通常一个 TiCDC 节点处理的 QPS 上限为 60K 左右。
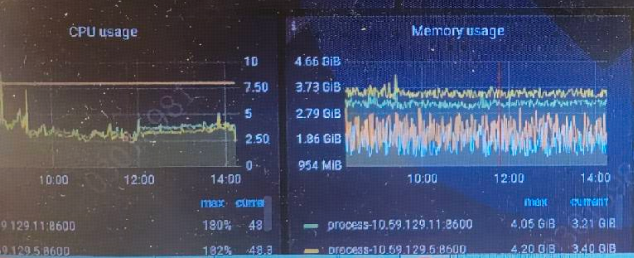
数据库问题:
上游: TiKV 集群 min resolved ts 和最新的 PD TSO 差距过大,通常是因为上游写入负载过大,TiKV 无法及时推进 resolved ts 造成。
下游: 数据库写入延迟高导致 TiCDC 无法及时将数据同步到下游。

Changefeed resolved ts lag:
TiCDC 节点内部同步状态与上游的进度差,以时间单位秒计算。如果 TiCDC Changefeed resolved ts lag 值很高,
1.看TiCDC 系统的 Puller 或者 Sorter 模块数据处理能力监控,
2.或者可能存在网络延迟或磁盘读写速度慢的问题。在这种情况下,需要采取适当的措施,例如增加 TiCDC 实 例数量或优化网络配置,以确保 TiCDC 系统的高效和稳定运行。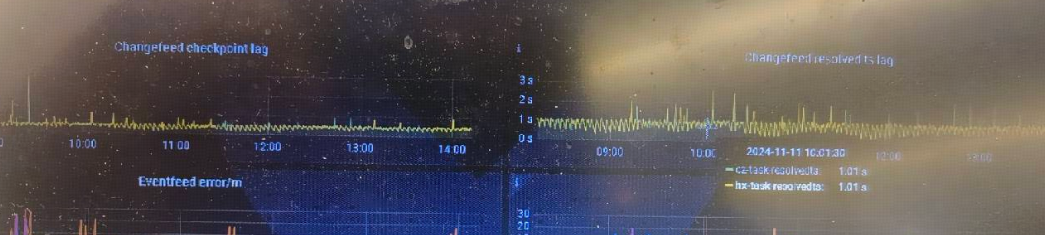
大事务确认 dashboard ->日志搜索 “BIG_TXN”
1.大事务
问题描述:
在V6.2之前的版本,TiCDC对大事务支持较差。在遇到大事务时经常会出现同步卡住的情况。在v6.2开始TiCDC会自动拆分大事务。可通过sink uri参数控制
transaction-atomicity:指定事务的原子性级别(可选,默认值为 none)。当该值为 table 时 TiCDC 保证单表事务的原子性,当该值为 none 时 TiCDC 会拆分单表事务。
监控:
大事务确认 dashboard ->日志搜索 “BIG_TXN”
grafana -> TiDB -> Transaction Write KV NUM
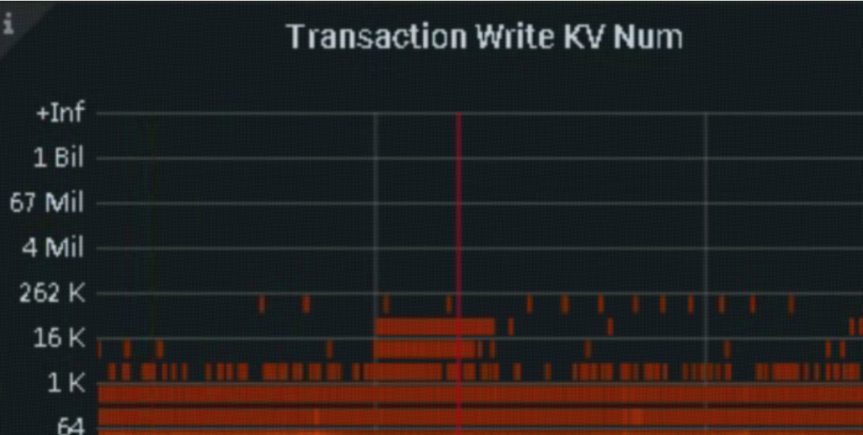
2.上游TiDB OOM导致残留锁
问题描述:
TiDB服务器发生OOM时,系统可能会尝试通过杀死一些进程来释放内存。在这个过程中,正在执行的SQL语句或事务可能会被中断,导致一些锁(如乐观锁或悲观锁)未能正常释放。如果TiDB服务器OOM导致锁未释放,这些锁可能会阻塞TiKV节点中的resolve lock过程,进而影响Resolved TS的推进,可以通过手动解锁的方式进行释放。
监控:
可以通过Grafana监控查看监控延迟TiKV -> Resolved-TS

cdc 配置增加增量扫描:
- cdc.incremental-scan-threads = 12,默认为 4.
- cdc.incremental-scan-concurrency = 20,默认为 6.
- cdc.incremental-scan-speed-limit = 512 MB,默认 128 MB.
上述改变主要是加快增量扫的速度。
raftstore.split-region-check-tick-interval = 10m,降低 region split 的频率。
1. 频繁 DDL 执行,导致 Resolved Ts 延迟上升
建议方法
1. 确认频繁 DDL 执行的场景引入原因和时间。
2. 考虑拆 changefeed,把频繁执行 DDL 的表给拆出来,单独建立 changefeed 同步,减少影响范围。
3. 调整 Truncate table 操作的执行时间,在业务低峰期执行,避免在有大流量写入时执行。
4. 是否可能通过修改业务模式的方式,避免执行 truncate partition ddl。
2.TiKV 大流量写入,导致 Memory Quota 处于高水位,触发 Region 熔断
建议方法
对于一个 Region 上有很多小表的情况,该 Region 订阅过程中发生的错误,导致该 Region 上的所有表重新订阅该 Region,并且针对整个 Regio+n 范围进行增量扫,发送数据到 TiCDC,TiCDC 收到数据之后,会过滤掉和表无关的部分数据。这导致的问题是,增量扫耗时长,增量扫任务多,增量扫环节整体耗时长。如果在此过程中,Region 发生了迁移等现象,会进一步拉长时间。
解决的基本思路是,减少 Region 上的表数量,降低 Region 错误导致的重新增量扫的影响范围,即减少因为 Region 错误引发的表订阅任务数量。*