




没想到我认为颇有难度的“FBI警告”系列第三篇,有4000多的浏览量:

图1
排在我所有技术类文章的第一位。既然大家这么爱学习,“FBI警告”系列我一定会继续下去,定要把牛马(NUMA)的底裤扒掉,把她一览无余、玉体横陈在大伙面前。
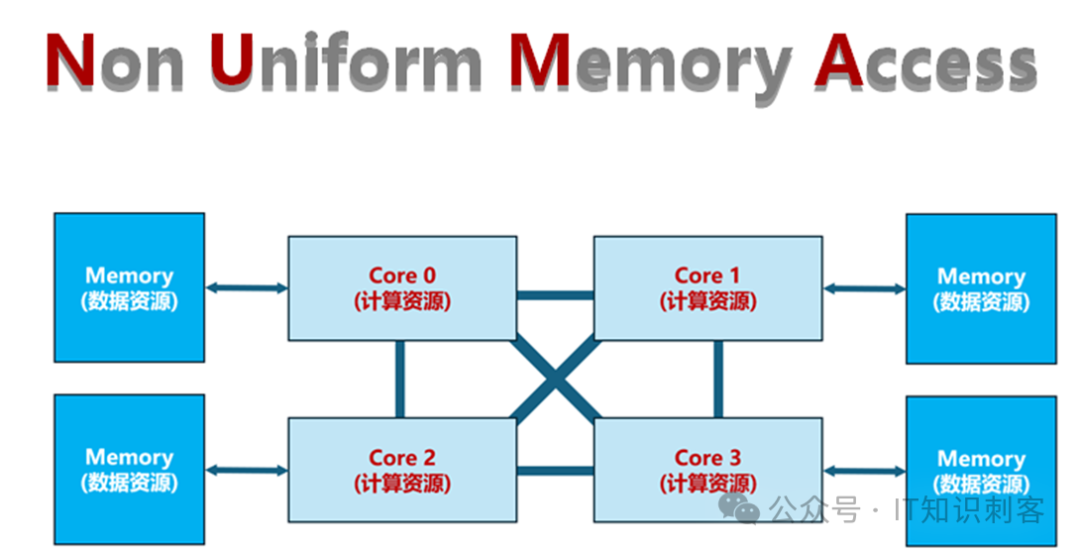
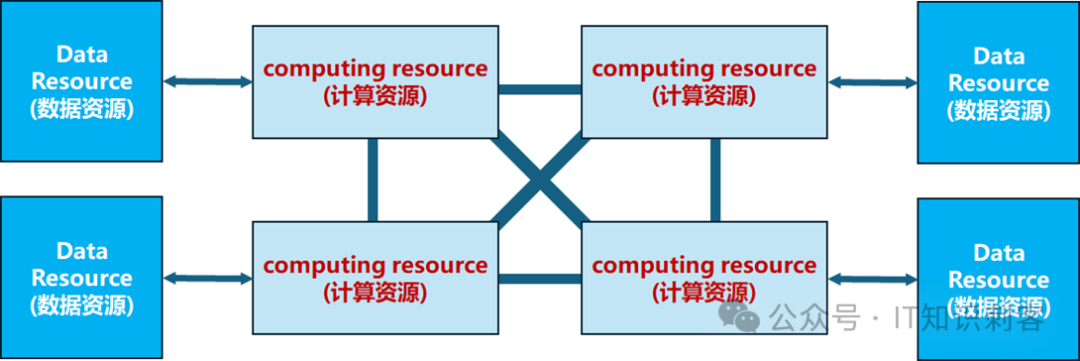
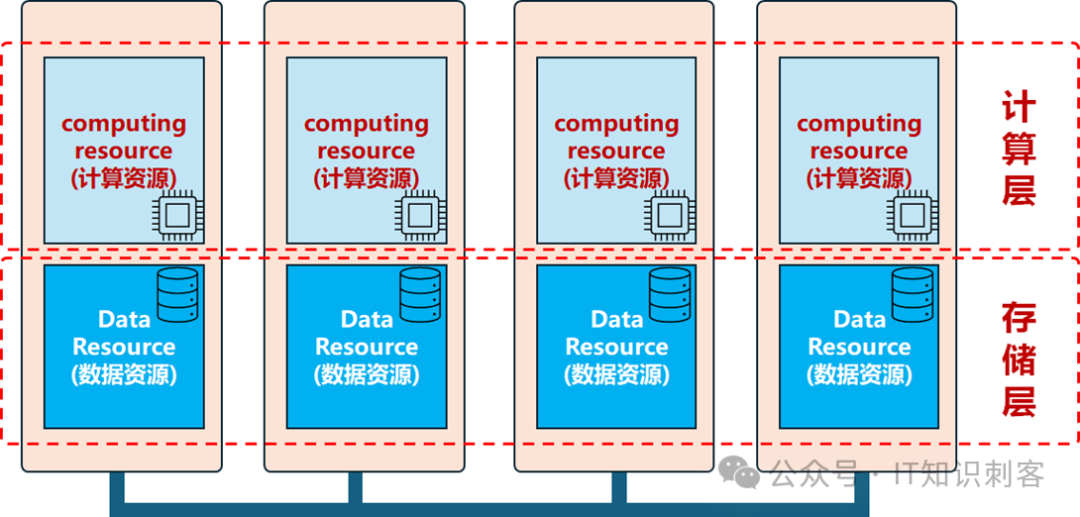
图3
牛马测试程序:numa1.c
https://gitee.com/itkassassin/numa_-test1/blob/master/numa1.c
cur_cpu = sched_getcpu();
setcpu(start_cpu_id); // 按参数指定CPU运行
mem=(TYPE *)smem();
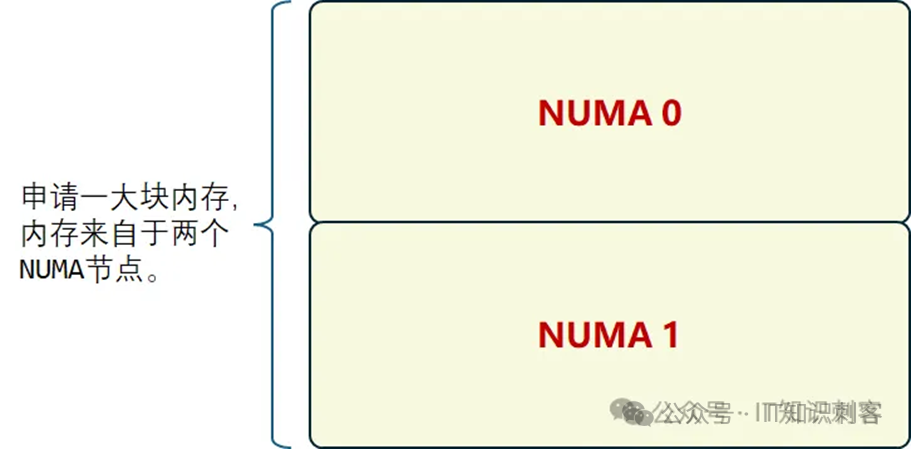
图5 来自上一篇
我想分一大块内存,这块内存来自于两个NUMA节点,然后测试跨不同节点的延迟。
但我每个NUMA节点都有几十G内存,太大了,怎么办。像图6这样:

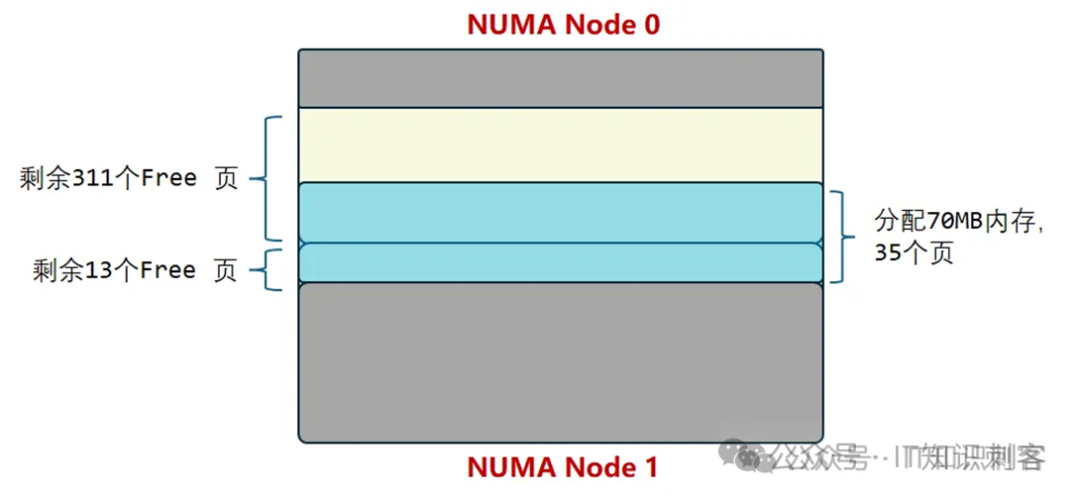
图7 图片来自上一篇
上一篇的测试中,在NUMA
1的CPU上,分配70MB内存,26MB来自NUMA 1,剩下的来自NUMA 0。
这就是优先使用大页的原因,容易控制所能使用的内存大小。
继续回来说测试程序。
在195行:
myinit(mem, control_number[1]);
myinit()在35至52行,主要作用是用0填充所得内存。
然后再调用_mm_clflush(),将所有修改全局化、并标记对应Cache
Line无效。
_mm_clflush()是gcc编译器针对特定CPU提供的函数,目前用于x64微架构(也就是Intel、AMD)。它是以下指令的封装:
clflush (内存地址)
clflush的主要作用,是把L1/L2/L3
Cache中的Cache
Line,标记为Invalidate(无效)。同时,如果此Cache
Line如果是脏Line(就是之前修改过),会把此脏Line写入内存(内存对于CPU就是全局的,虽然访问延时不一致),这就是全局化。
myinit()结束,初始化也就结束了。
所以,在紧接着的196行:
setcpu(control_number[0]); // control_number[0] : 运行CPU
又调用setcpu()调整CPU,这次设置CPU,就是测试程序真正跑的CPU了。
这里的control_number[0],来自于命令行第二个参数:设置运行CPU。
接下来,从198行到208行的for循环。这里用循环其实没意义了,因为写死了,只循环1次。
这里for循环的本意,是测试多个进程时Cache&Memory的底层原理,当时是针对MESI的。对于NUMA,暂时不用多个进程,所以循环只会运行1次。
之所以把循环还保留在这里,说不定后面其他测试,会有多进程呢。
这里主要做的工作,就是200行的fork:
pid[t] = fork();
返回的pid放在数组中,也是为了循环多次、多个进程。现在只会fork一次、1个子进程。
然后,201行到205行,是子进程。
子进程调用work,开始工作。工作就是测试。
下面,进入work()。
work()中主要工作是72行到137行的for循环。
但限于本篇的篇幅,work()的主要工作,我还是想放到下一篇中讲。
毕竟太长的技术文章,又太硬核,啃起来太费力。
下一篇不会等太久,第四弹之所以等这么久,因为我在全力开发PG Shared Pool。
我是2023 DTCC上,公布要做PG Shared Pool这么件事的:

图8
很多著名的软件,都源自高校,典型的如PostgreSQL,追根溯源,源自Stonebraker 石破天老爷子在加州大学伯克利分校的 Ingres 项目。
正好这两年在北大讲课,台下都是全国选拔出的尖子,为什么不带着有兴趣的同学,也做点东西呢?
然后,PG Shared Pool项目就启动了。
但因为大家都是兼职做,学生的学习任务也很重,所以进展并没有那么快。一年后,终于可以简单看看效果了:
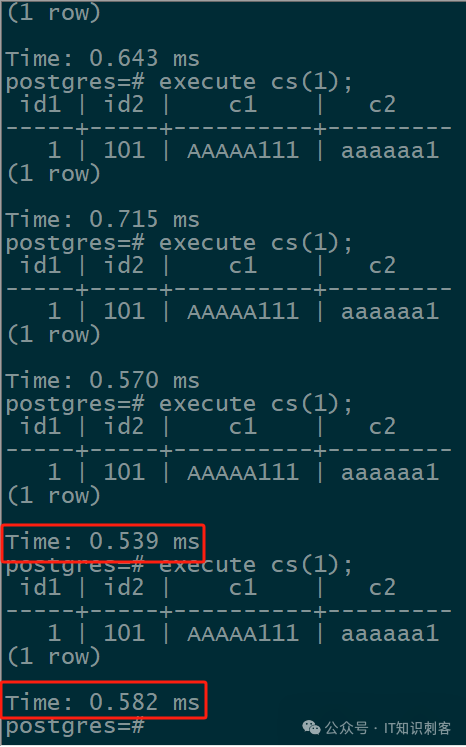
图9
图9 PG 自身的Prepare,使用Cache Plan的时间,一条简单SQL,最快0.539ms。
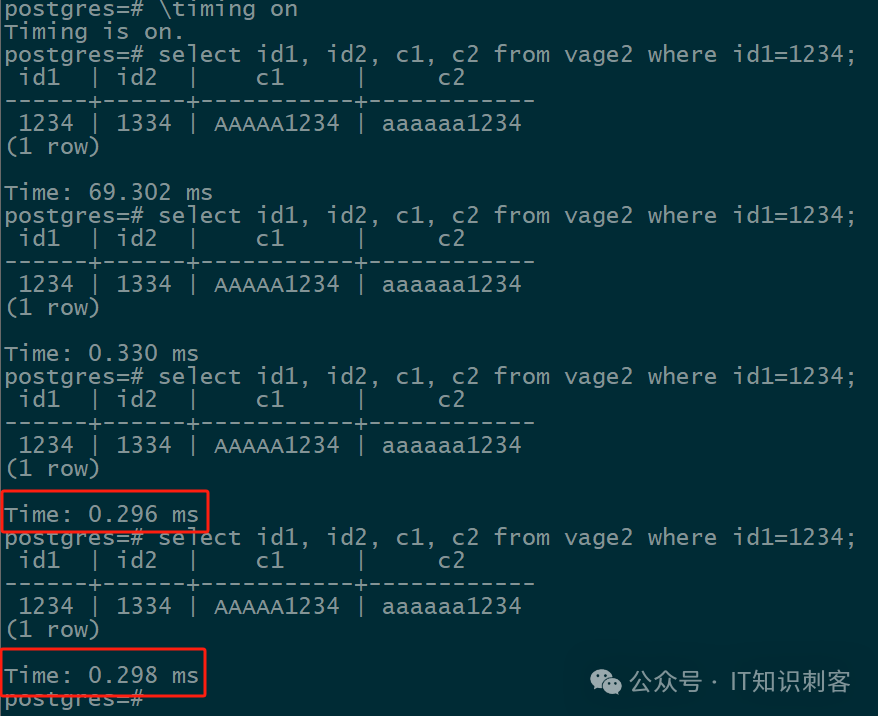
图10
图10是Plan和相关数据都在我们的Shared Pool中后,相同SQL的耗时,只需要0.296ms。
比 Prepare 后的SQL,快了差不多1倍。
当然,这个特性主要针对OLTP型的简单SQL啊,OLAP就没这么明显的提升了。
这里全当一个广告,PG Shared Pool正式面世的时间快了。当然,NUMA的逆行人生系列第5弹,更快。
