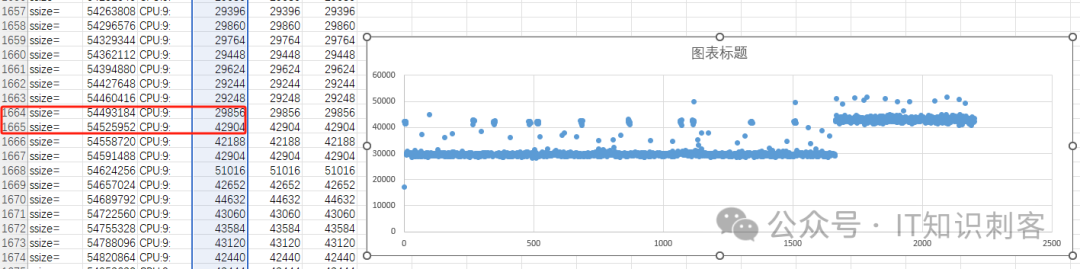
你按我的程序,stepy by step,一步一步的测试下来,大概率会发现结果生成的散点图难以琢磨,和现实CPU原理无法对应。测试程序要求,78行到103行,两个rdtscp()间的所有访存,都是针对Memory的,不能Cache命中。
如果有很多的访存命中Cache,一定会影响访存结果。
测试程序最核心的、72行到137行的大循环,我都是跑2200次,每次200次内存Load,整个测试程序跑下来,读内存次数绝对不会少于2200*200,44万次。
当然,程序还有一些系统调用,也会产生一些内存读请求。为了减少这些系统调用产生的影响,我把72行~137行大循环中的fprintf去掉。就是不再输出结果了。
perf 中,有一个硬件性能计数器,LLC-load-misses,可以观察L3 Cache的Miss次数,L3 Miss了,才会发起内存读吗。所以这个LLC-load-misses,我们就全当“内存读”次数了。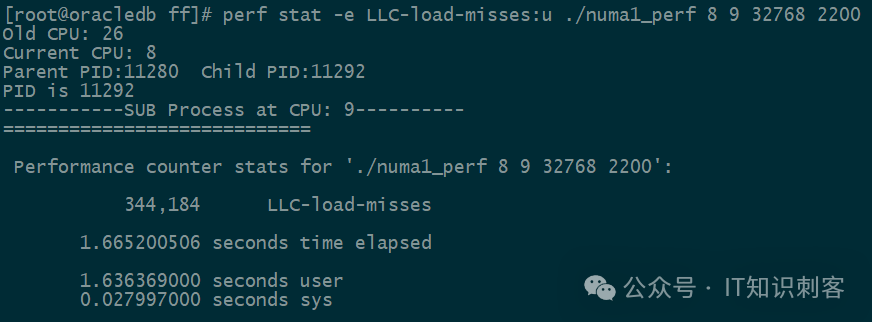
L3 Miss 34.4万次,不到44万次。说明有不少L1/L2/L3的Hit,这对测试结果当然有影响。
这就是你按我的程序,stepy by step下来,也得不到和我相同结果的原因。
我设计的测试程序,已经极力避免Cache Hit了,为什么还有命中?
我又检查了程序,排除程序影响后,那就只能是CPU的硬件预取机制了。
CPU的访存模块,会记录程序访存地址的规律,在程序需要某内存时,提前将数据从内存读入Cache,这就是硬件预取。
我们现在要做的是,关掉这个硬件预取。这样才能实际的测试出内存的性能、NUMA的影响。CPU中有些特殊的寄存器,改变这些寄存器的值,可以更改CPU的默认行为。可以把这些特殊的寄存器,理解为PG的配置参数。你修改参数值,可以设定Shared Buffer大小了、端口号了等等。
以Intel CPU为例 ,这些特殊的寄存器叫MSR,全称:MODEL-SPECIFIC REGISTERS。这些MSR寄存器,没有名字,用编号访问,这个编号也可以叫地址。但要注意,它和内存地址完全是两码事,其实就相当于一个编号。Intel的说明书,也就是白皮书、或CPU手册。看这一本:

在一章中,概述了大部分MSR寄存器的作用(据说有些未公开的MSR,隐藏了Intel的秘密)。
在这里你能找到一个编号420号的寄存器,十六进制:0x1A4。它的作用就是控制CPU的预取行为。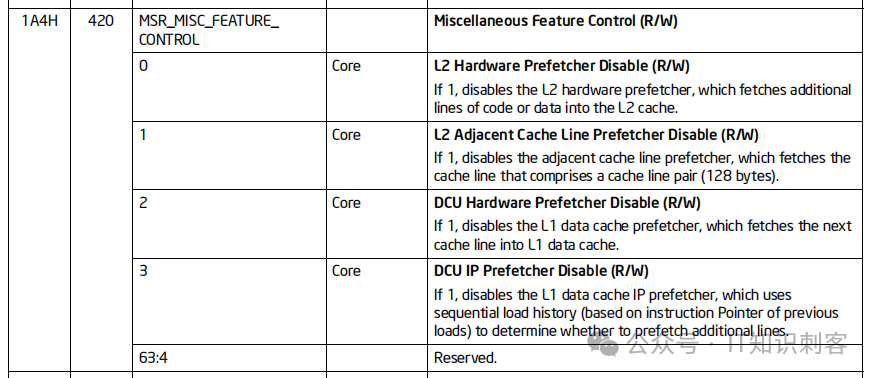
这个420号寄存器,共64位,只有前4个二进制位有意义,分别控制一种类型的硬件预取,0是打开、1是关半。如果把这个420号寄存器每一位都设为1,就是关闭所有各类的硬件预取。
有些CPU并不是用420号控制预取,要注意看手册中的型号。但最近几代CPU,都是用420控制预取。好了,资料找到了,现在的问题是,如何修改这个神密的420号(0x1A4)寄存器?很简单,Linux很贴心的,把所有MSR寄存器映射为了一个文件。
所有MSR寄存器,应该是寄存器堆那样的,物理的在一起的。这对于学习过FPGA的同学,十分容易理解。
(提个小问题,如果是超线程的逻辑CPU呢,毕竟是在一块物理CPU内,MSR寄存器,会不会有两套?)
对这个文件进行读、写,并不是真的读写一个文件系统中的文件,Linux会转变为对对应MSR寄存器的读写。这就是UNIX一切皆文件的精神,所有东西都映射为文件。(但这里的MSR文件和文件系统中的文件完全不同)要读写420号MSR寄存器,读写这个/dev/cpu/9/msr文件的偏移420字节就行。(MSR文件没有以字节为单位的偏移,对420字节读写,会转变为对编号420的MSR寄存的读写)https://github.com/intel/msr-tools
它的主要程序就两个,rdmsr.c和wrmsr.c。功能实现也很简单,以rdmsr.c为例,如图12:


图12
218行open打开MSR文件,235行pread()读偏移是 reg 的MSR寄存器。如果要读420号MSR寄存器,reg的值就是420(0x1a4)。
wrmsr.c也一样简单,想看的话,自己浏览下吧。
我都是在8号CPU上初始化,9号CPU运行测试,下面,我修改下9号CPU的420号MSR寄存器,关闭它的预取功能:
[root@oracledb msr-tools-1.2]# ./rdmsr -p 9 0x1a4
0
[root@oracledb msr-tools-1.2]# ./wrmsr -p 9 0x1a4 0xf
[root@oracledb msr-tools-1.2]# ./rdmsr -p 9 0x1a4
f
420号MSR寄存器的值,已经被修改为f,CPU所有类型的硬件预取行为,都被关闭。
到这里,我灵激一动,忽然想到,我这是一颗有超线程的CPU,9号CPU和25号CPU,同属一块物理CPU。我已经修改9号CPU的420号 MSR 寄存器,25号CPU受不受影响呢?
[root@oracledb msr-tools-1.2]# ./rdmsr -p 25 0x1a4
f
答案是,25号CPU受影响。这证明至少我这个型号的CPU,超线程的两个逻辑CPU,共享相同的MSR寄存器。
好,9号CPU的硬件预取已经关闭,使用LLC-load-misses再看一下内存读次数:
[root@oracledb ff]# perf stat -e LLC-load-misses:u ./numa1_perf 8 9 32768 2200
Old CPU: 26
Current CPU: 8
Parent PID:11124 Child PID:11133
PID is 11133
-----------SUB Process at CPU: 9----------
============================
Performance counter stats for './numa1_perf 8 9 32768 2200':
440,692 LLC-load-misses
1.660670746 seconds time elapsed
1.633101000 seconds user
0.027188000 seconds sys
44万次多一点,符合预期。
再进行测试,生成散点图,你就能一窥CPU的秘密了。
我又“交织”模式测试了下,结果如下:
图13
[root@oracledb ff]# numactl --interleave=all ./numa1_1 8 9 32768 2200
Old CPU: 17
Current CPU: 8
…………
可以看到以2MB为单位波动。这说明在大页模式下,交织模式是页为单位交织。
但普通页的交织粒度更细,并不是4KB。
更多的测试分析,这里不展开了。这一路走来,这个系列已经有6篇了。将近两万多字,只是讲了最基础的NUMA。这涉及到的基础知识有多少,相信大家能感受到。
(对于体系结构、操作系统领域的人来说,这些知识都还好说,并不算特别深入)
至少在未来很长一段时间,NUMA将是大势所趋,无法改变。关键这种“不对等”性思想,已经是芯片领域的趋势了,连同一物理CPU中的L3都有不对等的。这是物理工艺限制所至,有了”不对等性“,去掉了”对等“的束服,规模才能上去。单颗CPU中才能做到接近200个Core。而真正用好这种“不对等”性,只能“近存计算”,即把计算放离数据最近的Core中去计算。就是尽量减少把数据搬来搬去,如现在的NUMA架构,从Remote的Mem中,读到自己的Cache中,再进行计算。这就是搬运数据,这会成为能效瓶颈。
数据离谁近,就在谁(CPU)中计算,就是“近存计算”。
特别是在CXL.memory已经可以把另外一台主机中内存的访问延迟,拉低到比Remote NUMA高一倍左右,这使得分布式内存池,或许快要变为现实。现在所谓的分布式内存池还都是吹牛B,并不是真正的分布式内存池。)基于CXL.memory的远端内存,相当于“更远的远端NUMA节点”。但是在现有模式下,NUMA的Remote延迟,已经有不小的影响了,再来个更Remote的Remote,影响更大,使得分布式内存池只是看上去很美,实际应用场景极为有限。或许“近存计算”,不把数据搬来搬去,把计算“调度”到相应的CPU中计算,才是更现实的解决方案。对于各种不对等性(如NUMA),现在的解决方案,在OS中增加一层,忽视不对等,让操作系统以上的程序,感受不到不对等的存在。这样更方便。但延迟是真实存在的,无法消除。如果要做到“近存计算”,必然要将进/线程调度来、调度去,以现在OS调度器架构,代价太大,“近存计算”收益很多时候还不如调度器自身开销大。那么只能把DB写到操作系统内核中,让DB成为OS的一部分,面向DB重新开发调度器(以及相关的内存管理模块),这样的DB,应该部分的相当于OS了,这样的构想如果实现,这个”面向不对等“性设计的数据库,要叫什么名字呢,DBOS?我不知道 Stonebraker 提出DBOS是不是包含了这样的内容。因为公开的资料太少,而面向“不对等性”,又是一个比较“小”的话题,如果只想解决不对等性问题,在Linux中写一个模块驱动,就能实现。以Stonebraker的量级,必然要着眼于更大范围、更高层次,比如Clound。假设一名知识体系全面、行动力超强的资深IT人,眼看着处理器已经悄悄发展到了“分布式”,这个时候要重新设计操作系统,还一切按照老一套,只把调度、内存管理用数据库的语言再写一遍,把操作系统中的红黑树、HASH表等,换成数据库的BTree、HASH,好像区别不大啊,这是图个啥,像纯血鸿蒙一样,要搞个美帝“国产化”万物互联纯血云OS吗!为什么不用我们菊厂的鸿蒙Next。而且,相关DBOS的资料少,说不定只是因为Stonebraker是搞数据库的,又不是搞科普。我用了近两万字,只为了让你感受到NUMA的不同,而更宏大的“不对等”性,只是在最后一篇中提了一下。真要讲明白整个事,写一本书,恐怕还有点不太够。
但这些对于Stonebraker都是常识,或许他只是觉得不用提而已,提了多数人也听不懂,还不如偏向于Cloud这样的方向宣传。虽然Intel最近比较拉,但仍有研究的必要。本篇涉及少量Intel手册,如果需要Intel相关手册的,留言:“手册”,我把相关手册发送给你。