程序,枯燥而无味。但要追寻牛马的意义,必需与无味处品出滋味,这就是真相的代价。上一篇说到了测试程序的核心,是54行开始的work()函数。这一篇从这个函数继续。
work()的核心,又是72行到137行的for循环。循环次数loop_number_1,来自于命令行第4个参数。
for循环中有两段嵌入汇编,两段几乎一模一样,第一段是重点啊,先说第一段。
在第一段嵌入汇编开始前、后,78行和103行,分别调用了rdtscp(),得到TSC:
这是78行的,103行和这里差不多,只是TSC的结果赋给了end变量。
rdtscp()也是自定义函数,在22到31行,主要调用rdtscp指令,得到当前的时钟周期。
TSC是CPU中消耗最小的计时器了,得到TSC有两条指令rdtsc和rdtscp(多了个P)
rdtsc指令还会有一些问题,但rdtscp(多了个p)指令修正了rdtsc的问题,而且Linux内核会定时在所有核同步TSC。
统计较短的时间,使用TSC是最佳方式。许多国外研究体系结构的大佬,都是使用TSC分析CPU的内部行为。
注:
相较rdtsc,rdtscp增加了lfence,阻止乱序指令越过计数器先执行。关于lfence和更多fence指令意义,可以阅读此专栏:基础软件开发
下面,重点看第一段嵌入汇编吧。
这段汇编的目的,上一篇中已经有讲述:
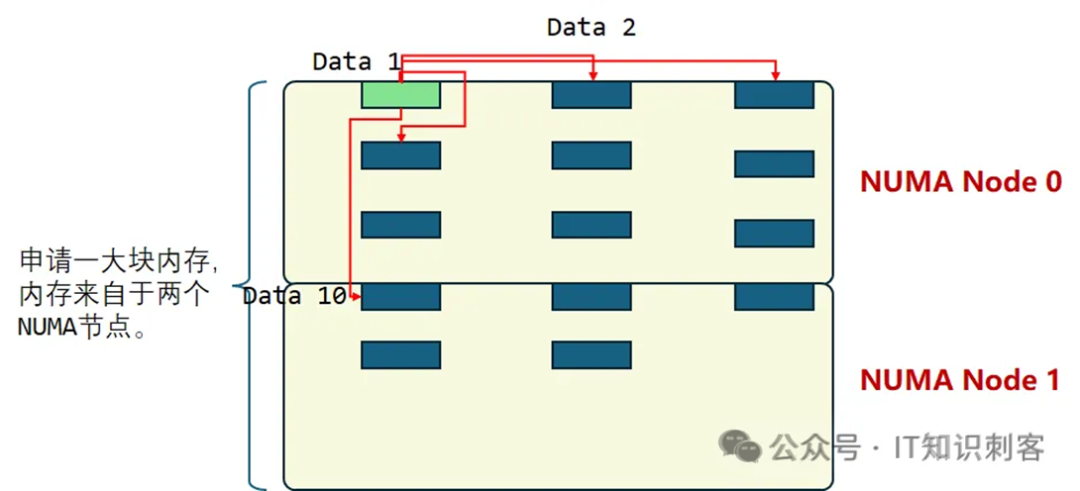
两个相依赖的地址,如图1中Data1和Data2,称为一个地址对,记为(Data1,Data2)。地址对中Data1不变,Data2以命令行第三个参数step_size为步长,不断增加。因此,我们的地址对应该是(Data1,DataN),Data1不变,第二个地址不断增大。地址对中的地址,越来越远。如图1中的例子,当第二个地址是Data10时,Data1和Data10已经在不同NUMA节点,它的访问延时,将明显高于前面的地址对。如果是在NUMA 0的CPU中运行程序(嵌入汇编运行在NUMA 0的CPU上),Data 1不跨NUMA节点,Data 10跨NUMA节点,总的完成时间,比(Data1,Data2~9)要长。另外,每一对地址对间,也都有依赖,阻止指令级并行,影响我们对延迟的观察。关于程序的简述,上一篇中有更详细的描述。这里来看一下具体的实现吧。"m"( *mem ):mem,在嵌入汇编中,它是%0,是内存块的起始地址。
"r"(ssize):ssize,它是%1,它的值来自于74行:ssize = i * step_size。step_size是命令行第三个参数。
"i"(100):它是个常数,100。用于循环次数。它是%2。
"r"(loop_number_2):它的值固定为2,在汇编中用%3代表它。它用于设定用于测试的是“地址对“,即只有两个地址。本来我是有多个地址可以参于测试的,后面缩减到只有两个地址(变成了地址对)。
"mov %2, %%r13\n\t" // 增加一个循环,两层循环。定为100
"lea %0, %%r8\n\t" // 内存块开始地址
注释中写的很清楚,我不再重述了。以这两行为例,说一下汇编的风格。两种,Intel风格和AT&T风格。gcc默认的是AT&T,就是“源操作数“在前,”目标操作数“在后。比如81行的"mov %2, %%r13\n\t",%2是源操作数,r13寄存器是目标。%2对应100,这里就是将100送入R13寄存器。至于这段嵌入汇编,我写成如下的C格式程序吧,把r8、rax等寄存器,当作变量:r13 = 100;
r8 = &mem[0]; r8 是用于存放地址的变量(指针),后面的访存,都是Load R8地址中的数据
do
{
rax = 256;
rax = rax * r13; 256 * (100,99,98,……,0)
r8 = rax + r8;
r12 = 2;
do
{
r14 = *r8; 访问内存,访问地址对中Data1。读到的内存值,都是0
// 初始化时,内存块被初始化为全是0
r14 = r14 + ssize; // 计算地址对中第二个地址,也就是DataN的地址。
r8 = r8 + r14; // R8为DataN地址
r12--;
} while ( r12 != 0 );
// 上面的循环只会循环两次,对应地址对中只有两个数
r8 = r8 – r14;
r8 = r8 – r14;
r8 = r8 – rax; // 以上三行,将r8的值,恢复为Data 1地址。
// 同时迷惑CPU,在地址对间产生依赖。
r13--;
} while ( r13 != 0); // 循环100次
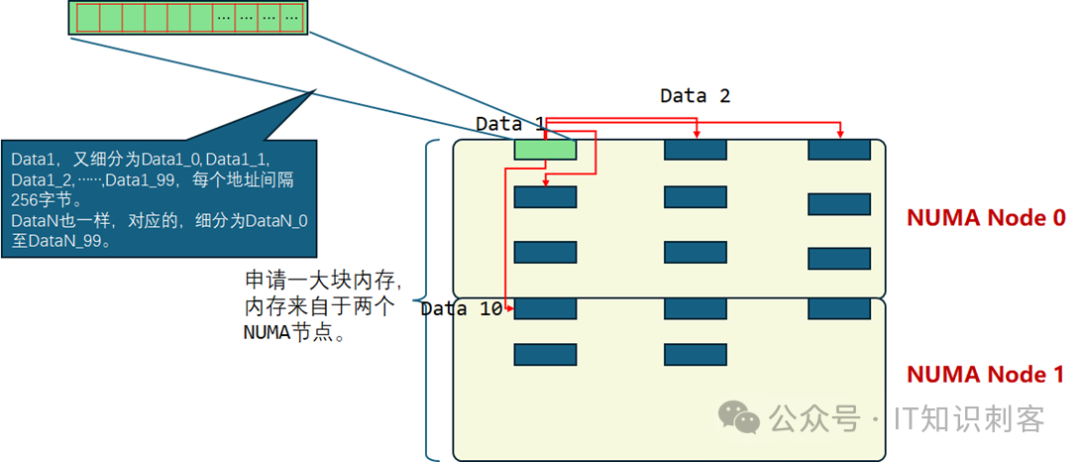
之所以使用嵌入汇编,而不用C直接写,目的是为了方便控制进入CPU的指令流。NUMA毕竟是CPU的特性,我希望可以直接面对CPU,而不是中间又隔了层gcc等编译器。因此在两个rdtscp()间的指令,我使用汇编,研究CPU只能这样。这段嵌入汇编程序主要作用就是读地址对中Data1,计算出DataN地址,再读DataN。如果只读一次,难免因为各种异外,导致波动。因此循环100次,读(Data1,DataN)一百次。但如果100次循环,(Data1,DataN)地址保持不变,除了第一次读,后面将命中L1 Cache。因此,每次循环,Data1和DataN的地址,都偏移256字节。之所以偏移256字节,是因为L2预取的大小是256字节。我不希望L2预取导致Cache命中,从而影响观测结果。(这里实际以64字节间隔也没问题,后文会说明原因)也就是说,如图2所示,地址对还是那个地址对,我的测试中,多以32KB间隔。(Data1_0, DataN_0)
(Data1_1, DataN_2)
(Data1_3, DataN_3)
……
(Data1_99, DataN_99)
然后,100次循环结束,使用rdtscp()统计周期数。104行,计算100次循环的总TSC(时钟周期)数。在输出结果后,112行到137行,又是一段几乎相同的嵌入汇编,唯一不同的是123行:"clflush (%%r8)\n\t" // 刷新L1~L3 Cache
这里使用clflush指令,把前一段汇编访问过的所有内存,刷出L1~L3 Cache。这样,再开始下一地址对时,保证不会命中Cache。这段汇编主要针对(Data1,DataN)中的Data1,因为DataN是变化的,不clflush,也不存在Cache命中问题。但Data1是固定的,而且又细分为Data1_0到Data1_99共100个,不clflush一定会命中Cache。[root@oracledb ~]# cat /sys/devices/system/node/node0/hugepages/hugepages-2048kB/free_hugepages
39
[root@oracledb ~]# cat /sys/devices/system/node/node1/hugepages/hugepages-2048kB/free_hugepages
26
现在NUMA 0中有39个大页,共78MB。NUMA 1中有26大页,共52MB。[root@oracledb ff]# ./numa1_1 8 9 32768 2200
32768:以32KB为步长。每个大的地址对间隔32KB。(细分的小地址对,间隔256字节,不可调节)
另外,程序将分配100MB大页内存,这个也不可调。如果要改变大小,或使用普通页,只能修改程序再编译。
因为初始化CPU是8号CPU,属NUMA 1节点。NUMA 1节点只有26个大页(52MB)内存,程序所请求的内存,前52MB来自于NUMA 1,剩余48MB必然来自于NUMA 0,如图3所画: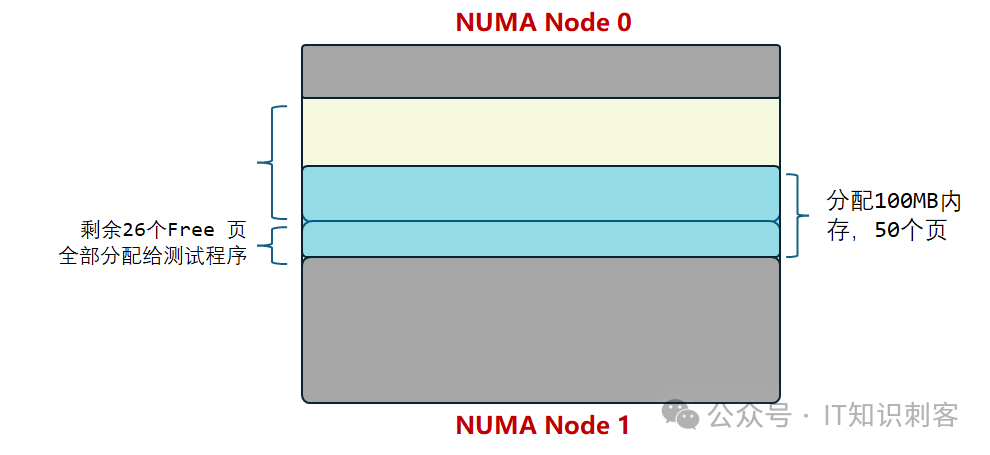
(gdb) p 52*1024*1024/32768.
$4 = 1664
我把gdb当计算器了。52MB,除以 32KB(大地址对间隔是32KB),在1664个地址对后,1665地址对时,延时将大大增加,因为Data1,和DataN,已经跨了NUMA节点。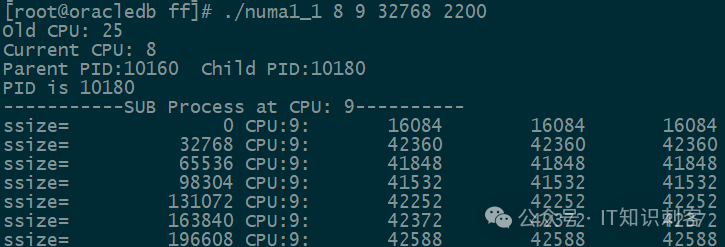
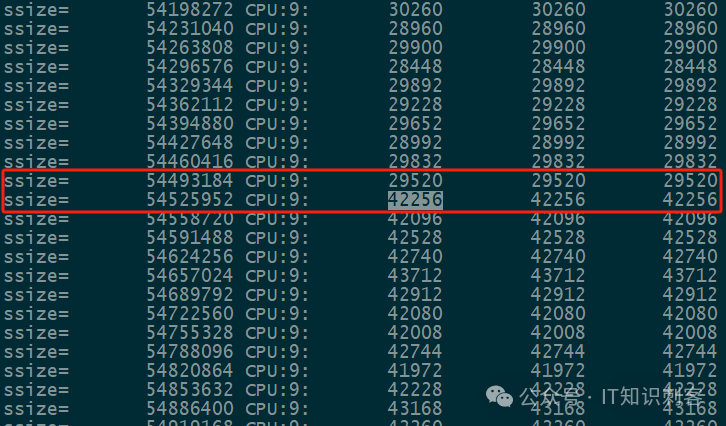
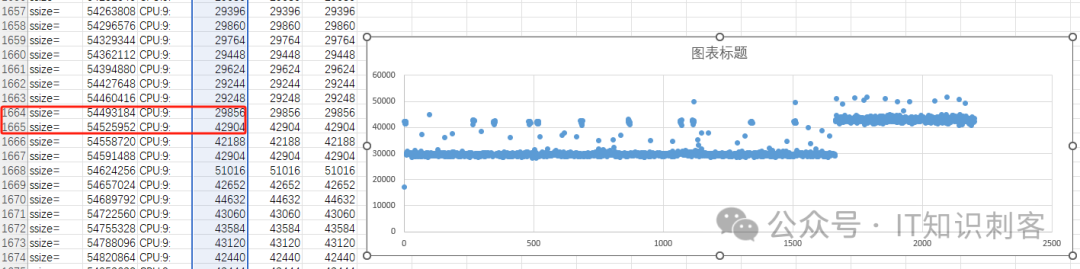
图5中可以清楚的看到拐点,拐点在1664、1665个地址对这里。藏在CPU最底层的秘密,清晰、直观的呈现在你的眼前。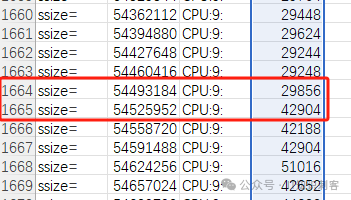
再来张高清图,看的更清楚些。1664、1665,在测试之前,我们就已经算定了,拐点在这里。访问这里之后的内存,延迟几乎成倍的增加。其实对于了解体系结构的人来说,一个子函数、一段循环需要多少个周期、多少纳秒,不需要测量,好好估算一下,都能估算个八九不离十。如果实际测量出的时间,大大的高于估算时间,这说明指令流并没有按预想的方式被CPU执行,这就存在优化的可能。更高级的情况下,甚至可以在实现一个功能、或一个算法前,大概的知道它要消耗多少CPU。这对基础软件的设计、架构非常重要。达不到这一步,可能整个软件开发完了,才知道这个算法、模型只适用于OLAP,OLTP下会消耗过高(熟悉我文章的人,都知道我在映射那些数据库,就是指令数消耗过高、一直占用CPU的……)。但如果你按我的程序,stepy by step,一步一步的测试下来,发现结果并非如预想那样,生成的散点图难以琢磨,和CPU原理无法对应,这又是什么情况呢?明天,第6弹,牛马大结局,还有这个系列开头提到的DBOS,又是怎么和牛马扯在一起的,第6弹即将水落石出。