




【每天5分钟,了解一个知识点】
今天我们来聊聊 MySQL 中的一个有趣的特性——Skip Index Scan(跳跃式索引扫描)。
一、Skip Index Scan 的
基本原理
先来看一个例子,假设有个表 t1,它有一个索引是(c1, c2)。但如果我们的查询条件中只包含 c2,比如“select c1, c2 from t1 where c2 > 10”,正常情况下,我们是没法直接用这个索引的,即使勉强用了,也得对索引做全表扫描,然后在扫描到的行上做条件判断。
不过呢,这里其实有优化的空间哦。MySQL 引入了 Skip Index Scan,这个方法是由 Facebook 贡献给 MySQL 的,从 8.0.13 版本开始支持。它的原理很简单:通过跳过索引的前缀部分,对后续的索引部分进行小范围的范围扫描。
举个例子,有一张表建立了联合索引为 index(sex,age)。
| id | sex | age |
|---|---|---|
| xx1 | F | 22 |
| xx2 | M | 21 |
| xx3 | M | 23 |
| xx4 | M | 31 |
当查询 sql 为“SELECT * FROM X WHERE age > 30”时,通过 Skip Index Scan 也能走联合索引进行查找。为啥呢?因为对于联合索引来说,想查 age 大于 30 的值,不就相当于 sex 等于 F 或者 M 的时候 age 大于 30 的行吗?MySQL 会对查询进行优化,先通过联合索引的最左列 sex 的值配合 B+树在不同的 sex 值之间跳跃。就好比,先找到 sex 为 F 的范围所在,再找 age>30 的数据,找完后直接跳到 sex 为 M 的范围找 age>30 的行。所以最后就优化成了“SELECT * FROM X WHERE (sex = ‘F’ and age > 30) or (sex = ‘M’ and age > 30)”。简单来说,跳跃式索引扫描就是在没有满足最左原则匹配的情况下,通过为最左列的值进行跳跃式匹配,来达到原本的效果,避免以前那种没有最左匹配就走全表索引的情况。
二、Skip Index Scan 的常见应用场景
再看另一个例子,表 t5 有索引 c1, c2,并且 distinct(c1)的值很小。如果查询语句是“select c1, c2 from t5 where c2 > 30”,就像下图所示:
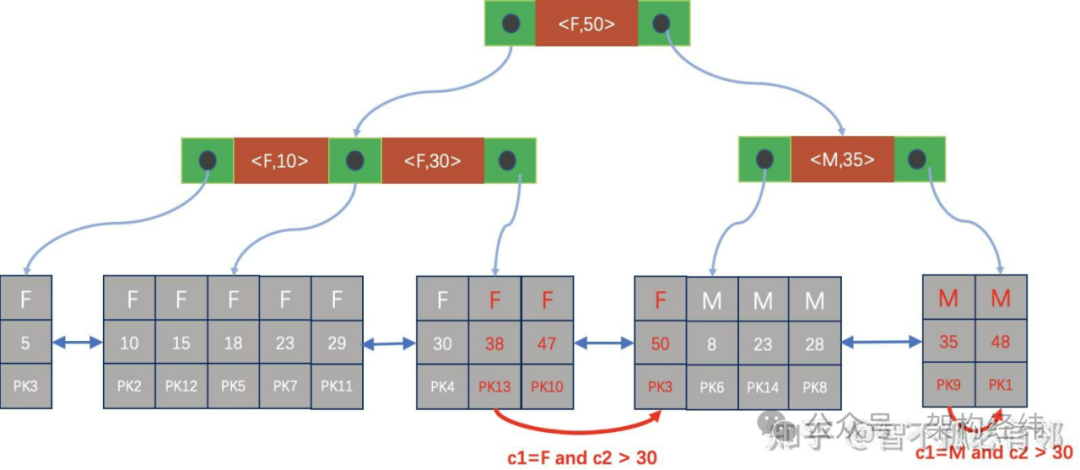
(这里可以想象一个图,展示 c1 只有两个值 F/M 的情况)
对于 c1 只有两个值 F/M 的情况,就可以将条件扩展为“(c1=‘F’ and c2 > 30) OR (c1=‘M’ and c2 > 30)”。
三、Skip Index Scan 的限制
虽然 Skip Index Scan 很有用,但也有一些使用限制哦。
首先,select 中选择的字段不能包含非索引字段。
其次,SQL 语句不能包含 group by 或 distinct 语法。
最后,Skip Index Scan 只支持单表查询,不能用于多表联接。
【关联阅读】
关注公众号,回复【Java面试】,获取更多面试资料
