






分享嘉宾:毕玉龙 京东科技 画像团队技术负责人
编辑整理:翟佳鹤 京东
出品平台:DataFunTalk
导读:京东科技画像平台通过对用户分群,针对不同的用户投放以不同形式的不同内容,实现千人千面的精准投放,并进行投后监控,最终实现用户的增长。该平台提供一个底层的通用服务,服务于不同的业务,以支持精准营销、精细化运营,智能外呼等营销场景。该平台最核心部分便是通过ClickHouse的BitMap存储标签明细来进行实时的人群计算。
本次分享主要围绕引入案例、场景下用户画像和高效ClickHouse这三个方面进行展开。
1. 案例:大数据时代的精准营销

作为一个运营人员是要考虑在什么时间做活动?这活动受众有哪些,人分布在哪里,然后他们有什么共同的特性?应该用什么样的形式推送什么样的内容去引起受众的注意,才能获得高的转化率,实现精细化运营?
如果没有画像平台,还需要去线下提取数据,然后对数据进行分析,这对运营人员的门槛要求高且效率低。而画像平台可以在线圈选目标客群,然后进行画像分析,整个过程是可视化地完成精准营销。
精准营销底层支持的是分析用户标签的能力,包括每一个用户细节洞察、用户标签定义、用户标签打标,这些都是业务提升GMV的关键。
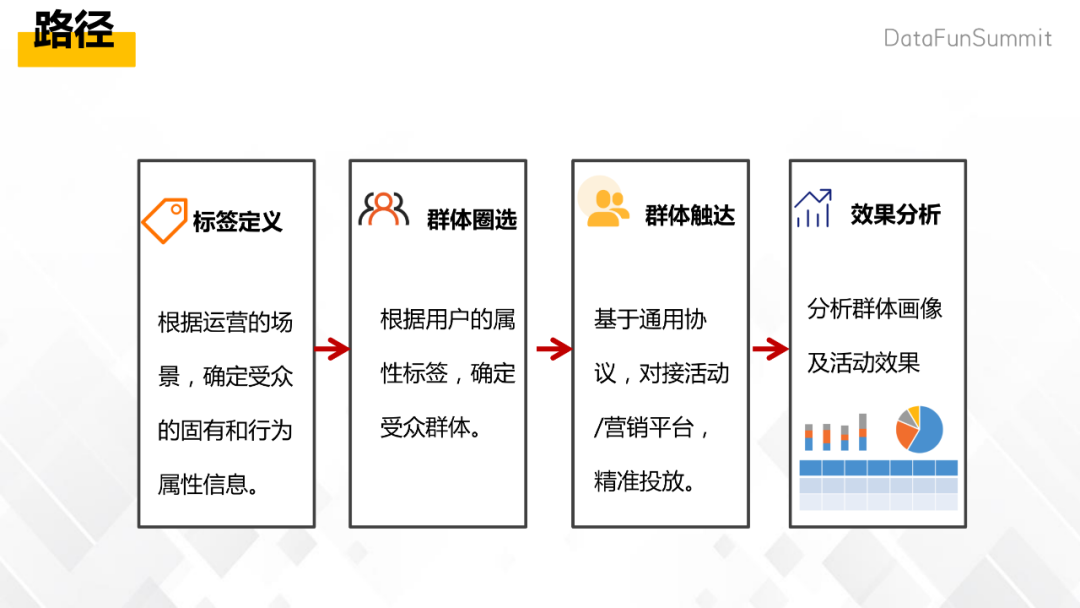
有这样一个优惠促销活动,需要找出20岁到30岁之间,并且近期浏览过某某商品的用户,然后给这部分人发优惠券,再通过短信或者微信等渠道触达到用户。
那么如何实现这样的需求呢?
标签定义,把一些固有属性(比如说年龄和行为属性,比如说浏览的某些商品),抽象概括成标签,通过标签就群体的宣传。
选择标签之间的交并差逻辑组合(年龄在20~30岁,并且浏览过某个具体商品)。
圈出群体。
通过统一的接口协议对接营销平台进行精准投放。
通过效果分析工具分析活动效果。
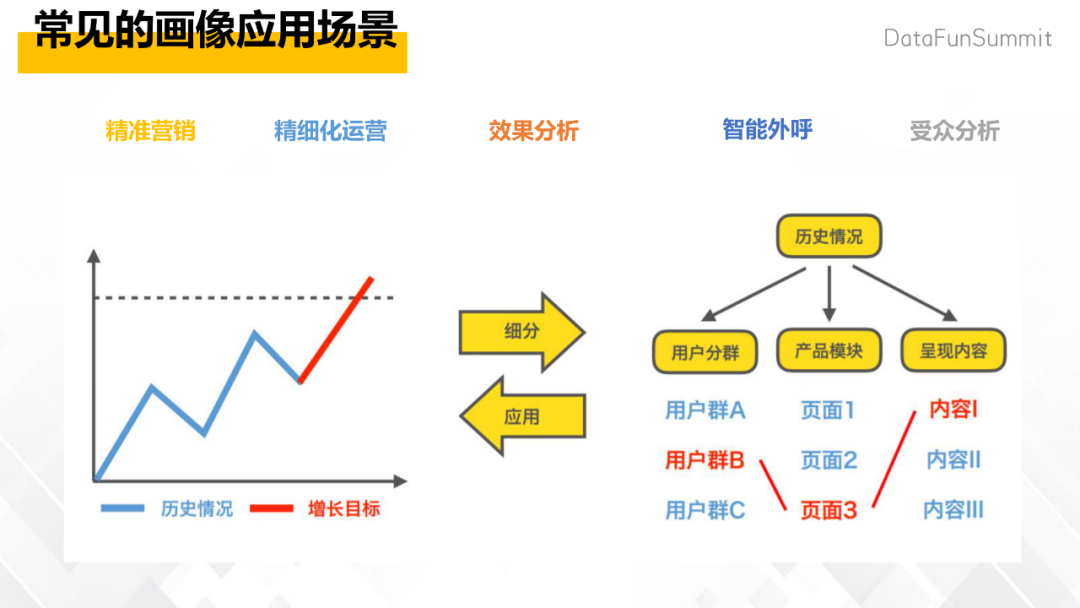
精细化运营的典型场景是确定用户分群;投放不同的用户,可以在不同的模块看到不同的内容,实现这种千人千面,做到精准的投放;投放后还可以看这个效果,最后关注用户在该产品的使用路径,每一步的转化情况,以此去提升产品的应用性,实现用户的增长。本文中的画像平台就是这样一个底层通用的服务,服务于很多平台,支撑包括精准营销、精细化运营,智能外呼的营销场景。

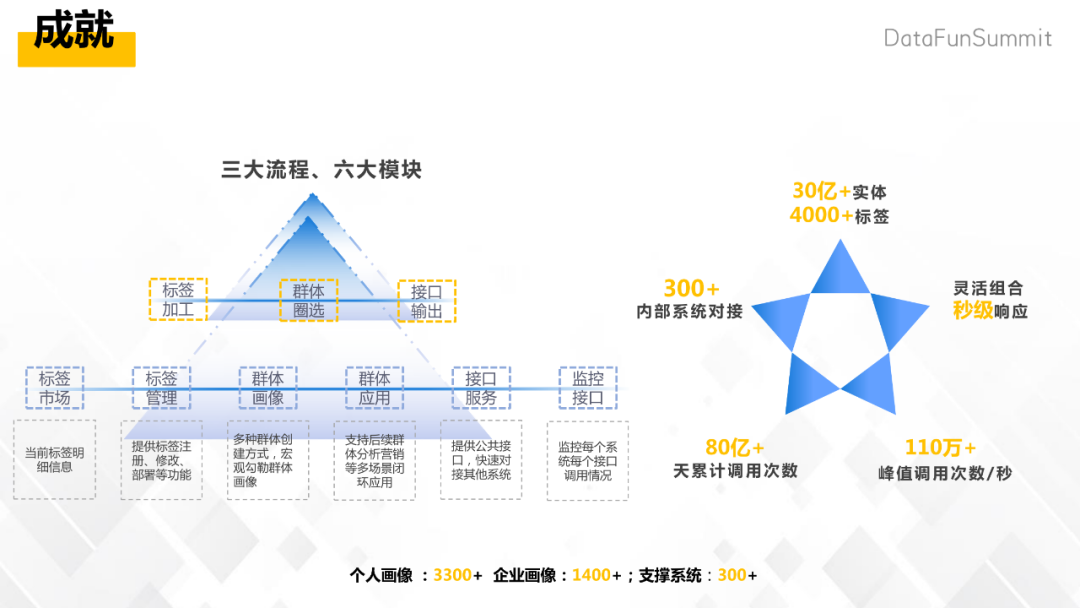
产品的架构分为画像服务层、运营监控层和数据及基础能力。
1. 画像服务层
画像服务层从左到右为面向用户使用平台的4个步骤。如果没有想要使用标签,首先需要注册标签(分为离线和实时两种不同的接入方式标签),准备好后就可以在系统中以可视化操作的方式选择标签交并差组合创建群体并查看群体画像的画像分析,然后选择要触达的应用和周期。触达是个复权的过程,对群体一个生命周期的管理,同时可以查看触达的效果分析。那么有了权限之后,就可以在系统层面进行一个对接,提供的这种数据服务,包括群体的命中、群体下载,还有这种标签查询。
2. 运营层
运营层主要是主体管理,主体是什么?是包括用户ID、信用卡ID、企业ID、店铺ID,还有供应商ID的,所以画像平台不只是用户的画像,还包括上述其他主体的画像,同时为保证系统的稳定性,避免因为系统错误影响到业务,我们也是做过了一些监控的预警,比如说数据为0的时候,波动超过上限的时候,不会进行触达并发出报警,群体会及时更新,也会发出报警。
3. 数据及基础能力
数据的基础能力是依托于京东的大数据平台,包括标签的加工,还有这些上述主体ID的管理,还有实时和离线计算的引擎。该功能有的亮点为时效性高,CK极大提升了计算效率,数据做到了及时计算无积压;系统关联性灵活,打通了营销的平台,构建了画像投放效果分析工具,同时人群投放的实时标签和人群重定义,提升整体的投放效果;主体覆盖全面,就是这种跨主体的分析;有完整的生命周期管理,完善完整的标签群体触达任务的生命周期管理。当然用户过期后将不会更新群体数据,节省不必要的资源浪费。而我们当前的话有30亿家的主体,已经有4000家的标签,支撑的系统已经有300多个,接口服务每日累计调用次数达81次,峰值调用可达每秒110万次,标签圈选可以做到秒级响应。
1. CK的优势

CK作为主要的计算和存储的原因如下:
快,因为它本身的设计一个是存储下载引擎,那单查询吞吐量就是单服务器分值可达10亿/秒。
高压缩比,减少机器资源,还集成了高度压缩的BitMap。正常1亿的群体要几个亿的大小,BitMap只有40M。
支持与、或、异或、与非更丰富的为图计算的方法,方便实现标签的交并差处理。
最重要的还是功能开发完全的SQL化,支持JDBC,开发维护的成本非常低。
2. CK的部署
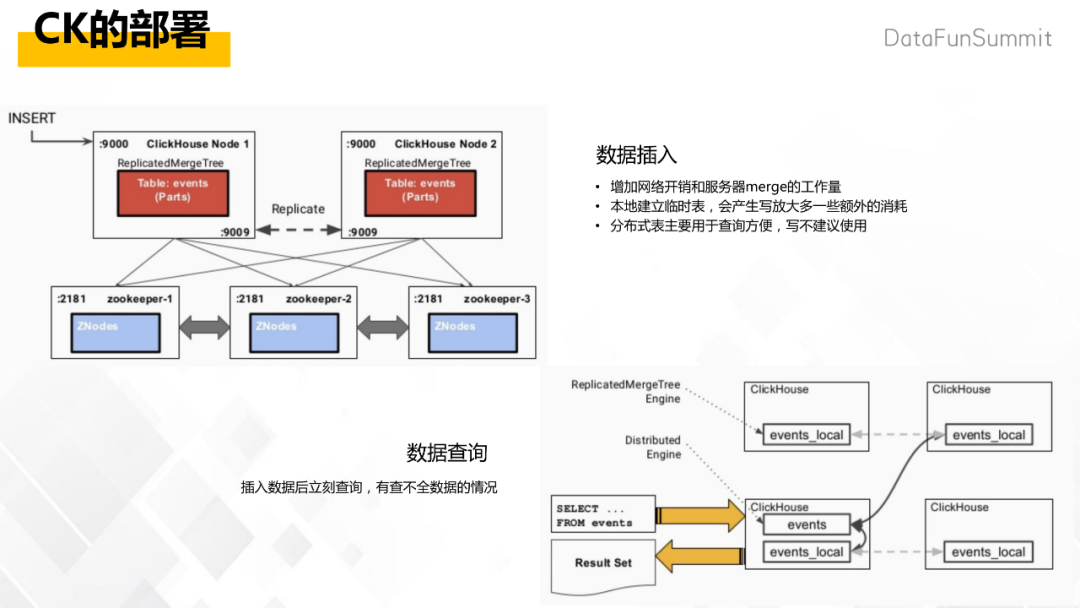
部署方式采用的是分为多个 shard分片的分布式高可用的架构,分布式存储数据。左图为一个分片,每个分片有两台使用了复制表的机器,两两候备,插入数据的时候,使用负载均衡的方式插入其中一台,另一台就会实时的进行同步,以实现提高并发和高可用。CK是可以创建分布式表,但是不建议写分布式表,原因是会增加网络开销、服务器merge开销,并且它会在本地建立这种临时表,会产生写放大。最佳实践是把数据按用户ID去分布,然后自己做了个路由写到不同的分片上,通过并行单机计算,最后把人群合并。
CK不支持事务,插入后立刻查询会出现是数据不全的情况。该平台的解决方案是在标签上云的过程之间,进行数据校验,以保证数据的准确性。
3. 整体架构

分析师在统一画像平台注册,管理标签用户在画像平台全权投放;运营系统最终通过这个数据服务与画像平台去进行对接命中接口,看人在不在群体里面;群体下载就是下载群体的用户的ID标签取值,用于查询某个用户某标签,比如说查询某个用户的性别标签。
最核心的部分是CK计算服务,标签明细的数据推送到CK会标签位图的计算,所有群体计算都是使用标签位图,位图便是计算快的原因。
用户在平台上去创建和修改,都会触发群体的计算,可以选择不更新、依赖更新和定时更新三种更新机制,并把数据同步到接口侧,其中依赖更新是需要群体选择的标签全部更新后才会触发群体更新,而定时更新是到点儿使用最新的标签数据计算。还有群体的存储服务,因为我们的命中接口调用量并发的非常高,对时效性要求非常高,Tp999不能超过50毫秒。
存储服务采用的是256g内存的物理机,将群体加载到内存。为了防止群体数据过大,也做了这种分片的处理,根据不同的用户ID可以录入到不同的分片上。最上层接口是一批为了抗并发虚拟机,根据压测情况配置了底层服务和上层接口的一个机器比例。整体的流程是群体更新会把群体位图上传到oss上,通知群体服务更新版本号,群体服务会根据版本号从oss上去下载群体,位图解析后放入内存,更新完成后更新版本号。取值接口使用了直接存储在HBase的标签明细数据,需要注意的是写入过程需要注意控制好写入速度,避免对读产生影响。
4. 位图计算

这是一个位图计算的示例。左侧就是标签的明细数据,101用户,年龄23,1102用户年龄是31;下面是101用户近期浏览过3001这个商品,基于明细数据加工成标签位图,年龄23的用户有101和104;那么年龄在20岁到30岁之间有101、103和104,浏览过3001和302上面的有101、102、103、105。那么同时满足两个条件做个交集101和103,即我们要找的人群。这就是一个位图主要的计算逻辑。
5. 数据服务体系

画像整体的数据流主要依托于京东的大数据平台,将实时数据和离线数据推送到CK和HBase(HBase是直接提供了标签取值,CK数据会触发用户圈好的群体计算),用户也可以在画像平台上使用最新的数据,实现秒级的群体圈群预测和查看画像,计算好的群体最终会加载到内存,给用户提供高并发的接口,标签数据可以实现这种标签取值的一个实时的查询。其中,CK采用这种并行的处理机制,任何查询都会用到这种一半的CPU去执行,对高并发的支持并不好,所以我们做了缓存设计,以应对查询画像分析高并发,还有多表join性能也不好,我们也是在持续的探索在做一些优化。
Q:高并发缓冲是用什么做的?
A:根据用户参数进行一级的缓存,如果再重复的去查询,那么直接就返回缓存。用户画像分析的时候会配置固定的模板,不管是什么人群,他看这些固定的模板的一个画像分析,那么对于这些模板的数据可以同样把这些位图放到redis中去存储计算,而不是ClickHouse。
Q:群体位图可以会在ClickHouse做过滤吗?
A:可以。不管标签还是群体,本质都是个位图,可以任何的条件组合,结果集可以重新拿来运算。
Q:群体存储服务放内存加载的过程会不会非常耗时?
A:一个亿大小的位图只有40M,并且数据本身是分片的,对这个数据去进行解析并放到内存这个速度是很快的。50G大小左右的群体数据只需要半个小时以内完成加载,其中还包括了重新初始化、从oss下载等过程。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

活动推荐:
小伙伴们,DataFun年终大会又来啦,在今年的大会上,我们不但会回顾当下的热门技术方向,同时还将对未来的技术趋势进行分享总结。其中,我们也设置了数据开发与数据治理论坛,感兴趣的小伙伴,欢迎识别下图二维码,免费报名参与~

关于我们:
🧐分享、点赞、在看,给个3连击呗!👇
