




前一阵子我在墨天轮替亲戚发了一个外企的DBA岗位,其中要求既要有Oracle DBA背景,最好有一些Snowflake的经验。在国内自身的Oracle DBA不胜枚举,但是Snowflake就少了很多。一方面,Snowflake是纯粹的公有云,而且依托于AWS等国外公有云;另一方面,国内同等生态位的公有云产品,其实有很多可选,内部外部的诸多因素造就了差异。
然而很多人可能不太了解的是,Snowflake的三位联合创始人。虽然Snowflake是一个云原生的数据库,其实在很多特性方面,都还是能看到Oracle的影子,或者说,Oracle和Snowflake的很多东西,是不谋而合的,最近这段时间,我也一直在尝试着去寻找两者的相似之处,也算是发现了几处。
第一处,整体架构
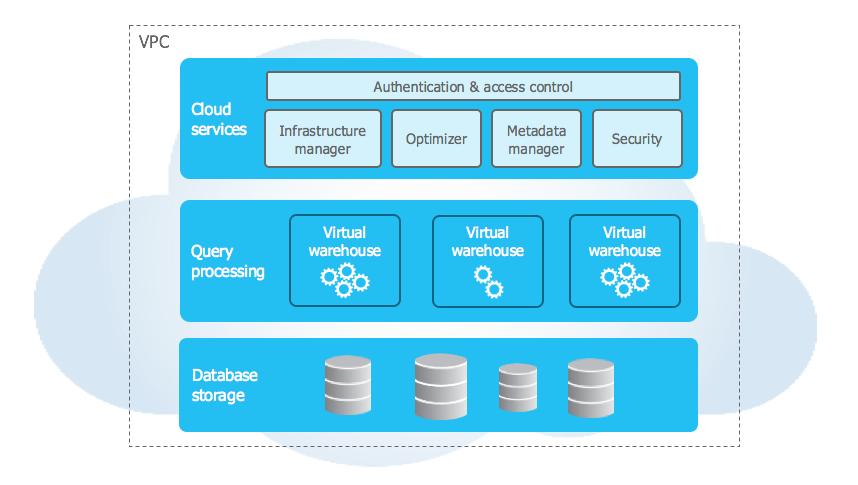
Snowflake官方文档中对于架构有着这样的描述
Snowflake’s architecture is a hybrid of traditional shared-disk and shared-nothing database architectures. Similar to shared-disk architectures, Snowflake uses a central data repository for persisted data that is accessible from all compute nodes in the platform. But similar to shared-nothing architectures, Snowflake processes queries using MPP (massively parallel processing) compute clusters where each node in the cluster stores a portion of the entire data set locally. This approach offers the data management simplicity of a shared-disk architecture, but with the performance and scale-out benefits of a shared-nothing architecture.
字面意思上来看,snowflake集群有一个中央数据存储库来存储持久数据,该存储库可以从平台上的所有计算节点访问。集群中的每个节点都本地存储整个数据集的一部分。而每个节点以MPP的方式提供算力。
这一点来看,Oracle RAC与snowflake存在一些相似之处:
共享存储,Oracle RAC使用ASM与Snowflake的中央数据存储有些类似,提供给每个节点用于计算的数据,同时ASM有自己的冗余度。差异在于,snowflake是原声带列存,而普通的ASM是行存,只有exadata上才有列压缩、混合列存储这些选项。这一点也和两者的使用场景有关,snowflake主打数仓,如果不是Exadata,Oracle更多的用于事务处理。
并行计算,多节点架构的重要优势就是实现并行计算。snowflake的实现方式是虚拟仓库以及分布式交换等特性,通过水平扩缩容来实现算力的调整。而Oracle RAC在这方面是通过并行DML、Cache Fusion等特性实现。但是根据我个人的测试结果,无论哪一边,实际算力与节点数都不能完全做到线性增长,基础服务都会增加一定程度的资源开销。
第二处,对象类型
Oracle和Snowflake都提供了丰富的数据类型来满足各种数据处理的需求,当然,在实际生产系统中,相当比例的Oracle数据类型可能没有被用到。但是从常用的数据类型中,还是能看出来一些两者的相似之处。
Number与Numeric。熟悉Oracle的DBA会知道,Oracle中的int家族其实都是number类型中,小数点后面精度为0的同义词,number类型实际上就是定点数类型。无独有偶,在snowflake中,numeric也是同样的同义词,在官方文档中也做了特别说明(Synonymous with NUMBER, except that precision and scale cannot be specified)。而这种处理方式,在MySQL或者PostgreSQL中都不存在,定点型与整型,在存储时,是以完全不同的方式来存储。
字符串类型的命名。Oracle当中,字符串类型是真的多,如果初次接触,多少会有点迷惑,CHAR、VARCHAR2、NCHAR、NVARCHAR2区别在哪里,mysql或者postgresql理的char和varchar又该对应哪个?你别说,snowflake真把这几个类型的名字继承过来了,为什么说是名字?因为背后都是同义词,实际只有一个类型varchar。
DIRECTORY与STAGE。在Oracle中,使用数据泵的时候,要先创建一个指定目录下的directory,作为数据库对象来管理。无独有偶,在snowflake中,也有一个类似的类型stage。这两个对象类型最重要的职能都是保存数据的备份,方便集中管理。而测试的过程中从创建到授权再到使用,整个思路几乎是一致的。如果说两者之间的区别,就是snowflake对stage中保存的内容实现了更加精细化的管理,show stages之后,能够看到的内容更多。
Profile和密码策略。在Oracle中,profile允许管理员设置密码策略,如密码复杂性、有效期、重复密码策略、锁定策略等,是一个密码管理的模板,不需要对每个用户单独管理。类似功能在snowflake中对应的是密码策略PASSWORD POLICY。同样是创建一个PASSWORD POLICY,然后在诸多参数中选择调整,再应用到具体的用户中,可以实现对用户密码策略的批量管理,而不用独立维护。
闪回与时间穿越。Oracle中闪回FLASHBACK是我之前常用特性,比如做failover的测试,大大节省了数据库恢复的时间,代价是额外的存储和性能开销。Snowflake也提供了一种类似功能的特性,时间旅行查询(Time Travel Query)。这种功能允许用户查询数据在历史上的任何时间点的状态。差别在于,这个是基于云原生的技术开发,不需要额外做操作,只需要带上时间戳查询即可,比Oracle需要手动指定和维护要更加方便高效。
小结
当然要说的是,几个相似的对象类型或者概念比较之下,两者仍然有各种差异,而且从产品整体思路出发,能够看出Oracle与snowflake的区别:
1. 本地部署与云原生。Snowflake的设计更现代化,侧重于云服务的便利性和灵活性,而Oracle则提供了更多的控制和定制选项,适合需要高度定制和本地部署的场景。从闪回与时间穿越就能看出来,一个要自行配置,一个自带特性。
2. 运维门槛。Oracle庞大的体系,对DBA的素养和理解要求很高,现在迈入公有云之后,也许有所淡化,可是诸多参数以及过往历史,入门仍然需要较高的门槛;snowflake作为云原生,已经尽可能要降低DBA的人为干预,把很多特性和使用尽量简化,这一点从字符串同义词以及闪回自动开启就能看出。
3. 历史包袱。Oracle因为几十年的历史,很多过往的配置、使用习惯都要考虑之前用户的使用习惯和传统,snowflake这一点上就轻装上阵。例如授权管理,Oracle既有对角色的授权又保留了对用户单独授权。而snowflake则是严格的RBAC,不允许对用户单独授权。
