




背景
业务部门反馈,有2个系统夜间推数,最近执行时间由原来的6分钟增加至20分钟,严重影响2套业务系统后续任务处理,需要排查原因。
环境信息:
业务A,数据库版本:11.2.0.4 RAC
业务B,数据库版本:11.2.0.4 RAC
由业务A 推送数据至业务B,推送通过Oracle dblink方式 直接插入。
在业务A数据库执行SQL,主要的SQL逻辑如下:
insert into B.tab1@to_b select * from A.tab1;
业务沟通及分析
沟通
根据业务部门反馈,了解大致问题,后续和业务沟通,需确定以下信息:
Q1:最近是否有此任务的相关变更?
A:业务部门反馈,最近无任何变更。
Q2:执行时间时间增加至20分钟,是慢慢增长上来或者某一天增长上来?
A:业务部门反馈,上周五突然就增长,最近3天一直20分钟。
Q3:此任务涉及多少张表,是所有表同时插入慢,或者是个别表插入慢,推送数据量有何变化?
A:业务部门反馈,任务涉及8张表,只有1张表慢,所有时间都花费在这一张表上,推送数据大概350万条,而且这张慢表并非推送数据条数最多的表。
Q4:在业务A推送期间,业务B是否对此表有操作?
A:业务部门反馈,推送期间业务B对此表无任何更新插入查询操作。
Q5:此任务大概处理逻辑?
A:业务部门反馈,业务A需要每日计算当月1日至当日的数据,定时推送给业务B,推送前,业务A通过delete 方式删除业务B 前一日推送数据。
另外业务还反馈,在业务B的数据库使用如下语句进行tuncate 操作需要6分钟,时间较长
alter table xxx truncate partition p_xxx update global indexes;
分析
根据问题现象以及与业务部门的沟通,问题处理有如下三个方向:
方向1、业务A 数据库查询时慢,进而造成推数慢
方向2、业务A,业务B 之间dblink 通过网络传输数据,可能网络存在问题
方向3、业务B 数据库表,本身存在问题,插入数据慢
通过观察数据推送逻辑后,发现,方向1 不存在问题,因为是一张单表查询,在业务A手动查询速度并不慢。
insert into B.tab1@to_b select * from A.tab1;
通过与业务沟通Q3,方向2 可能也没有问题,后续让网络同事排查当时网络,网络正常,确认不是此处问题。
剩下就可能方向3,业务B 数据库表本身有问题,下面针对此表进行详细分析排查。
排查过程
业务B数据库表信息搜集
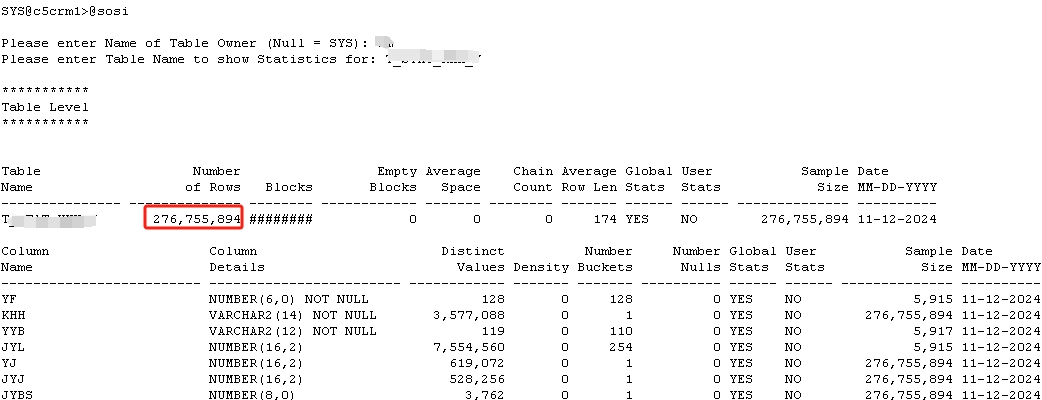
通过sosi脚本查看得如下信息,业务B数据库表tab_2024(用此名代替)。
表类型:按月分区表
表数据量:218G(碎片率79%)
数据行数:2亿
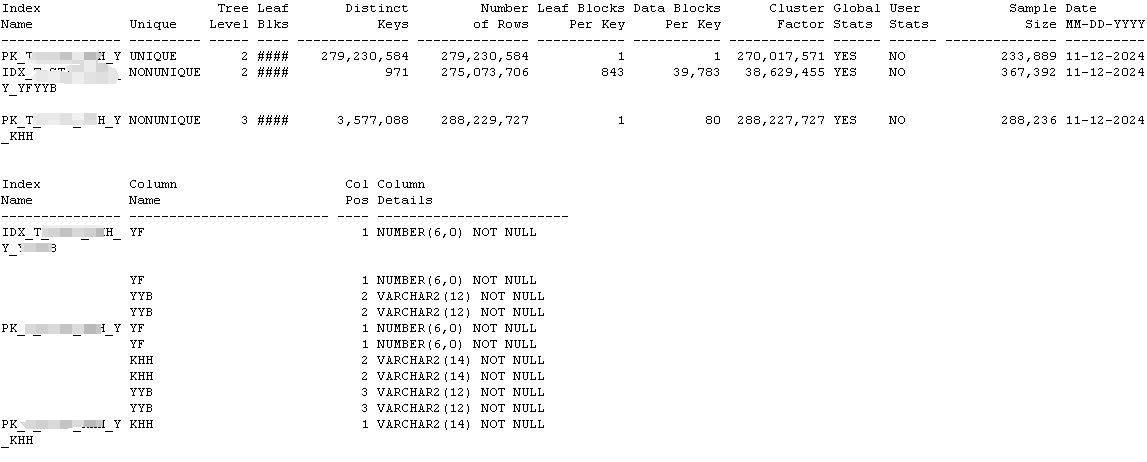
索引:3个(1个主键、1个本地、1个全局)

正面验证-业务反馈问题
虽说业务部门说明了此次问题的现象,本着眼见为实的原则,亲自验证下问题。
通过业务部门描述,在测试环境还原一套业务B的数据,业务A 向 测试环境推送数据。执行时间在16分钟35秒,这里只是执行有问题的表,总的时间应该与业务部门反馈一致,确实需要20分钟,问题被验证,下面进行针对分析。

侧面验证-业务B数据表问题
目前排查方向是业务B数据库表tab_2024存在问题。
为了进行一步验证,在测试环境创建一个与表tab_2024结构相同的分区表tmp_tab_2024,并进行插入测试,惊奇的发现此次插入只需40s,再一次证实表tab_2024 可能在设计或者数据量上有问题。
注:测试表tmp_tab_2024为空表,可能也是插入较快的原因。


分析1-是否碎片太高引起
在前期进行业务B数据库信息搜集时,发现表tab_2024碎片率很高,可能是长期的数据增删造成,如今插入时,需要在之前的碎片空间中找地方存储,导致插入较慢。
测试环境暂时通过导出导入的方式进行碎片清理。
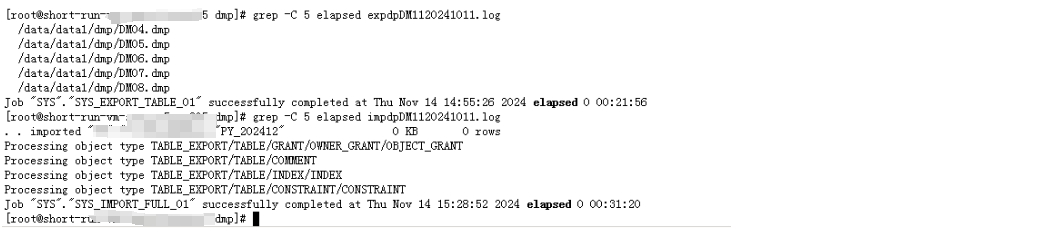
重新导入后,数据量为54G,较原来的218G,减少75%,没有了碎片问题,可以进行再次测试。

效果如下15分57秒,基本没有提升。看来碎片并不是影响插入慢的主要原因。

分析2-1 从会话等待事件分析
既然清理碎片解决不了问题,重新还原测试环境,保证与生产的一致。
在业务A进行插入时观察业务B的等待事件。
业务A 进行插入

业务B 观察会话,等待事件“db file sequential read”等待对象id 186789,而且观察业务B主机资源使用,发现根本没有网络流量,也就是说,业务B一直在维护对象id 186789,
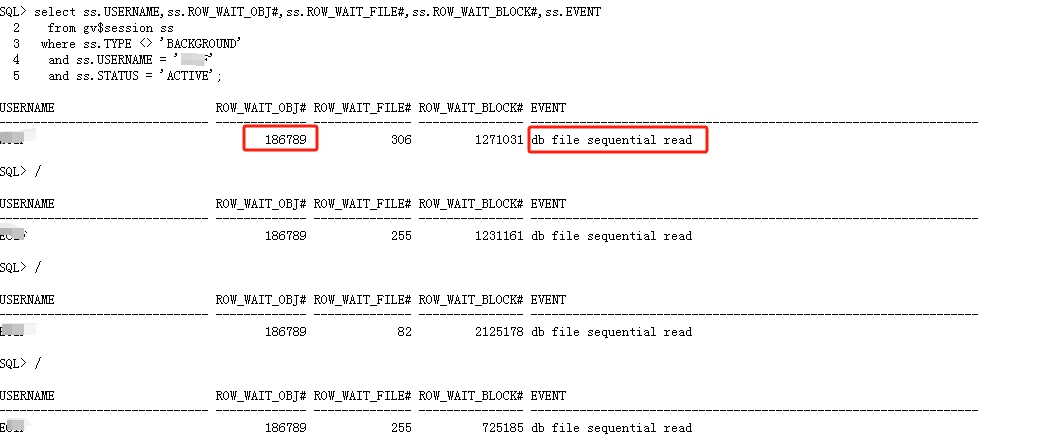

分析2-2 对象id 186789
进一步查询对象ID 186789,发现是表tab_2024 的一个索引,而且还是全局索引,索引字段根据上面搜集的信息可知,只有一个字段KHH。

再次与业务沟通,得知,此索引是很早之前为一个功能设计的,后来功能下线,此索引就一直留着,没有清理,根据业务描述知,KHH字段在每个分区中唯一,每个月都有一条数据,这也解释了业务在tuncate 分区操作需要6分钟的原因(这是本人猜测,暂未实际验证),要维护全局索引,因为全局索引字段的特殊性,整个索引都要移动一遍。
分析2-3 删除全局索引
因为是测试环境,在这里先删除此索引进行验证

分析2-4 结果验证
清理完全局索引之后,再次在业务A执行插入操作,插入时间降至41秒,而且通过测试环境的资源监控,也可以发现,网络上有流量,证明数据一直在传输,问题到此解决。

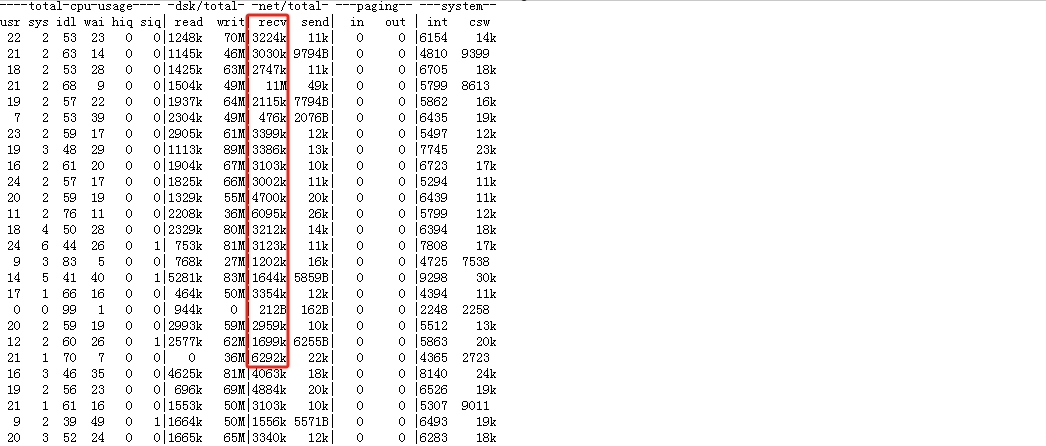
而且tuncate分区由于不需要维护全局索引,再次执行执行7秒。
业务同步
在测试环境虽然已经发现,并解决了问题,但正式环境还需要谨慎些,与业务部门沟通,最后约定实施:
1、业务再次确认索引是否在用,
2、业务确认不用之后,挑选业务闲时进行索引变更,
3、业务监控删除后执行效果。
4、日后业务定期梳理相关表设计,清理不用表数据和索引。
由于表碎片的问题,不管是通过导出导入方式,或者move 表,都需要较长时间,业务暂时考虑不清理碎片。
总结
在业务部门反馈后,运维人员首先需要做的,根据自己的实施经验,与业务部门提前沟通相关基础信息,对于排错可起到事半功倍的效果,后续的问题亲自验证,以及问题发现后与业务部门共同协商实施方案,都是必不可少的环节。
