




背景
PolarDB-X V2.4 版本新增支持了列存查询加速能力,在成本低廉的 OSS 存储底座上,构建了一套成熟的列存SQL引擎,为查询分析提供了更为优越的性能、更高的成本效益以及查询加速能力。
列存查询加速基于存算分离的架构:列存引擎(Columnar)负责列存索引的构建,实时消费分布式事务的 binlog,同步到列存索引并持久化到 OSS 存储;计算引擎(CN)负责列存查询和事务管理。列存索引的存储采用 Delta + Main + 标记删除的组织结构(Delete-and-Insert),构建的数据会以 CSV + ORC + Delete bitmap 的格式存储在 OSS 上。相较于 Copy-on-Write 和 Merge-on-Read,这一模式既实现了行存到列存数据的低延迟同步,也不会对查询侧引入过大的额外开销,更多技术详情可以参考《PolarDB-X 列存索引 | 列存引擎的诞生》
为了实现 Delete-and-Insert 方案列存存储的高效更新,需要能快速定位到历史有效数据的位置,进行标记删除,这便引入了该列存实现方案中唯一需要有状态的对象:列存主键索引(Primary Index,简称:PkIndex)。同时为了实现单节点大规模列存构建,主键索引的高性能和可持久化也成为了必备的选项,具有较大的技术挑战性。
1. 持久化列存主键索引
由于位于列存维护主路径上,PkIndex主键索引的读写性能直接决定了低延迟列存的 SLA 上限,同时在全量构建和增量维护中,对列存数据的正确性保证也起至关重要的作用。主键索引的整体模块示意图,以及其在列存索引构建中的作用如下图所示。
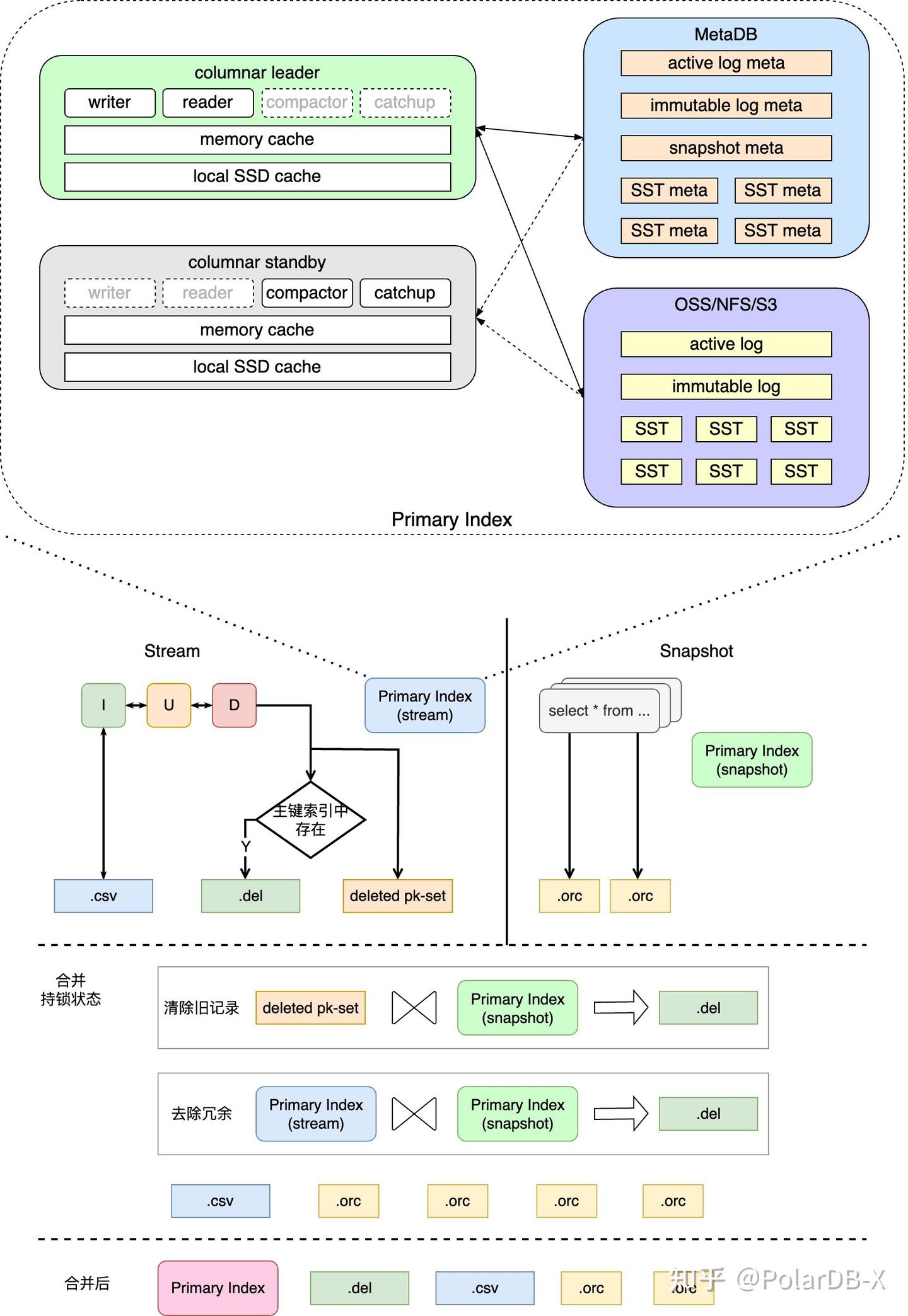
1.1 存储模型
为了满足低存储成本以及列存引擎节点无状态迁移等特性,PolarDB-X 的列存主键索引数据存储在 OSS 上,而元数据存储在 MetaDB 中。在综合考虑了对象存储的特性以及业内存储引擎的实现后,我们选择自研实现了基于 OSS 的PkIndex主键索引存储引擎,选择了 LSM-tree 的数据结构,并针对 OSS 的特性进行了一系列优化,满足列存引擎对于高吞吐写入以及低延迟查询的需求。
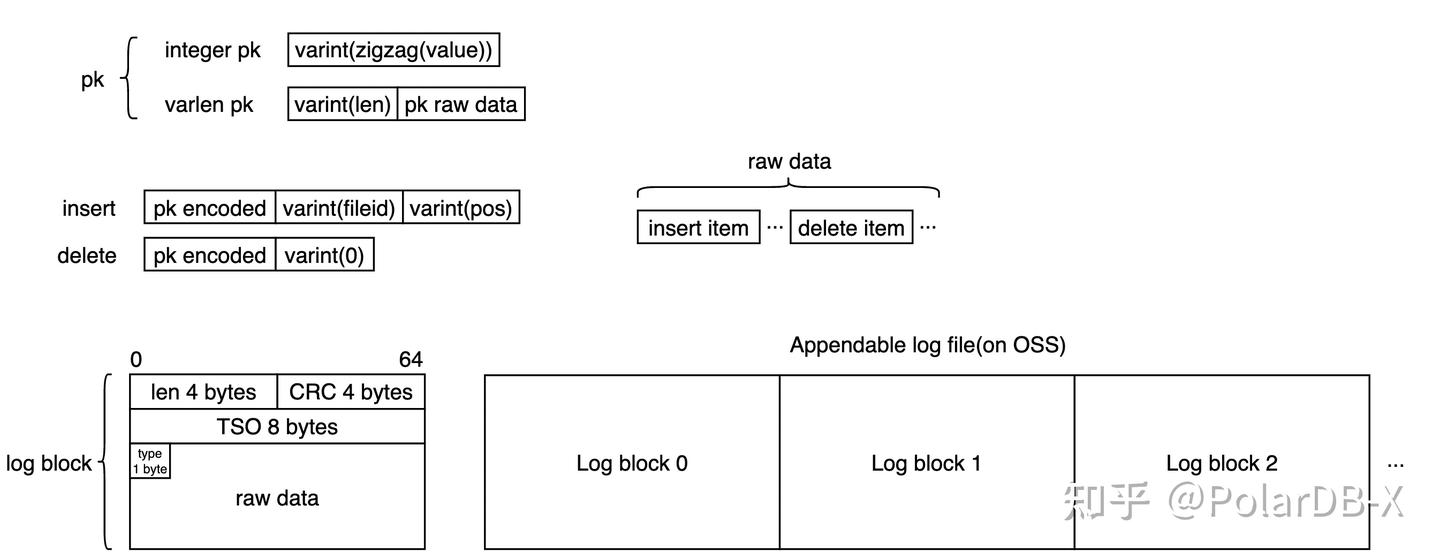
1.2 存储编码
为了尽可能压缩存储空间、提升有效数据密度,主键索引会根据数据的特征进行压缩编码。
在列存主键索引中,Key是数据记录的主键,主要支持2种类型:
- 整形主键,经过zigzag编码后以变长整形压缩存储;
- 其他类型主键,变长整形记录主键长度,其后跟着二进制编码后的主键,支持任意自定义类型。
Value是列存存储数据的位置,也有2种类型:
- 对应列存数据有效,为对应行数据在列存存储中的文件(fileId)和偏移(pos),均采用变长整形压缩存储;
- 对应列存数据被删除,使用单个字节0进行标记。
写入都是批量提交的,批量数据中包含插入条目和删除条目,相同的key的操作都会被压缩成一条记录,按上述方式进行编码,按操作顺序密集排布存储到 log block 中,每个 log block 头部都会存储该块长度、校验和、提交时间戳、和主键类型。整体如下图所示:
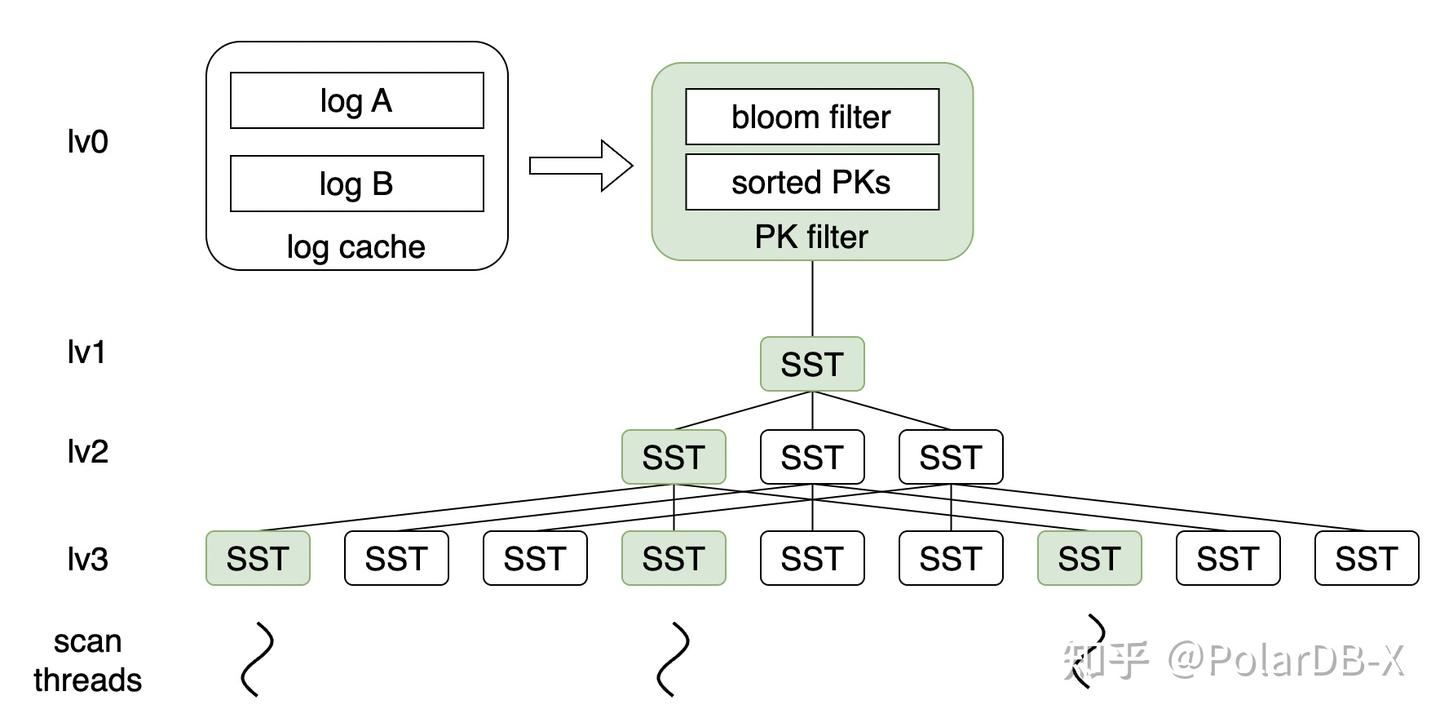
1.3 数据分层及分布
写入数据多了后,log 会变长,降低读取和恢复的时间,compaction 模块负责将 log 模块合并分裂到下层SST中。
整个 LSM-tree 如下图所示:
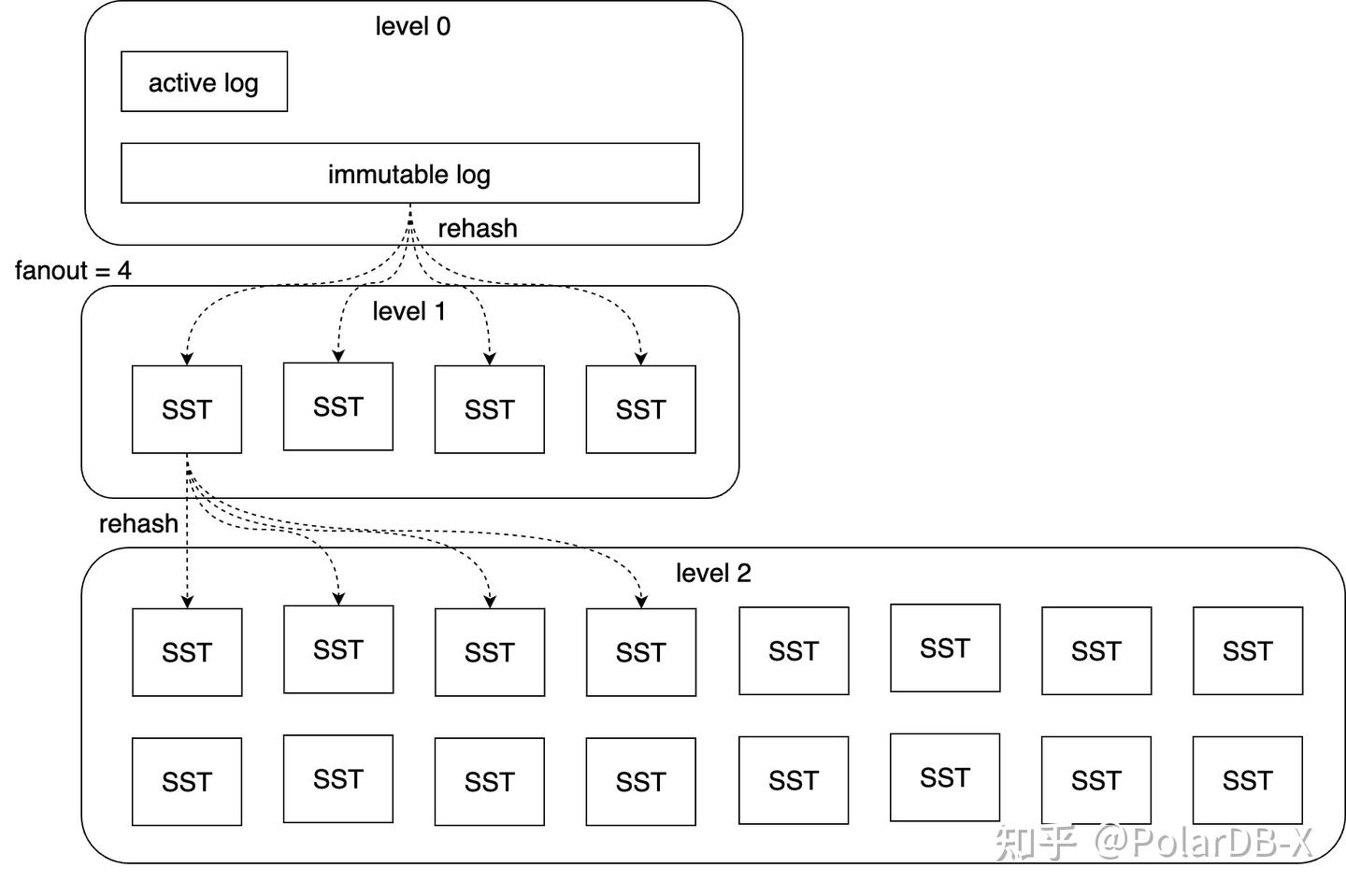
- 基于 LSM tree 思想
- 通过 appendable file 实现 WAL 基于 OSS 持久化
- 分层结构实现冷热数据分离
- level 0 层为 log 层,数据存在交叉,数据无序,顺序写入,在 commit 时以 batch 方式写入
- 为了 compaction 便利且不影响写入,log 分为 active 和 immutable 2种
- active log 在任意时刻有且只有1个,只可以往 active log 中追加新的数据
- immutable log 在 fix(数据与元数据不一致时,会触发修复流程)和 compaction 的时候产生
- immutable log 文件不可变
- level 1 - n 为 SST 层,数据不交叉,文件内数据根据 key 排序
- OSS 文件采用变长编码密集排布数据,同时额外存储稀疏索引便于快速二分定位
- SST 文件不可变,由元数据库记录文件长度、CRC32、hash 桶信息、bloomfilter等相关信息
- 数据存储分片采用一致性 hash 的方案,使 n 层的一个 SST 严格对应 n+1 层的 k 个文件,k 为参数 fanout
- 即:lv 1 最多有 fanout 个 SST 文件,lv n 层最多有 fanout^n 个 SST 文件
- 每次一个 SST 向下层 merge,最多涉及读 1+fanout 个 SST,写 fanout 个 SST,读写量严格可控,同层内所有 merge 完全不交叉,有利于任务并行
1.4 写入原子性保证
由于列存引擎节点存在多个(主节点、热备节点等),存储数据元数据分布在 OSS、MetaDB 上,同时主键索引需要具备快速迁移拉起写入的能力,其在多节点多活场景下的正确性保证便尤为重要。这里我们通过将写入流程拆解为3步,实现了类似 Compare-And-Set 的方式的原子写入,确保不存在部分更新或者盲更新的情况。
具体流程如下:
- 首先使用快照读的方式获取到当前的 active log 位点
- 借助 OSS 的 append 能力,通过指定位点的方式原子追加 log 数据,如果出现写冲突,这一步就会报错
- 通过一条 update 语句在元数据库原子更新 active log 位点,通过更新行数来判断是否有写冲突,最终完成整个日志的提交
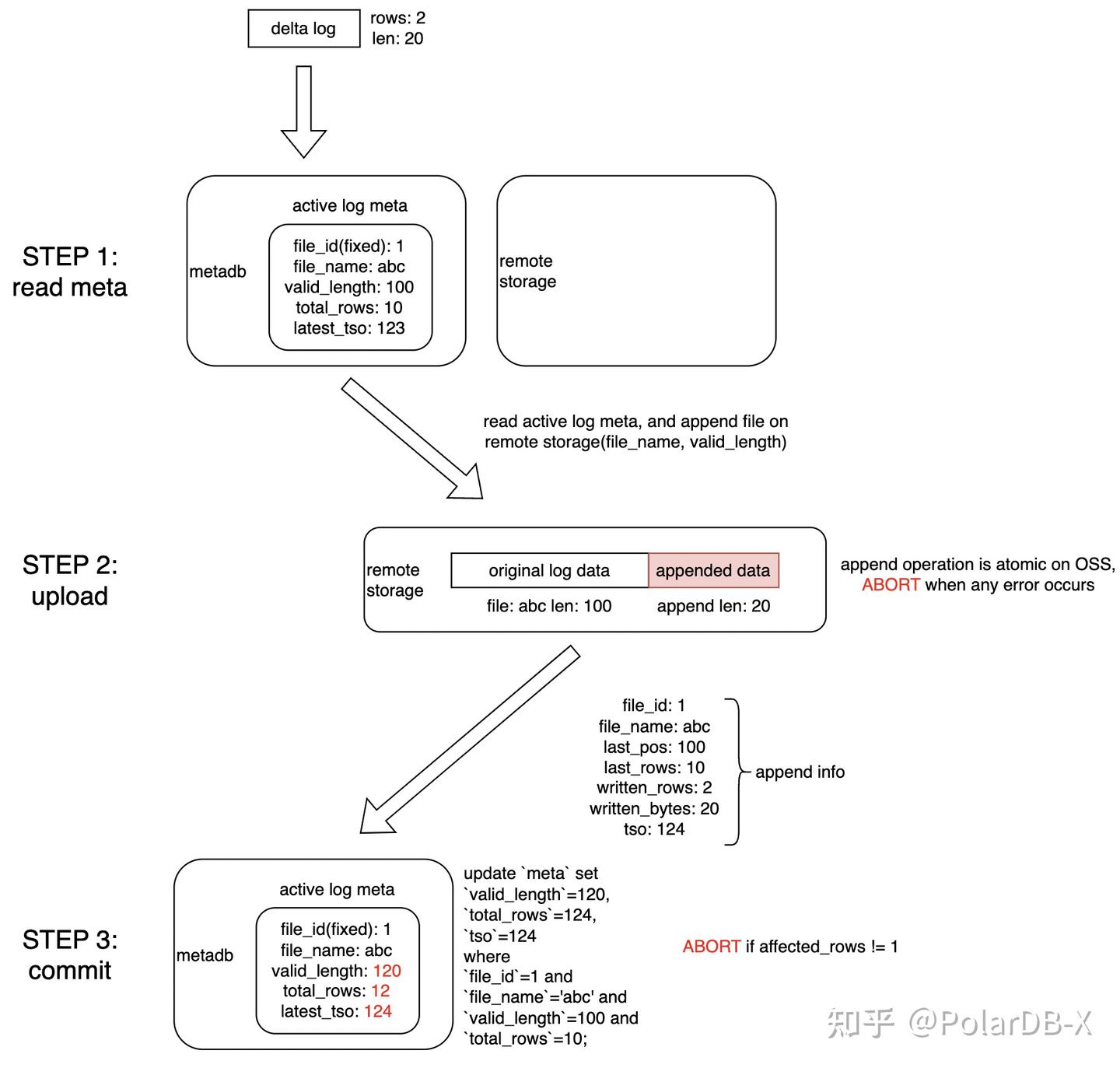
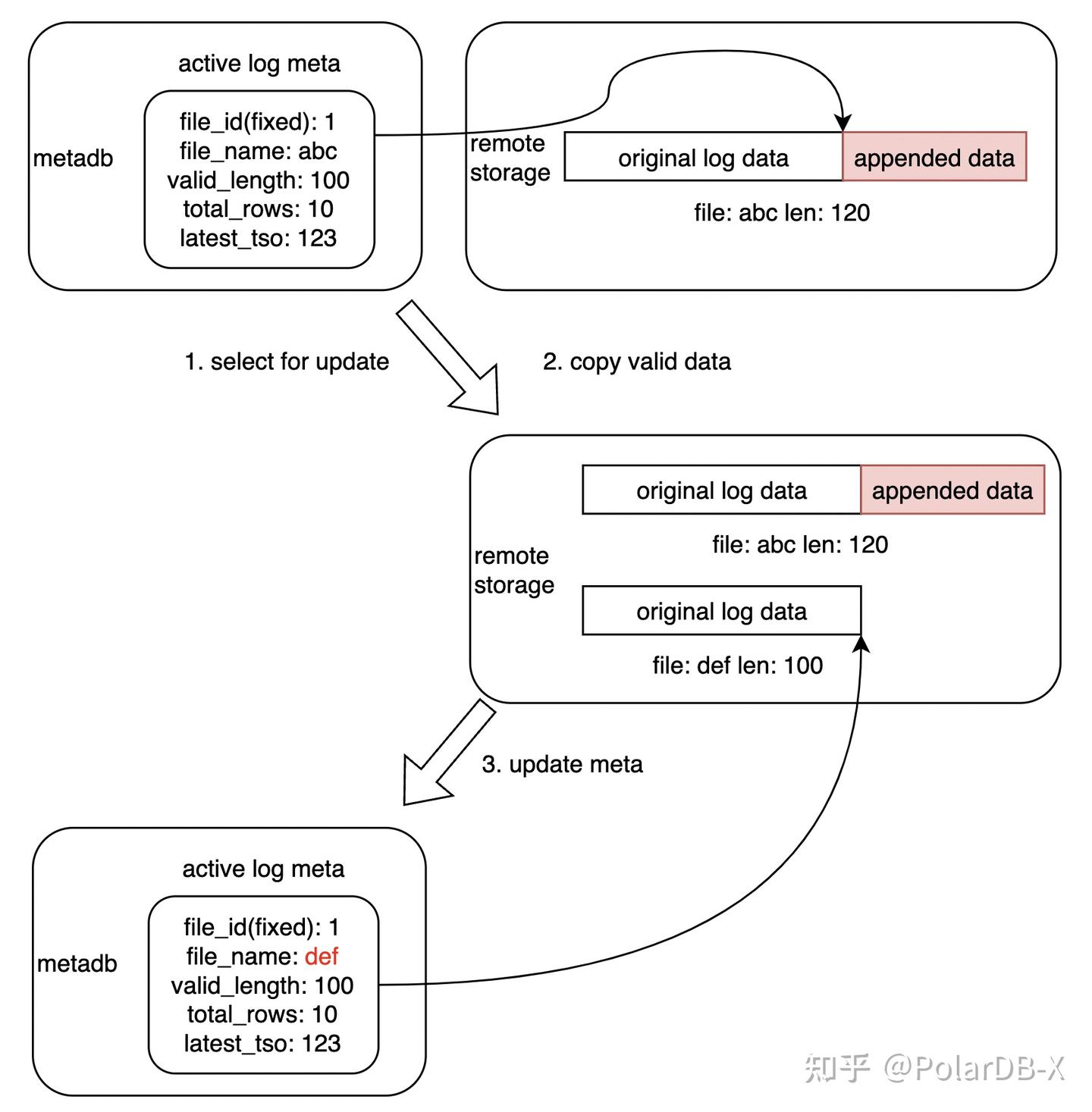
由于数据更新和元数据更新的解耦,部分场景下的冲突或者非预期崩溃可能造成中间状态的残留,通过如下的 fix 流程即可恢复到一致状态。
具体的流程如下:
- 通过 select for update 锁定对应 log 元数据,避免并发操作
- 将原有 log 文件保留,并截取其有效部分复制到新文件
- 更新元数据指向新文件,确保 OSS 上文件和元数据库的一致
1.5 Compaction
compaction 作为 LSM-tree 中的重要部分,列存主键索引存储引擎针对 OSS 高延迟、高吞吐的特性做了一系列优化。
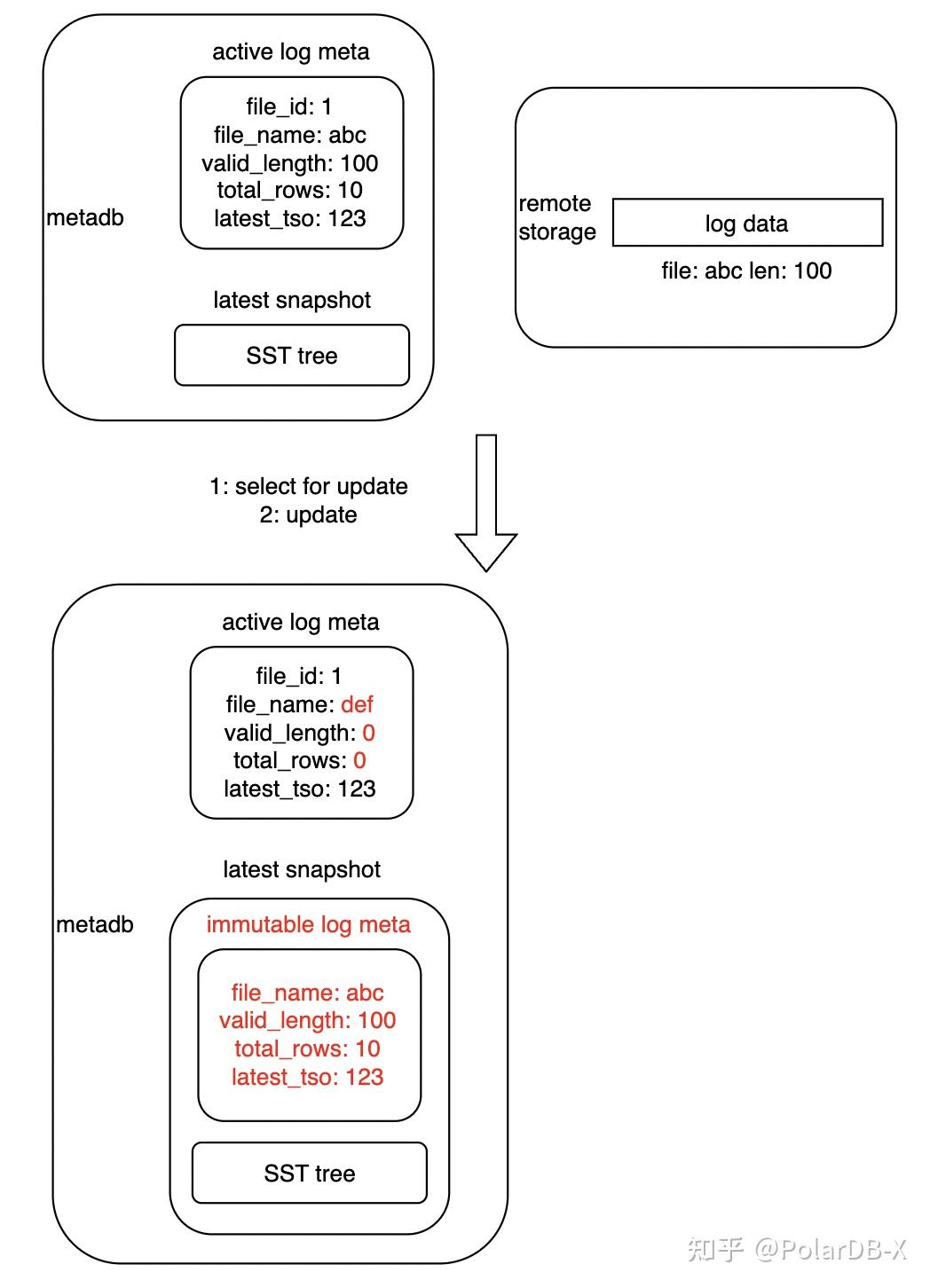
首先为了适配存储、元数据解耦场景,主键索引将 compaction 拆为 2 步,以提升过程可靠性以及操作幂等能力:
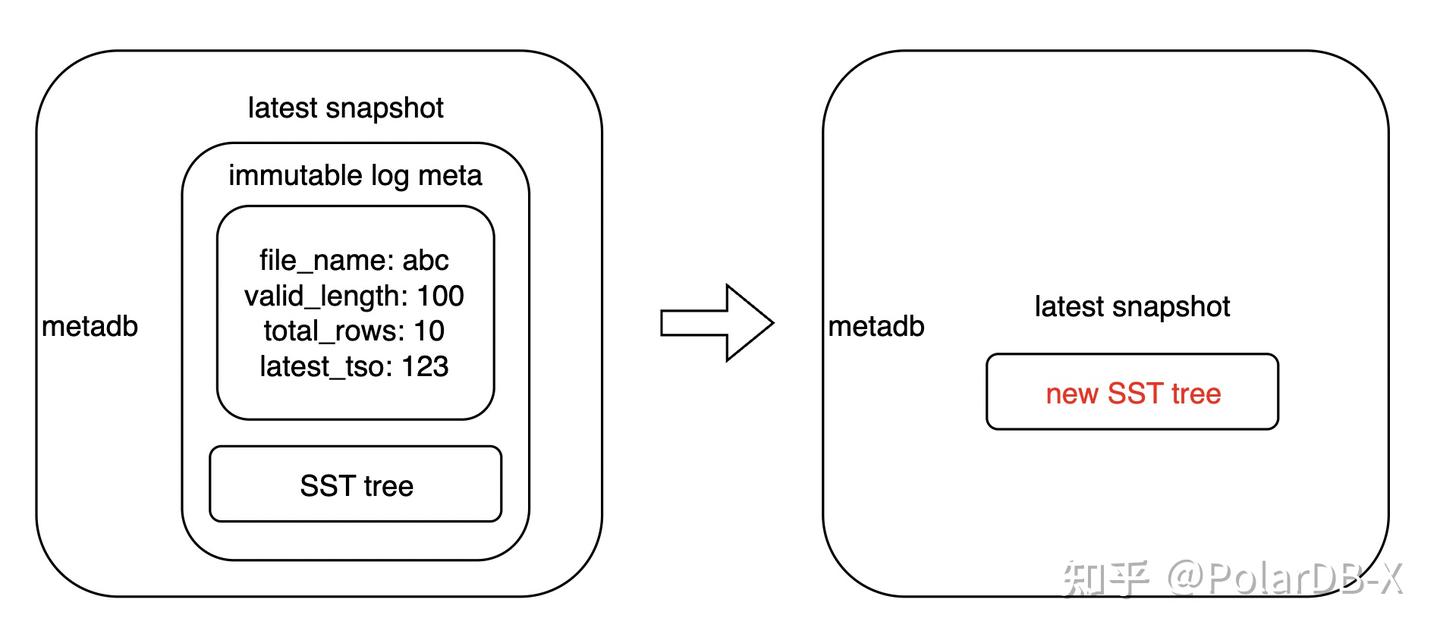
- 生成带有 immutable log 的待 compaction 快照;
- 对上述快照进行等价变换,消除 immutable log,生成新快照。
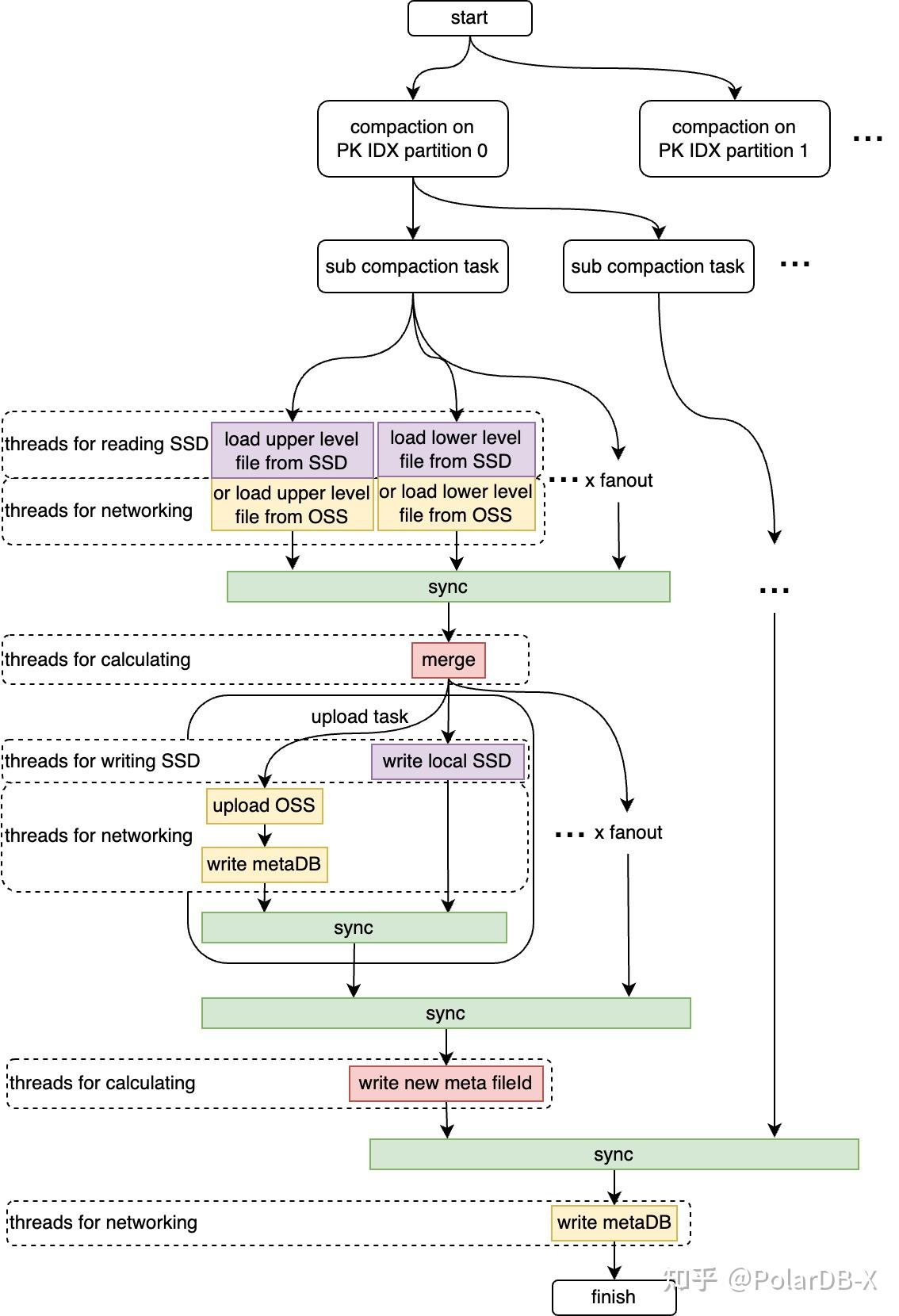
其次通过前文所述的数据分层及分布规则,将 LSM-tree 划分为以 fanout 为单位的若干独立 compaction 子任务,使调度任务细粒度化,以适配低配规格。针对高配规格,通过任务类型划分线程池、并行调度等方案,最大化利用 OSS 存储的高吞吐特性,用高并发、细粒度、多流水线的任务编排,加速 compaction 流程。
1.6 读流程
对于列存主键索引,仅有2种访问模式:
- 点查,用于查找需要删除列存数据的位置,打上 deleted 标
- 全量遍历,用于在创建列存索引时,增量全量合并时去重
特殊的述访问模式,也是促成主键索引选择一致性哈希的分层分布规则的重要原因。由于点查是列存数据更新主路径上的高频请求,且点查也是 LSM-tree 的弱势所在,主键索引针对这个问题做了以下优化:
- 基于冷热数据访问频率的假设,LSM-tree 先天具备冷热分离的能力
- 基于一致性哈希的分层分布算法,点查仅需要在每一层中查询一次,而且可以通过 key hash 快速唯一确定 SST 文件
- 元数据中存储了每个 SST 的 bloomfilter,进一步减少不必要的 SST 读取
- SST 文件大小阈值适配 OSS 的最优大小,提升 OSS 访问效率
- 多层缓存,level 0 的 log 全处于内存,使用哈希表加速,level 1-n 的 SST 采用内存、SSD、OSS 三层缓存结构,尽可能降低 cache miss 的代价
针对全量遍历请求,采用从底层往上的遍历方式,过滤对应上层找到的数据,实现有效数据的遍历,同时针对一致性哈希的分布,并行编排扫描线程,能最大化 cache 命中率。
1.7 log/SST cache
作为数据结构中唯一可变的、无序的、可能存在重复的容器,log 层中的数据,需要通过辅助数据结构来加速读取性能。在 PolarDB-X 的列存主键索引中,我们使用了哈希表来实现这一功能。不同于传统的 LSM-tree 先写 memtable,再生成 log,我们是先生成 delta log,原子提交成功后,再重放到哈希表中的。哈希表仅作为 log cache 的存在。基于此特性,log cache 中的数据迭代也是通过 compaction 流程推动的,log cache 分为多个哈希表,在 log 切换以及 log 压入 SST 后,会滚动推动哈希表淘汰,以释放内存。
而 SST 的 cache 就较为简单,由于 SST 是一个不变的数据结构,同时内部有序且具备稀疏索引,cache 中仅存储 SST 的二进制数据,无论点查还是遍历,仅需要维护一个 cursor,通过稀疏索引二分查找定位,然后边解码边吐数据即可。
除此之外,由于 PolarDB-X 的列存引擎是使用 Java 开发的,使用 Java 开发存储引擎还有个棘手的问题,即内存管理问题。对于非基础数据结构的哈希表,这种大量小对象、长生命周期、且大堆内存的场景下,cache 数据极易落入到老年代。几十亿的小对象在 FGC 流程中大量占用 CPU 并增加扫描时间,造成严重的性能问题和长时间的 Stop-the-World。为了解决这个问题,我们针对性开发了基于 Arena 的内存管理、哈希表和排序算法,该方案将在后续文章中介绍。
2. 高可用热备
PolarDB-X 的列存引擎,采用一主+一热备的模式,通过租期抢主。列存主键索引作为具有状态的数据结构,同时占用了近一半的节点内存作为 buffer pool,需要在高可用切主时,能快速接替主节点并提供列存构建服务,因此热备需要具备快速跟进主节点重放 log 的能力。主节点在完成提交后会主动广播 sync 指令,热备节点根据元数据库的 log 位点完成快速重放。
catchup 算法会根据当前状态和目标位点,分为以下三种情况,以最小代价完成重放:
- catchup active:热备重放位点位于最新快照的 active log 上,则仅需要重放 active log 落后的部分
- catchup immutable:热备重放位点位于最新快照的 immutable log 上,则需要重放 immutable log 的落后部分,并重放全部 active log
- fully recover:当热备重放位点无法在最新快照上找到时,说明已经落后很多了,这时会清除全部状态数据,重置 SST 元数据,并重放全部 log 部分,完成完整的状态恢复
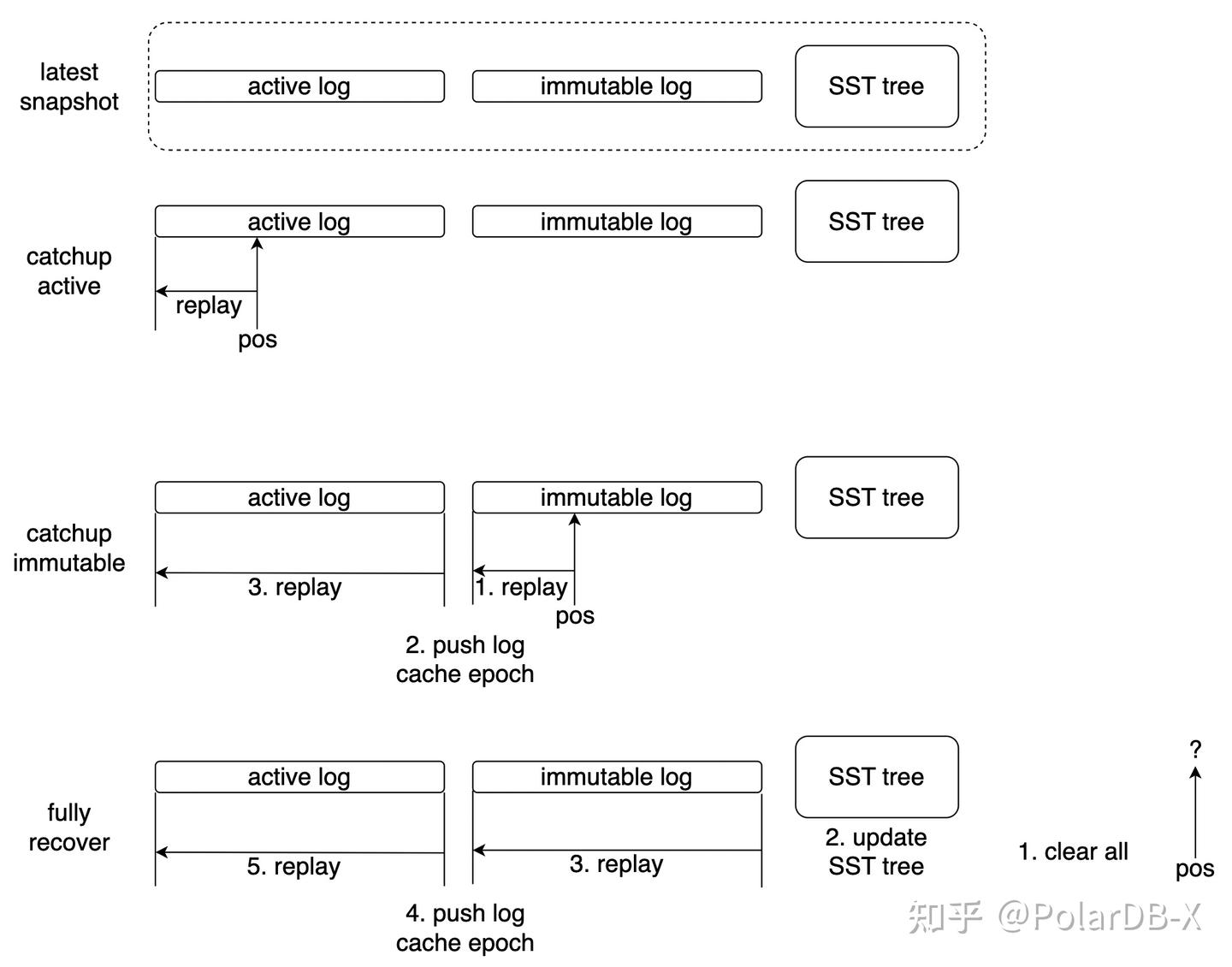
除此之外,热备节点还会承担主键索引的 compaction 操作,降低对主节点的 CPU 和 IO 压力,充分利用全部节点的资源。
3. 性能数据
针对 PolarDB-X 的列存引擎组提交模式,我们针对 16c64g 节点设计了 2 套数据规模的写性能压测:
- case 1:1.6亿主键范围随机写,batch size 300w(30wqps,10s group commit),100次 batch insert 共3亿条写
- case 2:100亿主键范围随机写,batch size 300w(30wqps,10s group commit),1000次 batch insert 共30亿条写
| case | 时间 | 写吞吐 | log 写入速率 | SST 数量 | OSS 写总量 | OSS 写吞吐 |
| 1 | 35.6 s | 8415214.0 rps | 73.2 MB/s | 136 | 3682.5 MB | 103.2 MB/s |
| 2 | 701.3 s | 4277475.5 rps | 40.6 MB/s | 32609 | 209902.9 MB | 299.2 MB/s |
从写场景的测试数据来看,PkIndex主键索引,基本可以支撑未来百万TPS的能力。另外,从监控上看,未限流的情况下,基本能占满大规格节点的 CPU 资源,将内网带宽充分利用,并达到可观的吞吐量。
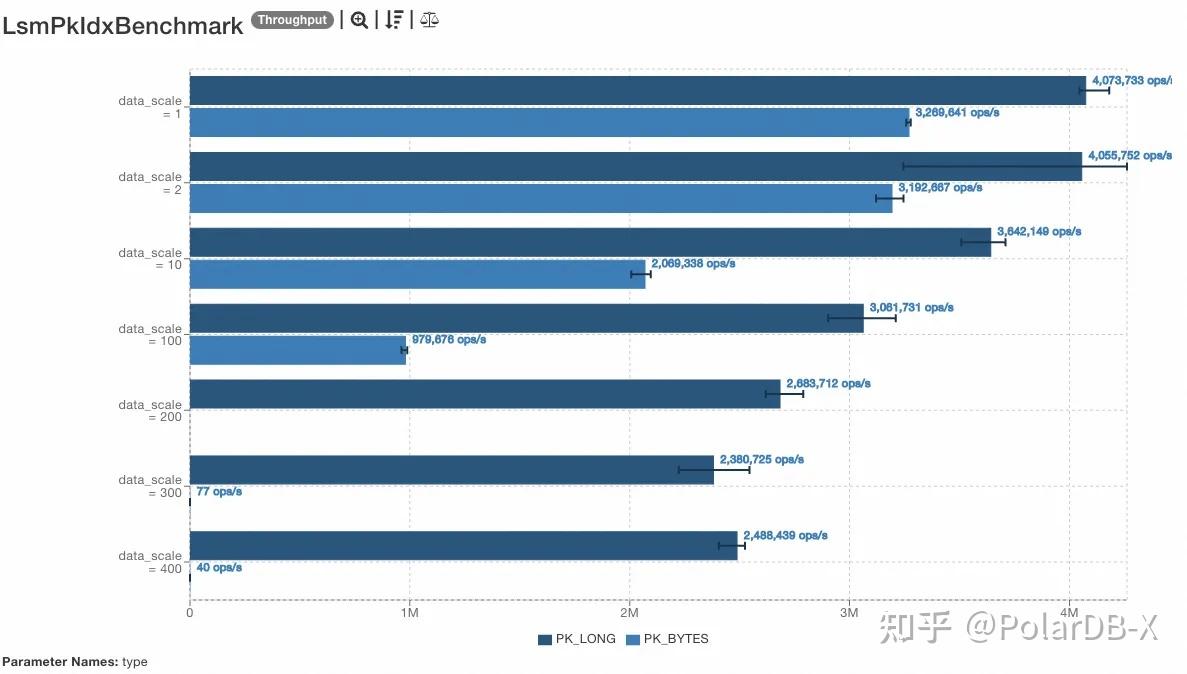
针对读性能,我们也测试了 long 型主键和 bytes(随机8-24字节)型主键的点查性能,限制 buffer pool 大小下的测试,可见未击穿 buffer 的情况下,吞吐量较为可观,可以达到200万+ QPS,击穿 buffer pool 后,性能回落到 OSS 的读取 QPS 等级,也符合预期。
4. 总结
PolarDB-X列存索引,采用了Delete-and-Insert方案,整个方案性能的关键就是PkIndex主键索引(快速定位行记录),在高性能、高可用上结合oss对象存储,PolarDB-X提供了crash recovery的秒级恢复、以及支撑百万级DML的吞吐能力。
5. 附录
列存系列相关文章:
