





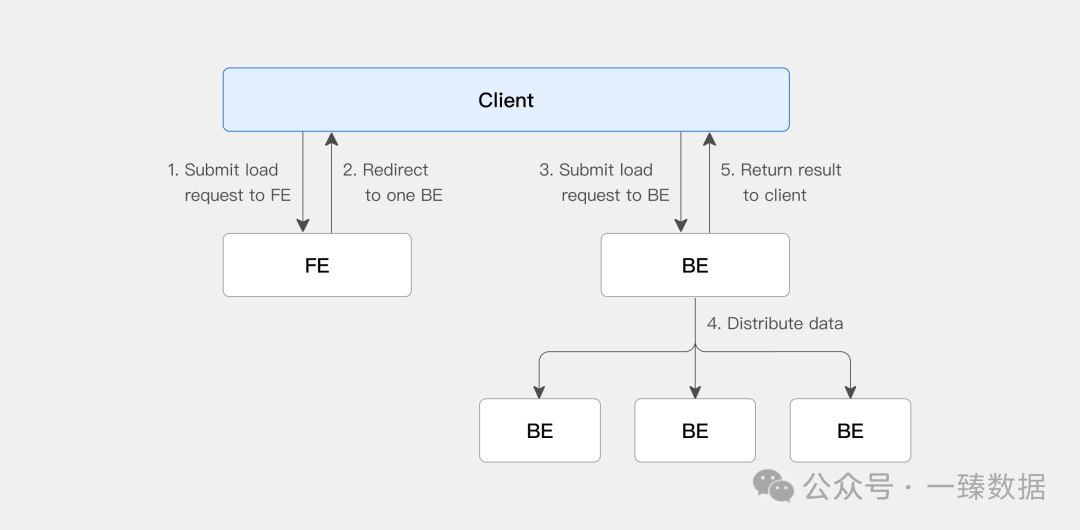
“Doris 的导入方式比较多,一般情况下每个场景都有对应的数据导入方式,比如Streamload、HdfsLoad(逐渐替换BrokerLoad)、RoutineLoad、MySqlLoad等。
其中大家用的最多的可能是StreamLoad的方式,因为一般用doris flink connector 、doris spark connector、datax等进行数据同步时,底层都是走streamload。由于 spark doris connnector/flink doris connnector/datax 底层都是走的streamload,所以遇到的导入报错情况也基本一致。
本文将一起学习Doris的Stream Load最佳实践指南。
导入报错梳理实践
1. 分区没有提前创建Schema
CREATE TABLE IF NOT EXISTS tb_dynamic_partition_test2(
`sid` LARGEINT NOT NULL COMMENT "学生id",
`name` VARCHAR(50) NOT NULL COMMENT "学生名字",
`class` INT COMMENT "学生所在班级",
`age` SMALLINT COMMENT "学生年龄",
`sex` TINYINT COMMENT "学生性别",
`phone` LARGEINT COMMENT "学生电话",
`address` VARCHAR(500) NOT NULL COMMENT "学生家庭地址",
`date` DATETIME NOT NULL COMMENT "数据录入时间"
)
ENGINE=olap
DUPLICATE KEY (`sid`,`name`)
PARTITION BY RANGE(`date`)()
DISTRIBUTED BY HASH (`sid`) BUCKETS 4
PROPERTIES
(
"dynamic_partition.enable"="true", -- 开启动态分区
"dynamic_partition.start"="-3", -- 保留前三天的分区
"dynamic_partition.end"="1", -- 往后创建一个分区
"dynamic_partition.time_unit"="DAY", -- 按天分区
"dynamic_partition.prefix"="p_", -- 分区字段以p_开始
"dynamic_partition.replication_num"="1", -- 动态分区中的副本数指定为1
"dynamic_partition.buckets"="4" -- 动态分区中的分桶数量为 4
);
-- data:
1,lisi,1001,18,1,1008610010,beijing,2024-04-26
Streamload:
curl --location-trusted -u root -H "column_separator:," -T /mnt/disk2/test.csv http://ip:8030/api/test/tb_dynamic_partition_test2/_stream_load
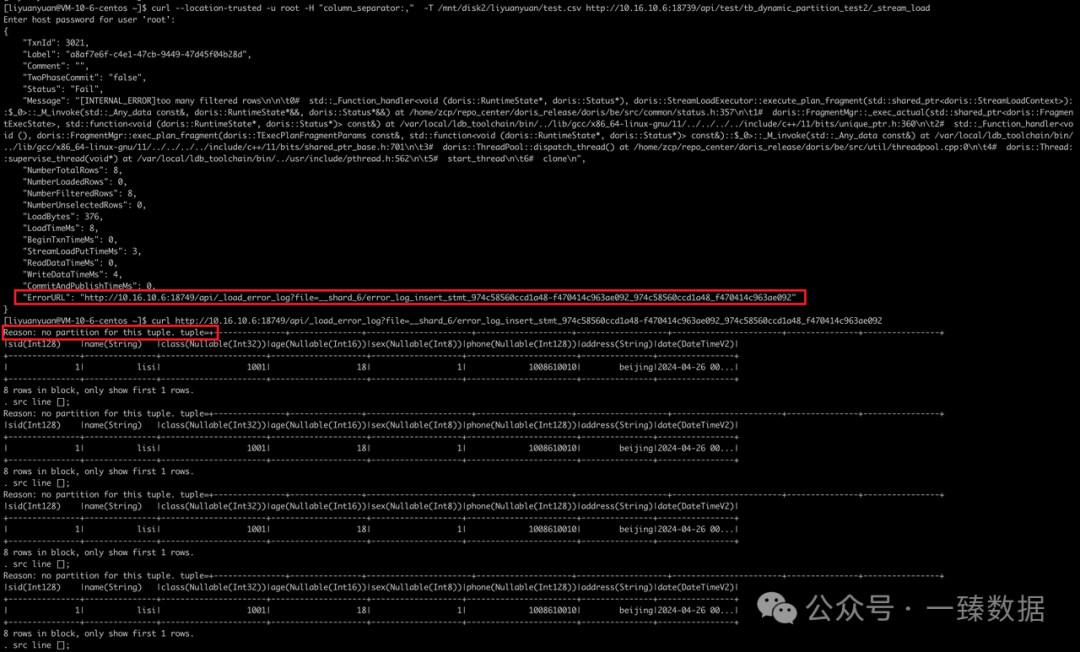
ERROR:
curl http://ip:8040/api/_load_error_log?file=__shard_6/error_log_insert_stmt_974c58560ccd1a48-f470414c963ae092_974c58560ccd1a48_f470414c963ae092
Reason: no partition for this tuple. tuple=+---------------+---------------+----------------------+--------------------+-------------------+-----------------------+---------------+----------------+
|sid(Int128) |name(String) |class(Nullable(Int32))|age(Nullable(Int16))|sex(Nullable(Int8))|phone(Nullable(Int128))|address(String)|date(DateTimeV2)|
+---------------+---------------+----------------------+--------------------+-------------------+-----------------------+---------------+----------------+
| 1| lisi| 1001| 18| 1| 1008610010| beijing|2024-04-26 00...|
+---------------+---------------+----------------------+--------------------+-------------------+-----------------------+---------------+----------------+
8 rows in block, only show first 1 rows.
处理方式,添加对应分区:
// 关闭动态分区
ALTER TABLE tb_dynamic_partition_test2 SET ("dynamic_partition.enable" = "false");
// 添加分区
ALTER TABLE test.tb_dynamic_partition_test2
ADD PARTITION p_20240426 VALUES [("2024-04-26 00:00:00"), ("2024-04-27 00:00:00")) ("replication_num"="1");
// 打开动态分区
ALTER TABLE tb_dynamic_partition_test2 SET ("dynamic_partition.enable" = "true");]
正常导入数据:
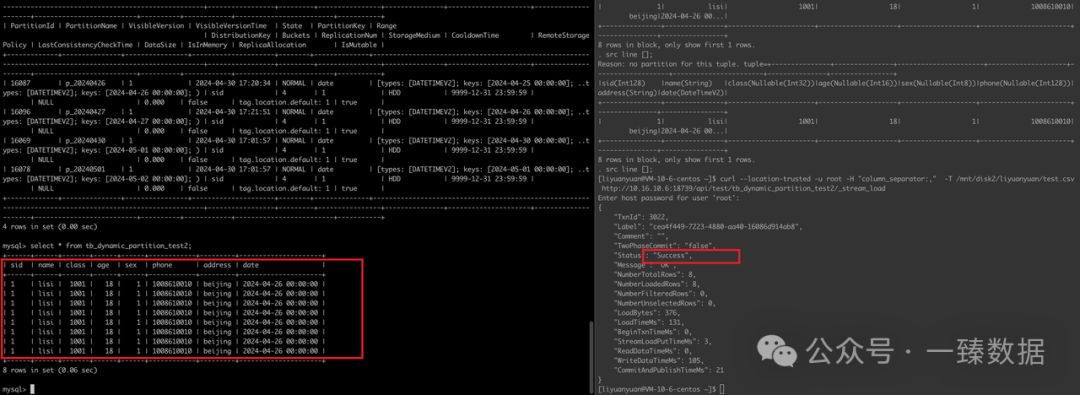
总结:
如果是数据找到不到对应分区,可以先排查分区是否创建,或者补分区、修改分区策略,保证数据在分区范围内。
2.数据和字段类型不匹配Schema
-- table schema:
CREATE TABLE IF NOT EXISTS test(
`sid` LARGEINT NOT NULL COMMENT "学生id",
`name` VARCHAR(5) NOT NULL COMMENT "学生名字",
`class` INT COMMENT "学生所在班级",
`age` SMALLINT COMMENT "学生年龄",
`sex` TINYINT COMMENT "学生性别",
`phone` LARGEINT COMMENT "学生电话",
`address` VARCHAR(5) NOT NULL COMMENT "学生家庭地址",
`date` DATETIME NOT NULL COMMENT "数据录入时间"
)
ENGINE=olap
DUPLICATE KEY (`sid`,`name`)
DISTRIBUTED BY HASH (`sid`) BUCKETS 4
PROPERTIES
(
"replication_num"="1"
);
-- 数据:
1,lisixxxxxxxxxxxxxxxxxxxx,1001,18,1,1008610010,bj,2024-04-26
Streamload:
curl --location-trusted -u root -H "column_separator:," -T /mnt/disk2/liyuanyuan/data/test.csv http://10.16.10.6:18739/api/test/test/_stream_load
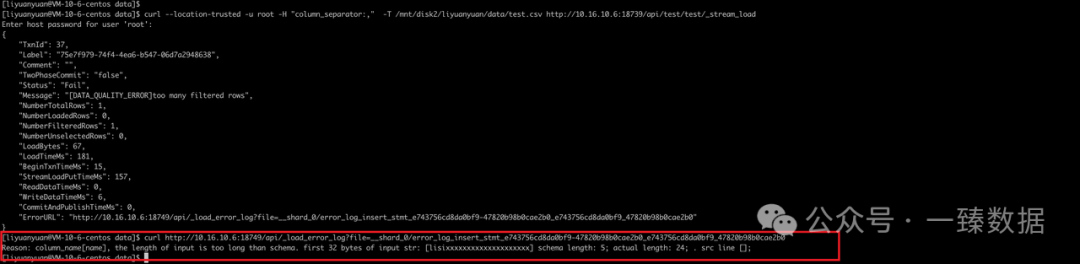
ERROR:
error:
curl http://10.16.10.6:18749/api/_load_error_log?file=__shard_0/error_log_insert_stmt_e743756cd8da0bf9-47820b98b0cae2b0_e743756cd8da0bf9_47820b98b0cae2b0
Reason: column_name[name], the length of input is too long than schema. first 32 bytes of input str: [lisixxxxxxxxxxxxxxxxxxxx] schema length: 5; actual length: 24; . src line [];
从报错来看,是 name 字段导入的数据长度大于字段类型的长度
处理方式,参考::
ALTER-TABLE-COLUMN - Apache Doris-- 修改列长度
ALTER TABLE test.test MODIFY COLUMN name VARCHAR(50) KEY ;
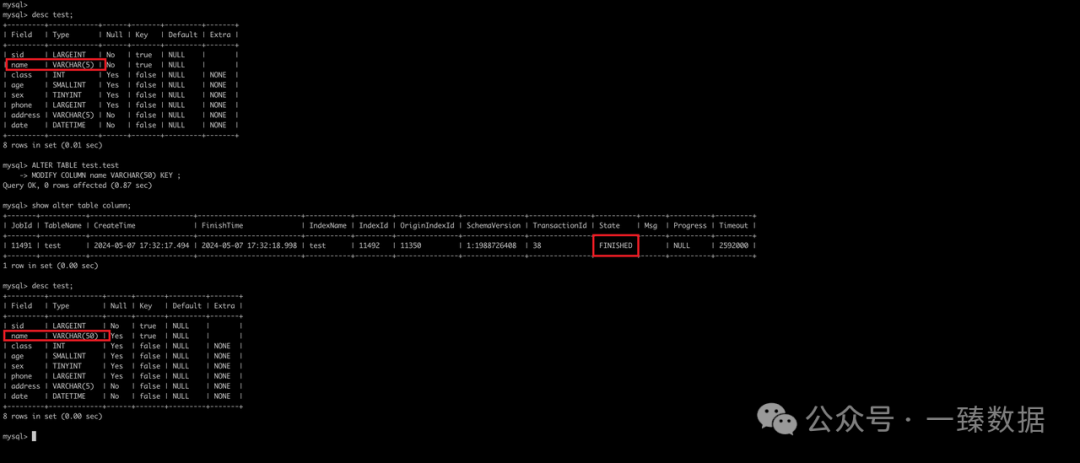
导入成功:
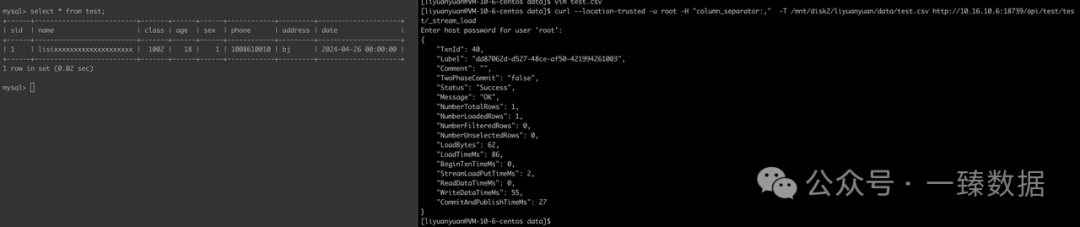
3. 导入列和schema 列不对应Schema
-- table schema
CREATE TABLE IF NOT EXISTS test2(
`sid` LARGEINT NOT NULL COMMENT "学生id",
`name` VARCHAR(50) NOT NULL COMMENT "学生名字",
`class` INT COMMENT "学生所在班级",
`age` SMALLINT COMMENT "学生年龄",
`sex` TINYINT COMMENT "学生性别",
`phone` LARGEINT COMMENT "学生电话",
`address` VARCHAR(50) NOT NULL COMMENT "学生家庭地址",
`date` DATETIME NOT NULL COMMENT "数据录入时间"
)
ENGINE=olap
DUPLICATE KEY (`sid`,`name`)
DISTRIBUTED BY HASH (`sid`) BUCKETS 4
PROPERTIES
(
"replication_num"="1"
);
--data
1,xxxxxxxxxxxxxxxxxxxxxxx,1001,18,1,1008610010,beijing,2024-04-26,test_column
Streamload:
curl --location-trusted -u root -H "column_separator:," -T /mnt/disk2/liyuanyuan/data/test2.csv http://10.16.10.6:18739/api/test/test2/_stream_load
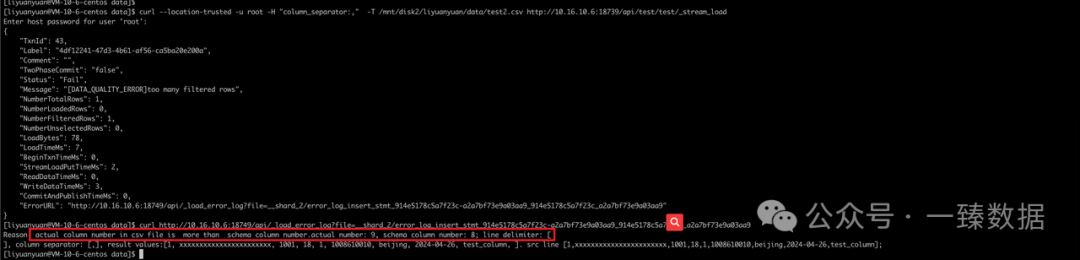
ERROR:
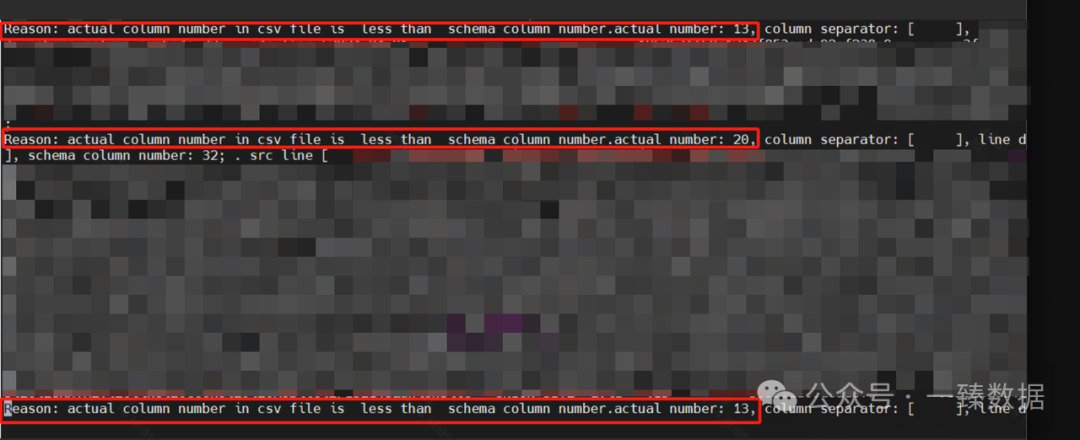
Reason: actual column number in csv file is more than schema column number.actual number: 9, schema column number: 8; line delimiter: [
], column separator: [,], result values:[1, xxxxxxxxxxxxxxxxxxxxxxx, 1001, 18, 1, 1008610010, beijing, 2024-04-26, test_column, ]. src line [1,xxxxxxxxxxxxxxxxxxxxxxx,1001,18,1,1008610010,beijing,2024-04-26,test_column];
处理方式,参考:
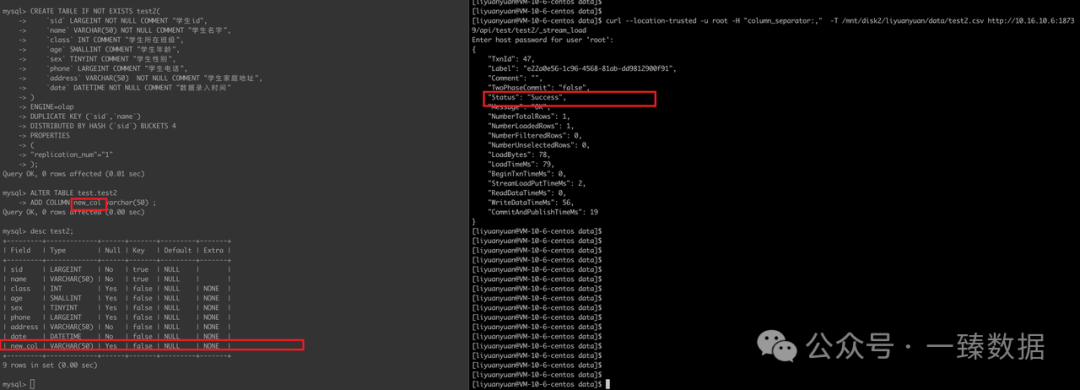
ALTER-TABLE-COLUMN - Apache Doris-- 添加列
ALTER TABLE test.test2 ADD COLUMN new_col varchar(50) ;
导入成功:
4.csv中含有特殊字符导入失败
比如:flink/spark to doris 使用csv举例子:以下图为例子,有时候在进行数据同步的时候会遇到一些问题,比如 表schema 的字段是固定的32个,但是实际列数小于schema列数,甚至有可能是变动的,这种情况一般是数据中有分隔符导致的,可以考虑换成json格式。
Flink Flink Doris Connector - Apache Doris
Spark Spark Doris Connector - Apache Doris
properties.setProperty("format", "json");
properties.setProperty("read_json_by_line", "true");
含包围符数据导入
1. 包围符数据导入
Schema:
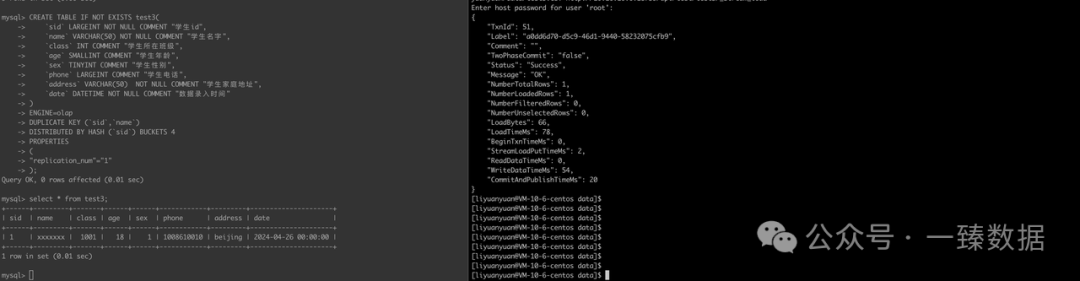
CREATE TABLE IF NOT EXISTS test3(
`sid` LARGEINT NOT NULL COMMENT "学生id",
`name` VARCHAR(50) NOT NULL COMMENT "学生名字",
`class` INT COMMENT "学生所在班级",
`age` SMALLINT COMMENT "学生年龄",
`sex` TINYINT COMMENT "学生性别",
`phone` LARGEINT COMMENT "学生电话",
`address` VARCHAR(50) NOT NULL COMMENT "学生家庭地址",
`date` DATETIME NOT NULL COMMENT "数据录入时间"
)
ENGINE=olap
DUPLICATE KEY (`sid`,`name`)
DISTRIBUTED BY HASH (`sid`) BUCKETS 4
PROPERTIES
(
"replication_num"="1"
);
--data
"1","xxxxxxx","1001","18","1","1008610010","beijing","2024-04-26"
Streamload:
curl --location-trusted -u root -H "column_separator:," -H "enclose:\"" -H "trim_double_quotes:true" -T /mnt/disk2/liyuanyuan/data/test3.csv http://10.16.10.6:18739/api/test/test3/_stream_load
参考Streamload Stream Load - Apache Doris:
enclose:指定包围符。
trim_double_quotes:为 true 时裁剪掉 CSV 文件每个字段最外层的双引号。
处理方式:
2. 部分数据有包围符
Schema:
CREATE TABLE IF NOT EXISTS test4(
`sid` LARGEINT NOT NULL COMMENT "学生id",
`name` VARCHAR(50) NOT NULL COMMENT "学生名字",
`class` INT COMMENT "学生所在班级",
`age` SMALLINT COMMENT "学生年龄",
`sex` TINYINT COMMENT "学生性别",
`phone` LARGEINT COMMENT "学生电话",
`address` VARCHAR(50) NOT NULL COMMENT "学生家庭地址",
`date` DATETIME NOT NULL COMMENT "数据录入时间"
)
ENGINE=olap
DUPLICATE KEY (`sid`,`name`)
DISTRIBUTED BY HASH (`sid`) BUCKETS 4
PROPERTIES
(
"replication_num"="1"
);
--data 部分数据有包围符,包围符中的数据有和列分隔符相同的分隔符
"1","xx,x,x,xxx",1001,18,"1",1008610010,"bei,jing",2024-04-26
Streamload:
curl --location-trusted -u root -H "column_separator:," -H "enclose:\"" -H "trim_double_quotes:true" -T /mnt/disk2/liyuanyuan/data/test4.csv http://10.16.10.6:18739/api/test/test4/_stream_load
处理方式参考:Streamload Stream Load - Apache Doris:
enclose:指定包围符。
trim_double_quotes:为 true 时裁剪掉 CSV 文件每个字段最外层的双引号。
列名含有特殊字符
Schema:
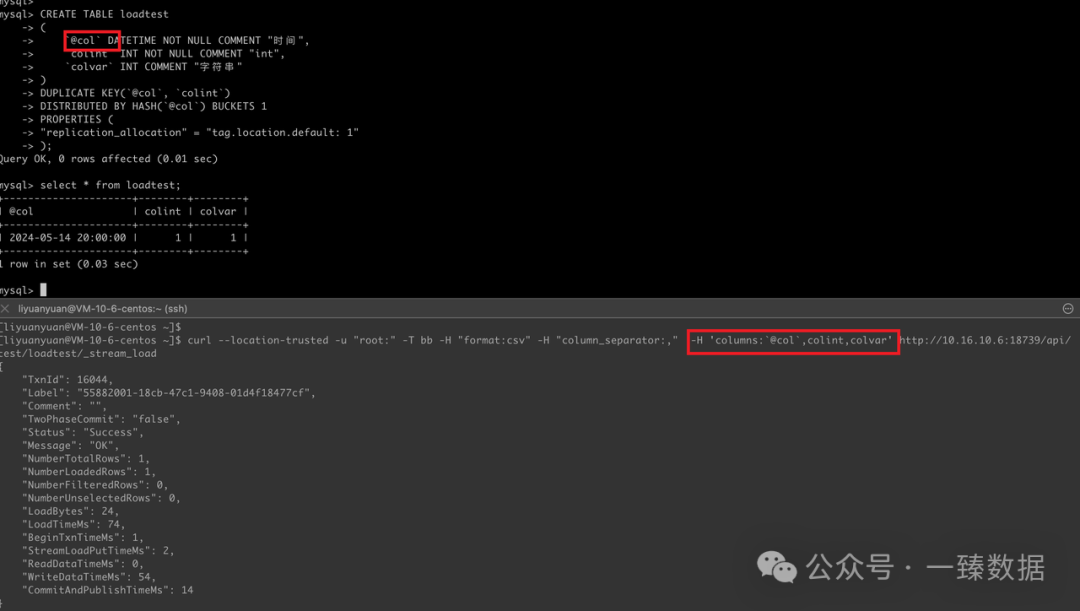
CREATE TABLE loadtest
(
`@col` DATETIME NOT NULL COMMENT "时间",
`colint` INT NOT NULL COMMENT "int",
`colvar` INT COMMENT "字符串"
)
DUPLICATE KEY(`@col`, `colint`)
DISTRIBUTED BY HASH(`@col`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1");data:2024-05-14 20:00:00,1,1
Streamload:
curl --location-trusted -u "root:" -T bb -H "format:csv" -H "column_separator:," -H 'columns:`@col`,colint,colvar' http://10.16.10.x:18739/api/test/loadtest/_stream_load
说明:
需要将 -H "columns:@coltime,colint,colvar" 改成单引号 + 反引号就可以,因为双引号 curl 会转译
Windows 换行符问题
如果导入windows 数据后查询有问题,出现类似 select * from table where col = "xxx" 查不到数据,但实际上 col字段 xxx 数据是存在的,这种情况就要考虑是否是因为最后一列多出了 \r 。
排查方式:
od -c test_data.csv 查看是否有\r\n 存在

处理方式:
导入数据时候指定换行符为 \r\n:-H "line_delimiter:\r\n"
Streamload 表达式写法
Demo 1:
Schema:
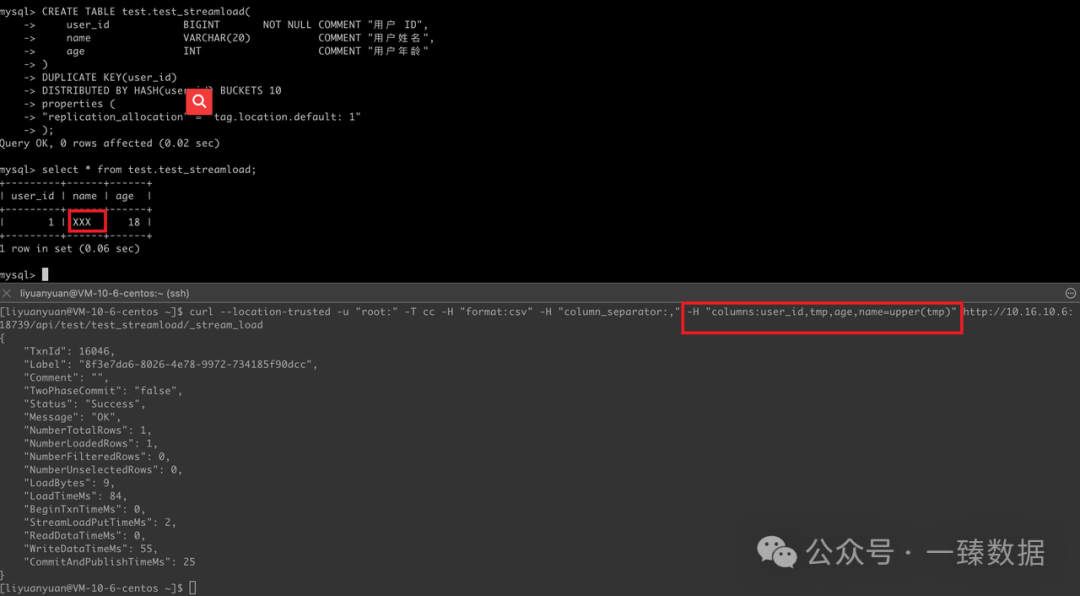
CREATE TABLE test.test_streamload(
user_id BIGINT NOT NULL COMMENT "用户 ID",
name VARCHAR(20) COMMENT "用户姓名",
age INT COMMENT "用户年龄"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10
properties (
"replication_allocation" = "tag.location.default: 1"
);
-- data:1,xxx,18
Streamload:
curl --location-trusted -u "root:" -T aa -H "format:csv" -H "column_separator:," -H "columns:user_id,tmp,age,name=upper(tmp)" http://10.16.10.6:18739/api/test/loadtest/_stream_load
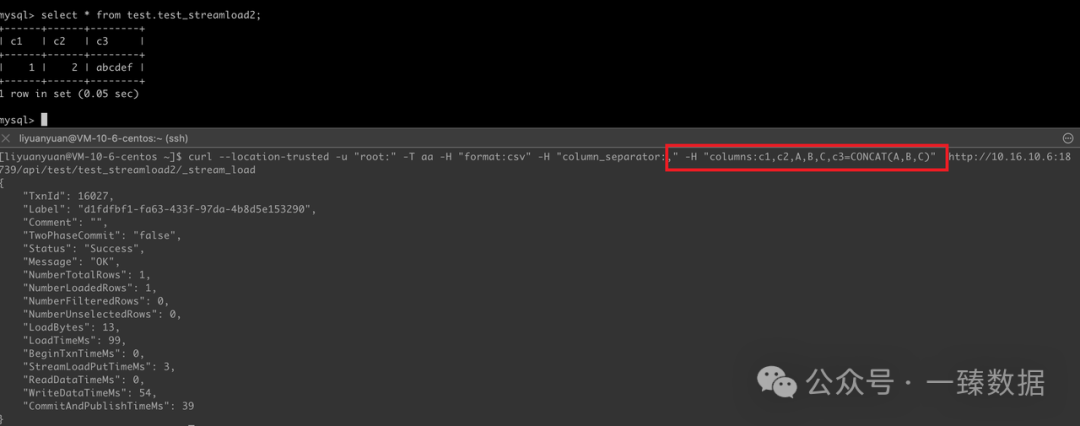
Demo2 :
Schema:
CREATE TABLE test.test_streamload2(
c1 INT,
c2 INT,
c3 VARCHAR(20)
)
DUPLICATE KEY(c1)
DISTRIBUTED BY HASH(c1) BUCKETS 10
properties (
"replication_allocation" = "tag.location.default: 1"
);
-- data:1,2,ab,cd,ef
Streamload:
curl --location-trusted -u "root:" -T aa -H "format:csv" -H "column_separator:," -H "columns:c1,c2,A,B,C,c3=CONCAT(A,B,C)" http://127.0.0.1:8030/api/test/test_streamload2/_stream_load

一臻数据致力于大数据AI时代的前沿内容分享,会持续分享更多有趣有用有态度的知识。同时也欢迎大家投稿,共建共进,帮助圈友们冲破认知壁垒,实现自我提升!
另外,一臻整理了一份《Apache Doris知识库》,其中包含 Apache Doris 学习资料、方案中心、企业实践 和 问题指南 等内容,会持续更新,欢迎关注公众号,免费领取。
资料获取 🔗 欢迎扫描下方二维码图片 加入【Apache Doris社区】免费领取❗️

往期推荐

点击下方蓝字关注一臻数据
