




引言
从用户的角度看 IN 查询有以下优点:
- 简单易懂:IN 查询语句简单直观,易于理解和编写。
- 效率高:在处理一组离散的数值时,IN 查询比多次使用 OR 查询效率更高。
但在使用 IN 查询时, 经常会遇到查询的性能问题. IN 表达式的参数列表一旦超过某个阈值, 数据库的处理效率会很容易急剧下降.
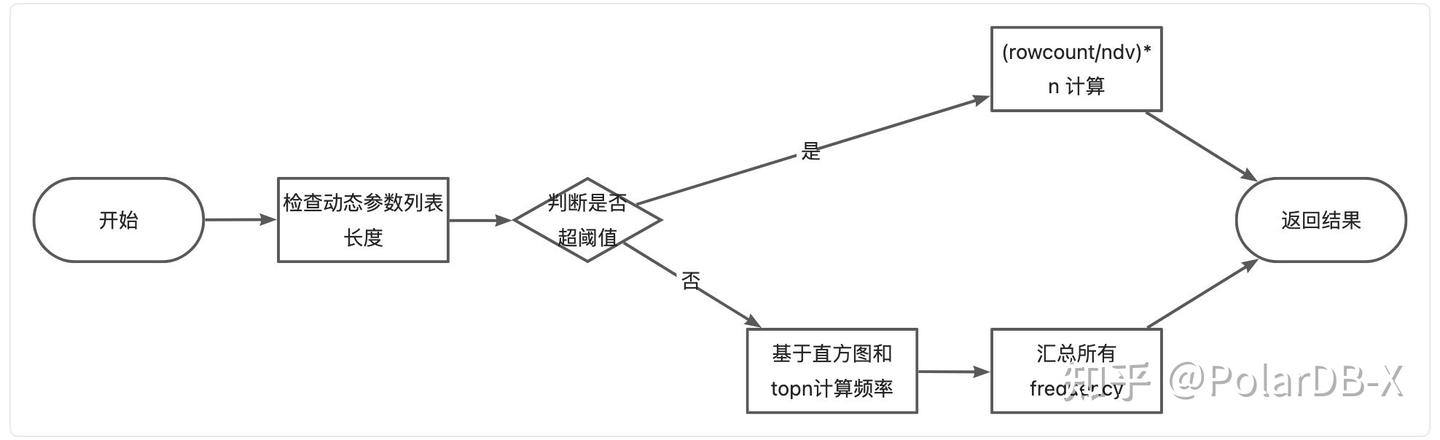
从数据库的角度来看, IN 查询最大的挑战在于动态参数列表带来的不稳定性.例如对 MySql 实例,超量的 IN 参数列表会基于 range_optimizer_max_mem_size 来判断是否要切换为全表扫描. 一旦超过阈值, 性能会急剧下降.
对于 PolarDB-X 及其它分布式在线业务数据库, IN 查询还会带来以下挑战:
- 优化器计算 Cost 时, 大量参数会带来额外的 Cost 计算开销
- IN 的动态参数列表会产生大量不同的 SQL 模板, 很容易占满执行计划缓存
- 大量 IN 参数在分布式场景需要通过预计算裁剪掉一部分, 从而避免对 DN 产生不必要的计算开销
注意:本文讲的 IN 查询不包含 IN 子查询
受篇幅所限, 本篇文章主要介绍 Polardb-X 在 IN 查询执行计划管理/执行方面的优化
IN 查询与执行计划管理
不同的数据库有各种各样的执行计划管理策略.PolarDB-X 的执行计划分类与 PostgreSql 中相似, 也分为 custom plan 与 generic plan 两种.
A prepared statement can be executed with either a generic plan or a custom plan. A generic plan is the same across all executions, while a custom plan is generated for a specific execution using the parameter values given in that call. Use of a generic plan avoids planning overhead, but in some situations a custom plan will be much more efficient to execute because the planner can make use of knowledge of the parameter values. (Of course, if the prepared statement has no parameters, then this is moot and a generic plan is always used.) prepared statement 可以通过 generic plan 或 custom plan 来执行。generic plan 对所有执行都相同,而 custom plan 则是针对特定执行使用该调用中给出的参数值生成的。使用 generic plan 可以避免规划开销,但在某些情况下,由于规划器可以利用对参数值的了解,custom plan 的执行效率会高得多。 (当然,如果 prepared statement 没有参数,那么这一点就无关紧要了,总是会使用 generic plan 。) -- 翻译自阿里大模型, 引自 postgresql 文档: https://www.postgresql.org/docs/current/sql-prepare.html
但是在执行计划的缓存策略上, PolarDB-X 的客户中, 有许多在线业务使用了较复杂的 SQL 模板, 另一方面, 数据被各种策略拆分到集群的不同分区, 更是大大加剧了优化器的优化挑战. 因此与 PostgreSQL 较为保守的执行计划管理策略不同, PolarDB-X 会倾向于尽量复用缓存执行计划, 从而避免较高的优化器开销.
那么 IN 表达式的参数列表就带来了一个非常大的挑战, 不同的参数列表指向不同的执行计划, 那计划缓存就很容易打满. 尤其是即席查询场景下, 不同的 IN 查询参数列表很容易产生大量的 SQL 模板.
SELECT order_info FROM orders WHERE item_id IN(?) AND seller_id IN(?) ORDERY BY gmt;用上面一个简单的订单查询请求来说, 如果 item_id 和 seller_id 各有10个, 那么该 SQL 最多可以产生 100 个 SQL 模板.而这100个 SQL 模板的执行计划是完全相似的.
为了收敛这些执行计划的数量, PolarDB-X 的 Parser 针对 IN 表达式的参数列表做了封装, 不管 IN 表达式中有多少个动态参数, 都被封装在 RawString 对象中.在优化器中, 针对 RawString 的参数列表作了 Cost 计算适配. 在执行器中, IN 表达式参数列表打包发送给 DN 计算.
这样做的好处是 IN 查询的 SQL 模板都可以收敛为一个执行计划, 大大缓解了执行计划的缓存压力.现在 PolarDB-X 可以支持高并发 IN 查询的动态随机访问.
功能展示
PolarDB-X 中可以通过 PlanCache 和 spm 视图来观察执行计划的缓存情况, 这里我们通过 PlanCache 来演示.
先购买一个PolarDB-X 2.0实例, 通过以下SQL创建环境:
// 创建好 DB 与 表
CREATE DATABASE test MODE=AUTO;
use test
CREATE TABLE tb_h(
id bigint not null auto_increment,
bid int,
name varchar(30),
birthday datetime not null,
primary key(id)
)
PARTITION BY HASH(id)
PARTITIONS 8;首先执行以下 SQL:
select * from tb_h where id in(1,2,3,4,5);
然后通过 plan_cache 视图观察计划的缓存情况:
mysql> select * from information_schema.plan_cache where `sql` like '%tb_h%' limit 10\G
*************************** 1. row ***************************
COMPUTE_NODE: 10.2.100.161:3021
SCHEMA_NAME: test
TABLE_NAMES: tb_h
ID: 1d4daf02
HIT_COUNT: 0
SQL: SELECT *
FROM tb_h
WHERE id IN (?)
TYPE_DIGEST: 1926227933676693664
PLAN:
Gather
LogicalView(tableNames=[[tb_h]])
PARAMETER: [[1,2,3,4,5]]
1 row in set (0.01 sec)从视图中可以看到, IN 表达式的动态参数列表被缩减为一个?
如果 SQL 模板其它地方没有变化, 不过执行多少次不同 IN 参数列表的查询, 都会复用相同的执行计划.
mysql> explain select * from tb_h where id in(4566);
+----------------------------------------------------------------------------------------------------------------------------------------------+
| LOGICAL EXECUTIONPLAN |
+----------------------------------------------------------------------------------------------------------------------------------------------+
| Gather(concurrent=true) |
| LogicalView(tables="tb_h[p8]", sql="SELECT `id`, `bid`, `name`, `birthday` FROM `tb_h` AS `tb_h` FORCE INDEX(PRIMARY) WHERE (`id` IN(?))") |
| HitCache:true |
| Source:PLAN_CACHE |
| TemplateId: 1d4daf02 |
+----------------------------------------------------------------------------------------------------------------------------------------------+
5 rows in set (0.00 sec)
mysql> explain select * from tb_h where id in(45, 66);
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| LOGICAL EXECUTIONPLAN |
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Gather(concurrent=true) |
| LogicalView(tables="tb_h[p2,p7]", shardCount=2, sql="SELECT `id`, `bid`, `name`, `birthday` FROM `tb_h` AS `tb_h` FORCE INDEX(PRIMARY) WHERE (`id` IN(?))", pruningInfo="all size:2*2(part), pruning size:2") |
| HitCache:true |
| Source:PLAN_CACHE |
| TemplateId: 1d4daf02 |
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
5 rows in set (0.00 sec)可以看到命中计划缓存的 TemplateId 都是同一个 1d4daf02
细心的朋友可能会发现, 对于超过1个的 IN 参数请求, EXPLAIN 的信息中会带有 pruningInfo 信息, 并且相同计划的不同参数, 展示的 pruningInfo 信息也不同。
这是 PolarDB-X 为了优化 IN 查询参数过多带来的计算开销, 而在 CN 节点进行的预裁剪优化
IN 查询与预裁剪
分布式数据库将数据基于特征进行拆分, 那么对于过多的 IN 表达式列表, 如果可以基于拆分特征进行预裁剪, 将会大大减少各个 DN 上处理的参数数量。
首先我们基于关系代数论证下裁剪的合法性:
当拆分表达式中包含 IN 表达式时, 如果先将 IN 表达式看作一个整体不展开,基于布尔转换律,所有的表达式都可以转换为析取范式 DNF。
在这个前提下, 每个合取子句中将包含!, AND, IN 和其它表达式.下面将基于这个结构讨论 IN 表达式中每个参数对整个表达式的影响.
对于每个合取子句, IN与其它表达式一定是 AND 关系. 那么根据分配律可以将 IN 表达式中各项参数分别展开:
E AND Col IN(P1, P2, P3...,Pn)转化为
(E AND Col = P1) OR
(E AND Col = P2) OR
(E AND Col = P3) OR
...
(E AND Col = Pn) ORE 为其它与拆分有关的表达式.
分配律 p∧(q∨r)≡(p∧q)∨(p∧r)假设整体表达式计算后的分片集合为 K, 每个 Pn 子句计算得到的分片集合为 Kn, 那么根据 OR 的关系, 易得
K=K1 ∪ K2 ∪ K3 ∪ ... ∪ Kn通过Kn分别计算再取并集K, 这一过程中如果记录一下各个 Pn 对应的分片
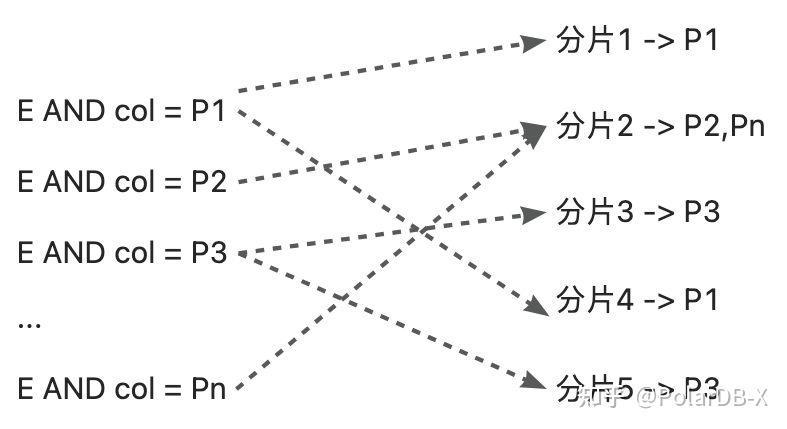
此时,就得到了当前合取子句下每个分片及其对应的参数列表
对于每一个合取子句,我们都可以得到分片与IN参数列表的关系集合。由于合取子句间是 OR 的关系, 我们可以将这些集合基于各个分片分别 Merge 起来,从而得到最终的分片与参数列表关系,此时参数列表也自然完成了裁剪。
!与IN在合取子句中会组合成 NOT IN, NOT IN 会计算为全表扫描.
如果涉及多个 IN 表达式, 我们需要考虑笛卡尔积数量的每一种组合.如果笛卡尔积的数量过于庞大, 会导致这一计算过程过于冗长.因此作了以下策略优化:
- 设定最大计算次数, 从最长的 IN 表达式依次纳入笛卡尔积计算, 中途如果超出了最大计算次数, 则将剩余的 IN 表达式看做一个整体, 不再对其裁剪.
- 如果单次计算会覆盖所有分片, 则认为该表达式不具备分片裁剪能力, 直接退出裁剪
功能展示
//建表
CREATE TABLE `hash_tbl_todays_AutoPruning` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`bid` int(11) DEFAULT NULL,
`name` varchar(30) DEFAULT NULL,
`birthday` datetime NOT NULL,
PRIMARY KEY (`id`),
KEY `auto_shard_key_birthday` USING BTREE (`birthday`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4
PARTITION BY HASH(TO_DAYS(`birthday`))
PARTITIONS 8 ;
// 将 EXPLAIN_PRUNING_DETAIL 开关打开便于观察 IN 裁剪的效果
SET GLOBAL EXPLAIN_PRUNING_DETAIL=TRUE;裁剪信息说明
mysql> explain select * from hash_tbl_todays_AutoPruning where birthday in ('2024-09-08', '2024-09-10', '2024-10-08', '2023-12-30') and bid>100;
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| LOGICAL EXECUTIONPLAN |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Gather(concurrent=true) |
| LogicalView(tables="hash_tbl_todays_AutoPruning[p1,p4,p7]", shardCount=3, sql="SELECT `id`, `bid`, `name`, `birthday` FROM `hash_tbl_todays_AutoPruning` AS `hash_tbl_todays_AutoPruning` WHERE ((`birthday` IN(?)) AND (`bid` > ?))", pruningInfo="all size:4*3(part), pruning size:8, pruning time:0ms, pruning detail:(TEST_P00000_GROUP, [hash_tbl_todays_AutoPruning_dn1M_00006])->(PruneRaw('2024-09-10'));(TEST_P00000_GROUP, [hash_tbl_todays_AutoPruning_dn1M_00000])->(PruneRaw('2023-12-30'));(TEST_P00001_GROUP, [hash_tbl_todays_AutoPruning_dn1M_00003])->(PruneRaw('2024-09-08','2024-10-08'))") |
| HitCache:true |
| Source:PLAN_CACHE |
| TemplateId: f36182f0 |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
5 rows in set (0.00 sec)在 pruningInfo 中可以看到 IN 裁剪的细节信息:
all size:4*3(part),
pruning size:8,
pruning time:0ms,
pruning detail:(TEST_P00000_GROUP, [hash_tbl_todays_AutoPruning_dn1M_00006])->(PruneRaw('2024-09-10'));(TEST_P00000_GROUP, [hash_tbl_todays_AutoPruning_dn1M_00000])->(PruneRaw('2023-12-30'));(TEST_P00001_GROUP, [hash_tbl_todays_AutoPruning_dn1M_00003])->(PruneRaw('2024-09-08','2024-10-08')- all size: 代表如果不裁剪, 将会推给 DN 计算节点的 IN 参数列表总数(在当前 case 中, IN 表达式中有4个参数, , 表共有8个分片,在本次请求中涉及3个分片,所以它的总下推数量是4*3=12)
- pruning size:代表 IN 裁剪裁掉的参数数量. 在裁剪后, 各个参数只会发往自己相关的分片, 因此裁剪后的数量与 IN 表达式参数的数量一致
- pruning time:裁剪消耗的时间
- pruning detail:具体的裁剪信息, 其中包括分片名, 分表名, 裁剪后的 IN 参数列表
多列 IN 裁剪
对于 (a, b) in ((xx, xx), (yy, yy)) 的多列 IN 表达式也可以支持裁剪.
mysql> explain select * from hash_tbl_todays_AutoPruning where (name, birthday) in (('xiaoli', '2024-09-08'), ('ming', '2024-09-10'), ('xiaoT', '2024-10-08'), ('yi', '2023-12-30')) and bid>100;
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| LOGICAL EXECUTIONPLAN |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Gather(concurrent=true) |
| LogicalView(tables="hash_tbl_todays_AutoPruning[p1,p4,p7]", shardCount=3, sql="SELECT `id`, `bid`, `name`, `birthday` FROM `hash_tbl_todays_AutoPruning` AS `hash_tbl_todays_AutoPruning` WHERE ((((`name`, `birthday`)) IN(?)) AND (`bid` > ?))", pruningInfo="all size:4*3(part), pruning size:8, pruning time:0ms, pruning detail:(TEST_P00000_GROUP, [hash_tbl_todays_AutoPruning_dn1M_00006])->(PruneRaw(('ming','2024-09-10')));(TEST_P00000_GROUP, [hash_tbl_todays_AutoPruning_dn1M_00000])->(PruneRaw(('yi','2023-12-30')));(TEST_P00001_GROUP, [hash_tbl_todays_AutoPruning_dn1M_00003])->(PruneRaw(('xiaoli','2024-09-08'),('xiaoT','2024-10-08')))") |
| HitCache:true |
| Source:PLAN_CACHE |
| TemplateId: ce4cba38 |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
5 rows in set (0.00 sec)多个 IN 表达式裁剪
对于多级拆分表, 不同级间使用不同的列拆分.此时如果业务需要对多列同时进行 IN 查询的话, 也可以进行裁剪.
多个 IN 表达式的话, PolarDB-X 会针对所有 IN 参数进行笛卡尔遍历裁剪.如下图所示:
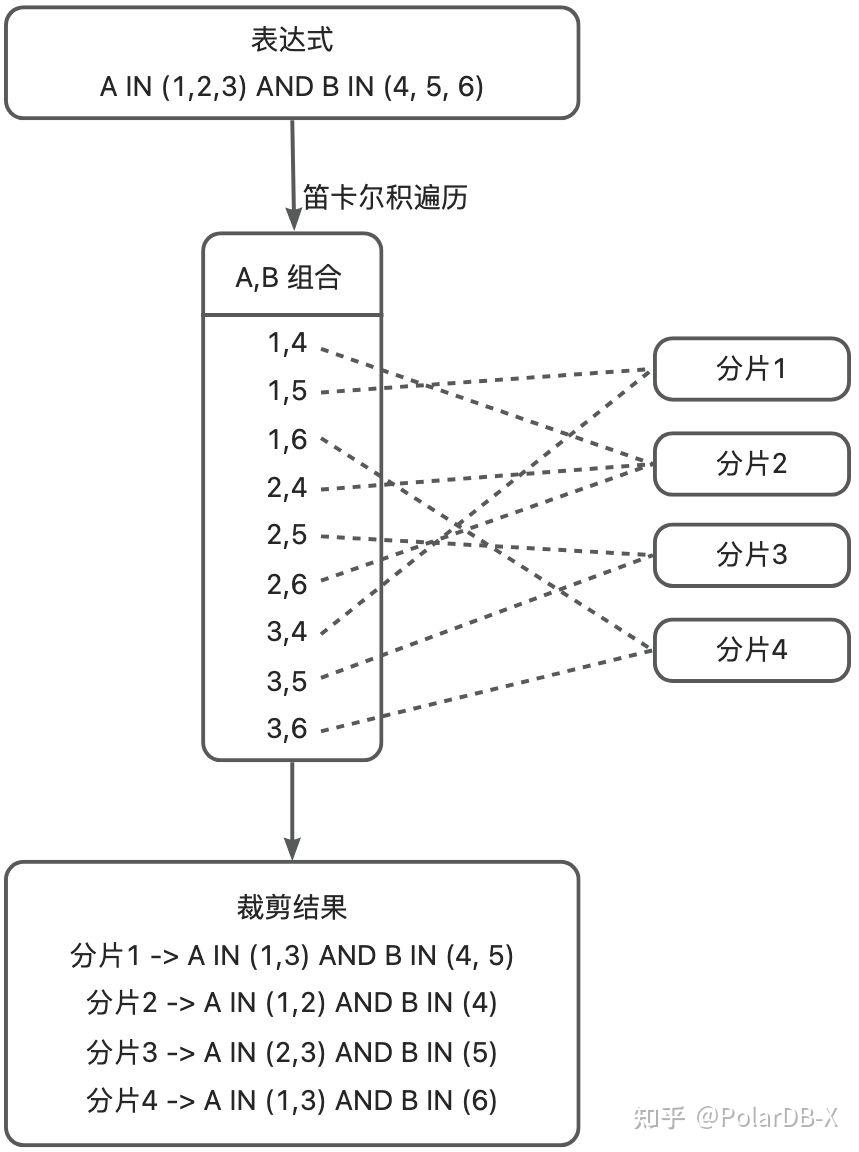
在 PolarDB-X 实例上, 我们首先尝试创建一张二级分区表, 再对多 IN 表达式的 SQL explain 看一下结果:
CREATE TABLE tb_k_k_tp(
id bigint not null auto_increment,
bid int,
name varchar(30),
birthday datetime not null,
primary key(id)
)
PARTITION BY KEY(bid)
PARTITIONS 2
SUBPARTITION BY KEY(id)
SUBPARTITIONS 4;
mysql> explain select * from tb_k_k_tp where bid in (1,2,3,4,5,6,7,8,9,10) and id in (11,12,13,14,15,16);
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| LOGICAL EXECUTIONPLAN |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Gather(concurrent=true) |
| LogicalView(tables="tb_k_k_tp[p1sp1,p1sp2,p1sp3,p1sp4,p2sp1,p2sp2,p2sp3,p2sp4]", shardCount=8, sql="SELECT `id`, `bid`, `name`, `birthday` FROM `tb_k_k_tp` AS `tb_k_k_tp` FORCE INDEX(PRIMARY) WHERE((`id` IN(?)) AND (`bid` IN(?)))", pruningInfo="all size:16*8(part), pruning size:76, pruning time:1ms, pruning detail:(TEST_P00000_GROUP, [tb_k_k_tp_UyWm_00004])->(PruneRaw(1,4,7,8,9,10),PruneRaw(11,12));(TEST_P00001_GROUP, [tb_k_k_tp_UyWm_00005])->(PruneRaw(1,4,7,8,9,10),PruneRaw(13,16));(TEST_P00000_GROUP, [tb_k_k_tp_UyWm_00006])->(PruneRaw(1,4,7,8,9,10),PruneRaw(14));(TEST_P00001_GROUP, [tb_k_k_tp_UyWm_00007])->(PruneRaw(1,4,7,8,9,10),PruneRaw(15));(TEST_P00000_GROUP, [tb_k_k_tp_UyWm_00000])->(PruneRaw(2,3,5,6),PruneRaw(11,12));(TEST_P00000_GROUP, [tb_k_k_tp_UyWm_00002])->(PruneRaw(2,3,5,6),PruneRaw(14));(TEST_P00001_GROUP, [tb_k_k_tp_UyWm_00003])->(PruneRaw(2,3,5,6),PruneRaw(15));(TEST_P00001_GROUP, [tb_k_k_tp_UyWm_00001])->(PruneRaw(2,3,5,6),PruneRaw(13,16))") |
| HitCache:true |
| Source:PLAN_CACHE |
| TemplateId: f70bd95a |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
5 rows in set (0.00 sec)由 EXPLAIN 中 pruning detail 的信息可以看到, 原本要发到8个分片, 每个分片会下发16个参数, DN 共要处理 16*8=128个参数值, 裁剪后只剩 128-76=52 个参数需要处理.
性能测试
测试环境:
polardbx 8C32G
sysbench IN value 测试
SELECT c FROM sbtest1 WHERE id in (?)5个IN值, AUTO 表, 400并发, id 是主键和拆分键, 64个分表
| QPS | CN CPU | DN CPU | DN IOPS | |
| 裁剪 | 20031.74 | 100% | 53% | 10% |
| 不裁剪 | 21322.80 | 100% | 85% | 47% |
50个 IN 值, AUTO 表, 400并发, id 是主键和拆分键, 64个分表
| QPS | CN CPU | DN CPU | DN IOPS | |
| 裁剪 | 7424.55 | 100% | 100% | 36% |
| 不裁剪 | 639.39 | 20% | 74% | 100% |
在查询时, IN 裁剪的本质是通过在 CN 预计算分区, 避免 DN 上面冗余的计算开销. 通过 sysbench IN 查询压力测试的场景来看, IN 裁剪可以大大的降低 DN 的 CPU 开销, 从而提供更大的集群容量.
- IN 数量较小时(5个左右), 由于 CN CPU 最先成为瓶颈, 导致目前不做裁剪 QPS 比裁剪略高,但同时对 DN 的 cpu 和 io 压力会远远高于不做裁剪
- IN 数量增加时, 不做裁剪会给 DN 大量的 cpu 和 IO 压力, 从而导致QPS远远不及裁剪
正确性证明


总结
在涉及大量条件值或是在复杂的分布式环境中,SQL语句中的IN 查询以其简便性和潜在的高效性受到欢迎,但其也存在一些固有的局限性,通过持续的技术优化实践中, PolarDB-X 探索了以下可以有效优化 IN 查询的主要技术手段.包括但不限于:
- 优化 Cost 计算机制:针对含有大量参数的 IN 查询,调整成本评估算法,旨在更准确地预测资源消耗,从而选择更加合理的执行路径。
- 智能管理执行计划缓存:通过对 parser、优化器、执行器的全方位改造, 使得查询引擎具备控制 IN 参数产生的冗余 SQL 模板数量,确保不会因计划缓存溢出而影响整体性能。
- 增强分布式处理能力:利用高效的预处理技术识别和移除不必要的 IN 参数项,减轻各 DN 数据节点的工作负荷;加快整个查询过程的速度及数据库的整体性能表现。
在今后的实践中,我们也会继续探索和分享一些有价值的数据库引擎优化技术。
