




Hi~朋友,关注置顶防止错过消息
Promethues是开源的监控和告警工具,可以用来收集各个数据源的度量数据,在我们整个Kubernetes集群中,我们同样采用Promethues作为我们的监控工具。
什么是Prometheus Operator
Prometheus Operator是用来简化Prometheus及其相关组件在Kubernetes集群中部署和管理的工具。
Operator可以通过CRD来管理Prometheus的实现,无需手动创建和配置各个组件,Prometheus Operator中的CRD主要由以下构成:
Prometheus:定义Prometheus的部署
Alertmanager:定义AlertManager的部署
ThanosRuler:定义所需的ThanosRuler部署,用于在多个Prometheus数据源上进行规则评估,实现集中式告警解决方案
ServiceMonitor:声明性地指定如何监控一组Kubernetes Service,简化了Kubernetes服务过程,无须手动维护Prometheus配置文件
PodMonitor:声明性地指定如何监控一组Pod,用于直接监控不属于特定服务的Pod
Probe:声明性地指定如何监控一组Ingress或静态目标,用于监控外部端点或与Kubernetes服务不直接相关的网络路径
PrometheusRule:定义一组Prometheus的告警规则
AlertmanagerConfig:声明性地指定Alertmanager配置的子部分,允许定义自定义的告警路由、抑制规则和接收器配置,以实现精细的告警管理
Prometheus Operator安装
独立安装,可以参考Github文档进行安装
集成安装,由于我们使用了Kubersphere作为我们Kubernetes集群的管理平台,Kubersphere默认会安装Prometheus Operator
如何监控Kafka
对于如何监控Kafka并实现预警我们需要做以下工作:
对于Kafka CRD我们需要使用JMX Prometheus Exporter进行指标导出:
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: business-kafka
annotations:
strimzi.io/node-pools: enabled
strimzi.io/kraft: enabled
spec:
kafka:
version: 3.8.0
metadataVersion: 3.8-IV0
....
metricsConfig:
type: jmxPrometheusExporter
valueFrom:
configMapKeyRef:
name: kafka-metrics
key: kafka-metrics-config.yml
JMX Prometheus Exporter用于将Kafka的JMX 指标导出为Prometheus可以抓取的格式。这允许您通过Prometheus来监控Kafka的性能指标,如请求速率、延迟、错误率等,jmx的配置文件来自于以下ConfigMap:
kind: ConfigMap
apiVersion: v1
metadata:
name: kafka-metrics
namespace: kafka
labels:
app: strimzi
data:
kafka-metrics-config.yml: |
lowercaseOutputName: true
rules:
# Special cases and very specific rules
- pattern: kafka.server<type=(.+), name=(.+), clientId=(.+), topic=(.+), partition=(.*)><>Value
name: kafka_server_$1_$2
type: GAUGE
labels:
clientId: "$3"
topic: "$4"
partition: "$5"
- pattern: kafka.server<type=(.+), name=(.+), clientId=(.+), brokerHost=(.+), brokerPort=(.+)><>Value
name: kafka_server_$1_$2
type: GAUGE
labels:
clientId: "$3"
broker: "$4:$5"
- pattern: kafka.server<type=(.+), cipher=(.+), protocol=(.+), listener=(.+), networkProcessor=(.+)><>connections
name: kafka_server_$1_connections_tls_info
type: GAUGE
labels:
cipher: "$2"
protocol: "$3"
listener: "$4"
networkProcessor: "$5"
- pattern: kafka.server<type=(.+), clientSoftwareName=(.+), clientSoftwareVersion=(.+), listener=(.+), networkProcessor=(.+)><>connections
name: kafka_server_$1_connections_software
type: GAUGE
labels:
clientSoftwareName: "$2"
clientSoftwareVersion: "$3"
listener: "$4"
networkProcessor: "$5"
- pattern: "kafka.server<type=(.+), listener=(.+), networkProcessor=(.+)><>(.+-total):"
name: kafka_server_$1_$4
type: COUNTER
labels:
listener: "$2"
networkProcessor: "$3"
- pattern: "kafka.server<type=(.+), listener=(.+), networkProcessor=(.+)><>(.+):"
name: kafka_server_$1_$4
type: GAUGE
labels:
listener: "$2"
networkProcessor: "$3"
- pattern: kafka.server<type=(.+), listener=(.+), networkProcessor=(.+)><>(.+-total)
name: kafka_server_$1_$4
type: COUNTER
labels:
listener: "$2"
networkProcessor: "$3"
- pattern: kafka.server<type=(.+), listener=(.+), networkProcessor=(.+)><>(.+)
name: kafka_server_$1_$4
type: GAUGE
labels:
listener: "$2"
networkProcessor: "$3"
# Some percent metrics use MeanRate attribute
# Ex) kafka.server<type=(KafkaRequestHandlerPool), name=(RequestHandlerAvgIdlePercent)><>MeanRate
- pattern: kafka.(\w+)<type=(.+), name=(.+)Percent\w*><>MeanRate
name: kafka_$1_$2_$3_percent
type: GAUGE
# Generic gauges for percents
- pattern: kafka.(\w+)<type=(.+), name=(.+)Percent\w*><>Value
name: kafka_$1_$2_$3_percent
type: GAUGE
- pattern: kafka.(\w+)<type=(.+), name=(.+)Percent\w*, (.+)=(.+)><>Value
name: kafka_$1_$2_$3_percent
type: GAUGE
labels:
"$4": "$5"
# Generic per-second counters with 0-2 key/value pairs
- pattern: kafka.(\w+)<type=(.+), name=(.+)PerSec\w*, (.+)=(.+), (.+)=(.+)><>Count
name: kafka_$1_$2_$3_total
type: COUNTER
labels:
"$4": "$5"
"$6": "$7"
- pattern: kafka.(\w+)<type=(.+), name=(.+)PerSec\w*, (.+)=(.+)><>Count
name: kafka_$1_$2_$3_total
type: COUNTER
labels:
"$4": "$5"
- pattern: kafka.(\w+)<type=(.+), name=(.+)PerSec\w*><>Count
name: kafka_$1_$2_$3_total
type: COUNTER
# Generic gauges with 0-2 key/value pairs
- pattern: kafka.(\w+)<type=(.+), name=(.+), (.+)=(.+), (.+)=(.+)><>Value
name: kafka_$1_$2_$3
type: GAUGE
labels:
"$4": "$5"
"$6": "$7"
- pattern: kafka.(\w+)<type=(.+), name=(.+), (.+)=(.+)><>Value
name: kafka_$1_$2_$3
type: GAUGE
labels:
"$4": "$5"
- pattern: kafka.(\w+)<type=(.+), name=(.+)><>Value
name: kafka_$1_$2_$3
type: GAUGE
# Emulate Prometheus 'Summary' metrics for the exported 'Histogram's.
# Note that these are missing the '_sum' metric!
- pattern: kafka.(\w+)<type=(.+), name=(.+), (.+)=(.+), (.+)=(.+)><>Count
name: kafka_$1_$2_$3_count
type: COUNTER
labels:
"$4": "$5"
"$6": "$7"
- pattern: kafka.(\w+)<type=(.+), name=(.+), (.+)=(.*), (.+)=(.+)><>(\d+)thPercentile
name: kafka_$1_$2_$3
type: GAUGE
labels:
"$4": "$5"
"$6": "$7"
quantile: "0.$8"
- pattern: kafka.(\w+)<type=(.+), name=(.+), (.+)=(.+)><>Count
name: kafka_$1_$2_$3_count
type: COUNTER
labels:
"$4": "$5"
- pattern: kafka.(\w+)<type=(.+), name=(.+), (.+)=(.*)><>(\d+)thPercentile
name: kafka_$1_$2_$3
type: GAUGE
labels:
"$4": "$5"
quantile: "0.$6"
- pattern: kafka.(\w+)<type=(.+), name=(.+)><>Count
name: kafka_$1_$2_$3_count
type: COUNTER
- pattern: kafka.(\w+)<type=(.+), name=(.+)><>(\d+)thPercentile
name: kafka_$1_$2_$3
type: GAUGE
labels:
quantile: "0.$4"
# KRaft overall related metrics
# distinguish between always increasing COUNTER (total and max) and variable GAUGE (all others) metrics
- pattern: "kafka.server<type=raft-metrics><>(.+-total|.+-max):"
name: kafka_server_raftmetrics_$1
type: COUNTER
- pattern: "kafka.server<type=raft-metrics><>(.+):"
name: kafka_server_raftmetrics_$1
type: GAUGE
# KRaft "low level" channels related metrics
# distinguish between always increasing COUNTER (total and max) and variable GAUGE (all others) metrics
- pattern: "kafka.server<type=raft-channel-metrics><>(.+-total|.+-max):"
name: kafka_server_raftchannelmetrics_$1
type: COUNTER
- pattern: "kafka.server<type=raft-channel-metrics><>(.+):"
name: kafka_server_raftchannelmetrics_$1
type: GAUGE
# Broker metrics related to fetching metadata topic records in KRaft mode
- pattern: "kafka.server<type=broker-metadata-metrics><>(.+):"
name: kafka_server_brokermetadatametrics_$1
type: GAUGE
2. 对于Kafka CRD我们还要部署Kafka Exporter,如下:
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: business-kafka
annotations:
strimzi.io/node-pools: enabled
strimzi.io/kraft: enabled
spec:
....
kafkaExporter:
groupRegex: ".*"
topicRegex: ".*"
resources:
requests:
cpu: 200m
memory: 64Mi
limits:
cpu: 500m
memory: 128Mi
logging: info
enableSaramaLogging: true
readinessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
livenessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
Kafka Exporter和JMX Prometheus Exporter 都是用于将Kafka指标暴露给Prometheus的工具,但它们的侧重点和作用有所不同:
Kafka Exporter专门用于监控Kafka消费者组的延迟(consumer lag)以及消费者的状态
JMX Prometheus Exporter用于通过JMX接口暴露Kafka进程中各种JVM级别的性能和Kafka内部状态指标。
3. 上述两个Exporter配置好以后,我们就可以使用 PodMonitor对指标进行收集写入Prometheus了:
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: kafka-resources-metrics
labels:
app: strimzi
spec:
selector:
matchExpressions:
- key: "strimzi.io/kind"
operator: In
values: ["Kafka", "KafkaConnect", "KafkaMirrorMaker", "KafkaMirrorMaker2"]
namespaceSelector:
matchNames:
- kafka
podMetricsEndpoints:
- path: /metrics
port: tcp-prometheus
relabelings:
- separator: ;
regex: __meta_kubernetes_pod_label_(strimzi_io_.+)
replacement: $1
action: labelmap
- sourceLabels: [__meta_kubernetes_namespace]
separator: ;
regex: (.*)
targetLabel: namespace
replacement: $1
action: replace
- sourceLabels: [__meta_kubernetes_pod_name]
separator: ;
regex: (.*)
targetLabel: kubernetes_pod_name
replacement: $1
action: replace
- sourceLabels: [__meta_kubernetes_pod_node_name]
separator: ;
regex: (.*)
targetLabel: node_name
replacement: $1
action: replace
- sourceLabels: [__meta_kubernetes_pod_host_ip]
separator: ;
regex: (.*)
targetLabel: node_ip
replacement: $1
action: replace
spec.selector.matchExpressions:指定了需要监控的Pod需要匹配的标签
spec.namespaceSelector:指定了监控的Namespace
spec.podMetricsEndpoints.path:Prometheus将访问/metrics路径来抓取指
spec.podMetricsEndpoints.port:指标抓取使用的端口
spec.podMetricsEndpoints.relabelings:用于修改和标准化指标标签
指标可视化
下面我们需要将Prometheus收集到的数据进行可视化,这里我们借助Grafana进行展示,我们主要建立 3个Dashboard:
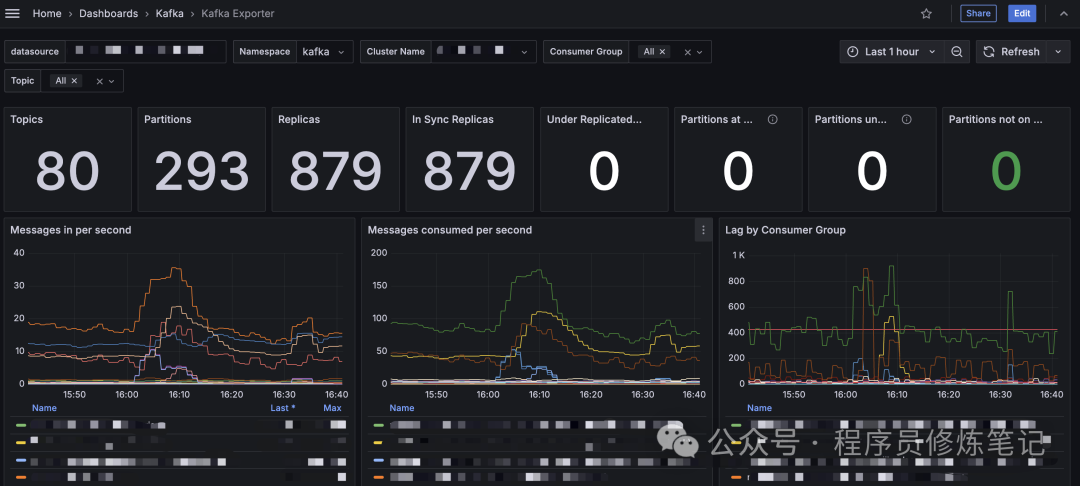
Kafka Exporter的Dashboard如下图所示:
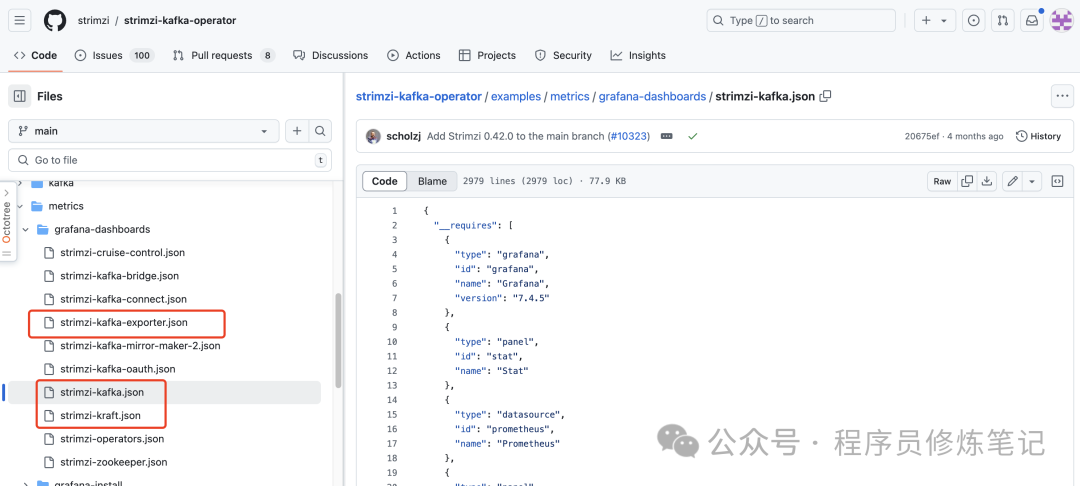
这三个模板的配置文件我们可以从strimzi/strimzi-kafka-operator的github 中找到,如下图:
添加PromtheusRule规则
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: k8s
role: alert-rules
name: kafka-prometheus-rules
namespace: kafka
spec:
groups:
- name: kafka
rules:
- alert: KafkaRunningOutOfSpace
expr: kubelet_volume_stats_available_bytes{persistentvolumeclaim=~"data(-[0-9]+)?-(.+)-kafka-[0-9]+"} * 100 / kubelet_volume_stats_capacity_bytes{persistentvolumeclaim=~"data(-[0-9]+)?-(.+)-kafka-[0-9]+"} < 15
for: 10s
labels:
severity: warning
annotations:
summary: 'Kafka is running out of free disk space'
description: 'There are only {{ $value }} percent available at {{ $labels.persistentvolumeclaim }} PVC'
- alert: UnderReplicatedPartitions
expr: kafka_server_replicamanager_underreplicatedpartitions > 0
for: 10s
labels:
severity: warning
annotations:
summary: 'Kafka under replicated partitions'
description: 'There are {{ $value }} under replicated partitions on {{ $labels.kubernetes_pod_name }}'
- alert: AbnormalControllerState
expr: sum(kafka_controller_kafkacontroller_activecontrollercount) by (strimzi_io_name) != 1
for: 10s
labels:
severity: warning
annotations:
summary: 'Kafka abnormal controller state'
description: 'There are {{ $value }} active controllers in the cluster'
- alert: OfflinePartitions
expr: sum(kafka_controller_kafkacontroller_offlinepartitionscount) > 0
for: 10s
labels:
severity: warning
annotations:
summary: 'Kafka offline partitions'
description: 'One or more partitions have no leader'
- alert: UnderMinIsrPartitionCount
expr: kafka_server_replicamanager_underminisrpartitioncount > 0
for: 10s
labels:
severity: warning
annotations:
summary: 'Kafka under min ISR partitions'
description: 'There are {{ $value }} partitions under the min ISR on {{ $labels.kubernetes_pod_name }}'
- alert: OfflineLogDirectoryCount
expr: kafka_log_logmanager_offlinelogdirectorycount > 0
for: 10s
labels:
severity: warning
annotations:
summary: 'Kafka offline log directories'
description: 'There are {{ $value }} offline log directories on {{ $labels.kubernetes_pod_name }}'
- alert: ScrapeProblem
expr: up{kubernetes_namespace!~"openshift-.+",kubernetes_pod_name=~".+-kafka-[0-9]+"} == 0
for: 3m
labels:
severity: major
annotations:
summary: 'Prometheus unable to scrape metrics from {{ $labels.kubernetes_pod_name }}/{{ $labels.instance }}'
description: 'Prometheus was unable to scrape metrics from {{ $labels.kubernetes_pod_name }}/{{ $labels.instance }} for more than 3 minutes'
- alert: KafkaContainerRestartedInTheLast5Minutes
expr: count(count_over_time(container_last_seen{container="kafka"}[5m])) > 2 * count(container_last_seen{container="kafka",pod=~".+-kafka-[0-9]+"})
for: 5m
labels:
severity: warning
annotations:
summary: 'One or more Kafka containers restarted too often'
description: 'One or more Kafka containers were restarted too often within the last 5 minutes'
- name: connect
rules:
- alert: ConnectFailedConnector
expr: sum(kafka_connect_connector_status{status="failed"}) > 0
for: 5m
labels:
severity: major
annotations:
summary: 'Kafka Connect Connector Failure'
description: 'One or more connectors have been in failed state for 5 minutes,'
- alert: ConnectFailedTask
expr: sum(kafka_connect_worker_connector_failed_task_count) > 0
for: 5m
labels:
severity: major
annotations:
summary: 'Kafka Connect Task Failure'
description: 'One or more tasks have been in failed state for 5 minutes.'
- name: bridge
rules:
- alert: AvgProducerLatency
expr: strimzi_bridge_kafka_producer_request_latency_avg > 10
for: 10s
labels:
severity: warning
annotations:
summary: 'Kafka Bridge producer average request latency'
description: 'The average producer request latency is {{ $value }} on {{ $labels.clientId }}'
- alert: AvgConsumerFetchLatency
expr: strimzi_bridge_kafka_consumer_fetch_latency_avg > 500
for: 10s
labels:
severity: warning
annotations:
summary: 'Kafka Bridge consumer average fetch latency'
description: 'The average consumer fetch latency is {{ $value }} on {{ $labels.clientId }}'
- alert: AvgConsumerCommitLatency
expr: strimzi_bridge_kafka_consumer_commit_latency_avg > 200
for: 10s
labels:
severity: warning
annotations:
summary: 'Kafka Bridge consumer average commit latency'
description: 'The average consumer commit latency is {{ $value }} on {{ $labels.clientId }}'
- alert: Http4xxErrorRate
expr: strimzi_bridge_http_server_requestCount_total{code=~"^4..$", container=~"^.+-bridge", path !="/favicon.ico"} > 10
for: 1m
labels:
severity: warning
annotations:
summary: 'Kafka Bridge returns code 4xx too often'
description: 'Kafka Bridge returns code 4xx too much ({{ $value }}) for the path {{ $labels.path }}'
- alert: Http5xxErrorRate
expr: strimzi_bridge_http_server_requestCount_total{code=~"^5..$", container=~"^.+-bridge"} > 10
for: 1m
labels:
severity: warning
annotations:
summary: 'Kafka Bridge returns code 5xx too often'
description: 'Kafka Bridge returns code 5xx too much ({{ $value }}) for the path {{ $labels.path }}'
- name: kafkaExporter
rules:
- alert: UnderReplicatedPartition
expr: kafka_topic_partition_under_replicated_partition > 0
for: 10s
labels:
severity: warning
annotations:
summary: 'Topic has under-replicated partitions'
description: 'Topic {{ $labels.topic }} has {{ $value }} under-replicated partition {{ $labels.partition }}'
- alert: TooLargeConsumerGroupLag
expr: kafka_consumergroup_lag > 500
for: 30s
labels:
severity: warning
annotations:
summary: 'Consumer group lag is too big'
description: 'Consumer group {{ $labels.consumergroup}} lag is too big ({{ $value }}) on topic {{ $labels.topic }}/partition {{ $labels.partition }}'
- name: certificates
interval: 1m0s
rules:
- alert: CertificateExpiration
expr: |
strimzi_certificate_expiration_timestamp_ms/1000 - time() < 30 * 24 * 60 * 60
for: 5m
labels:
severity: warning
annotations:
summary: 'Certificate will expire in less than 30 days'
description: 'Certificate of type {{ $labels.type }} in cluster {{ $labels.cluster }} in namespace {{ $labels.resource_namespace }} will expire in less than 30 days'
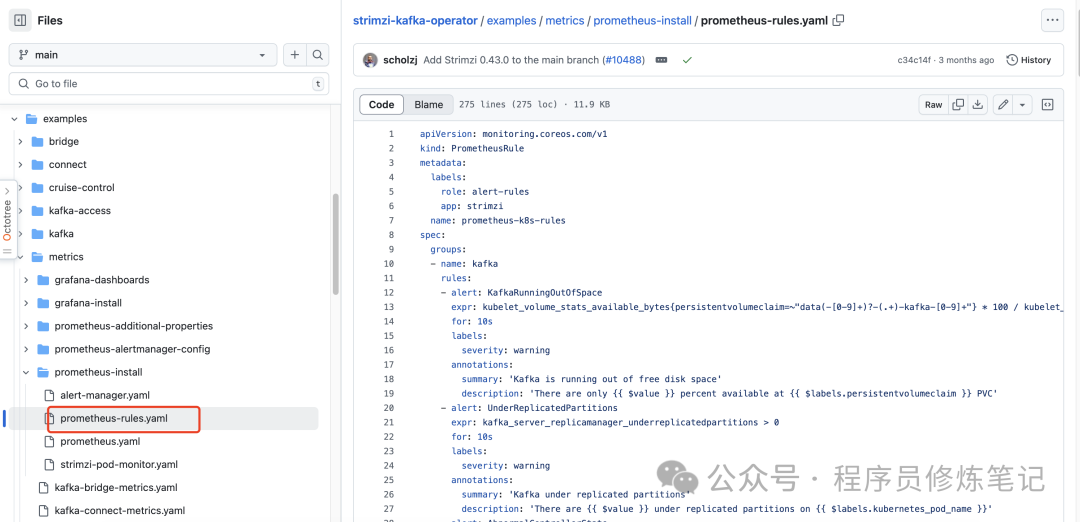
上面这个规则文件可以strimzi/strimzi-kafka-operator的github 中找到,如下图:
关于如何告警
Prometheus根据PrometheusRule触发告警,告警会被发送Alertmanager,在AlterManager 中会被发到Kubersphere的NotificationManager中,关于NotificationManager及告警系统我们后续单独进行描述。
