




1. LinDB的背景
时间序列数据库相对于关系型数据库,NoSQL这些产品还很年轻,但市场上已经有很多的实现,比如生态强大非常易用的 Influxdb,还有目前我司目前在用的Prometheus及集群版的实现VictoriaMetrics。不同的时序数据库各有特点,设计倾向也不同。这里从我参与的开源时间序列数据库项目 LinDB 出发来分享一些设计开发经验。

LinDB ( https://github.com/lindb/lindb )是老东家饿了么监控框架组里的自研产品,从16年开始经历了几个大的迭代,16年到18年主要基于RocksDB进行开发,18年开始自研存储和设计倒排索引,以前一直是基于Java开发,19年下半年,选择使用了Go进行重写开源,对于存储、索引、架构的设计都进行了调整。
2. LinDB的架构
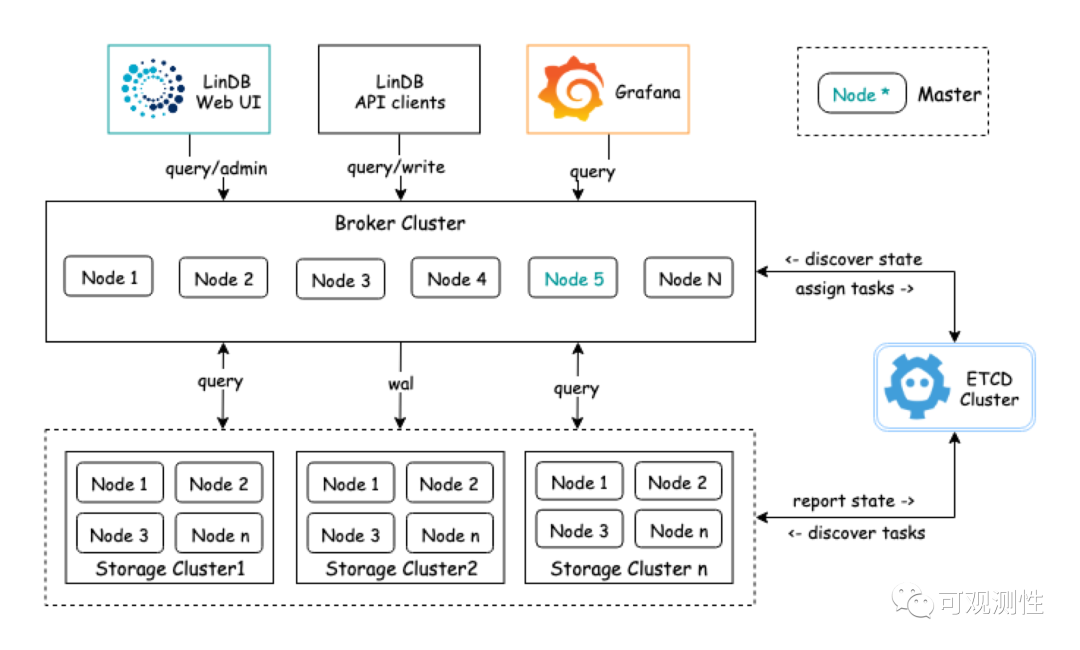
存储能力的提供方式是多样的,比如对象存储,HDFS存储,KV存储,文件存储等。对于时序的设计来说也需要取舍,有些tsdb的方案会使用对象存储,比如prometheus第三方集群方案thanos,它的设计追求的是完全无状态,可以将数据存储到对象存储中。然而我觉得它的设计比较丑陋且复杂,维护成本很高,远不如 VictoriaMetrics 从头到尾自己做来的优雅。
基于HDFS构建TSDB的时序数据库也是部分产品的选择,比如 OpenTSDB,缺点是基于HBase构建TSDB原生无法支持二级索引。还有部分产品属于多模设计,比如阿里云的Lindorm,底层也是HDFS这一套,但可以兼容各种类型的数据,比如OpenTSDB, InfluxDB文本行协议,甚至还支持让用户以SQL的形式来写入数据;
KV存储这里指的是分布式的kv存储,而不是单机的 leveldb, rocksdb这种方案,单机的kv属于文件存储。比如蚂蚁金服CeresDB(现在的OceanBase时序数据库),他们采用内部的高可用的KV存储。
文件存储目前依然是tsdb设计的主流,我们在设计 storage 层时受限于开发成本也没有考虑针对对象存储做一些冷热分离的工作,我们目前采用的是时间降精度的rollup方案。使用kv存储和hdfs存储我觉得属于是种拼爹的设计,成本太高了,除了云厂商大家都玩不起。
3. Metric指标的结构
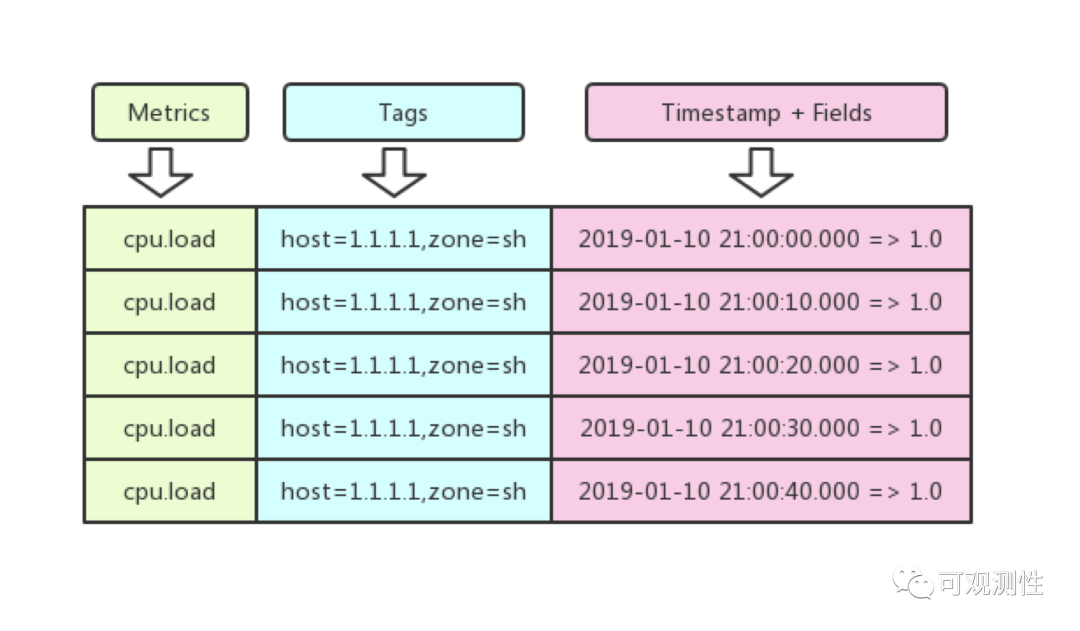
这张图是 metric的结构,时序数据可以根据其性质分为随时间变化和不随时间变化的数据。一个Metric可以简单的认为它是一个mysql的table,不同时间对应了不同的行,tags和field对应不同的列。metric 和tags共同确定一条独一无二的时间线。
在metric结构中,metric-name,tag key及tag value占据了主要的存储空间,并且改变较少,因此将该部分的数据转换为数值来进行存储,可以显著的降低存储成本。这是一种基于字典的压缩方式,源于 OpenTSDB;
Fields的数据基本都是数值,在InfluxDB中的Fields,是基本类型,还支持了string bool这些,但这不在讨论范畴中,绝大多数场景,纯数值已经可以满足可观测性的需求。数值类型很容易做压缩,在LinDB中我们支持了float64的数值,和Prometheus一样。数值部分,使用了XOR进行压缩,该算法源自于Facebook的gorilla。
不同TSDB支持的数值个数也是不同的,Influxdb和lindb支持多值,即一个metric下可存在多个数值,而promethues是单值系统,一个Metric下仅存在一个数值。
4. Event Model 指标的事件模型
有了Metric Model后,需要思考一下,指标数据从哪里来?
OpenTelemetry是google 微软等公司搞的大一统的可观测性方案,主要目标是定一套统一的规范。这里使用OpenTelemetry的定义和图片来进行介绍。
它将Metric的存在形式分为了三种,Event Model, DTO model, TSDB model。分别对应了Metric在用户侧、传输侧、存储侧的三个生命段。使用Java的同学都知道Micrometer,里面也有Gauge、Counter、Timer以及衍生的其他Meter对象,每次触发打点即对应了一个Event事件,这些事件需要进入一个聚合层,在某个时间点位达成快照,传输给后端系统。循环往复的产生事件,这些数据便构成了流。
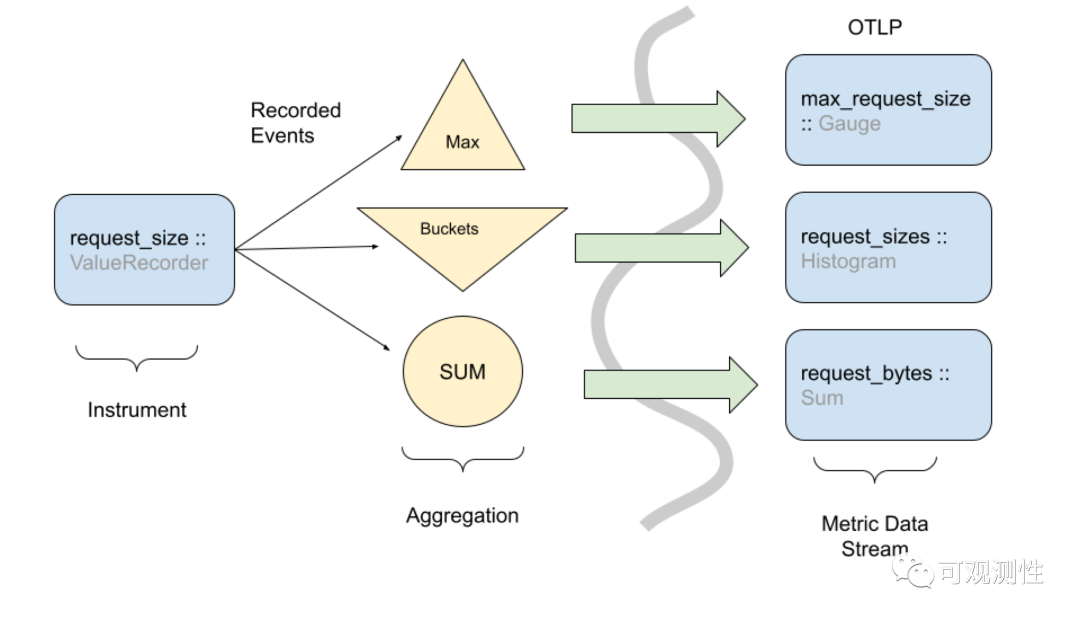
那它为什么没有声明Prometheus的Summary呢,主要还是由于这个metric比较废,精度不高,用途不大,OpenTelemetry不支持,其他TSDB也没这玩意。Histogram也可以完美的替代。

差值型的sum,对应的是push推机制下的counter。每两次采集过程,会与上一次的值求差,记录的仅仅是一个增量,delta 型的数据相对于累积性的数据是可以做到无状态的,更加方便的进行分布式拓展。

累积性的sum,对应的是pull拉机制下的counter。那为什么push 和pull的counter会有差值型和累积性的区别?
某些场景下,拉取pull可能对应有多个采集进程,pull的过程也存在失败的可能性,因此无法给出稳定的差值,只能设计成累积性的数据,便能完全不依赖监控系统。进程一旦启动,counter便会不停的增长。然而也会带来一定的副作用,对应的查询语句会变得复杂一些,比如prometheus里的counter,大多数情况下,都得使用increaseing、rate、irate函数来进行时间级的换算。
而push机制下设计 ,则不认为会有收集失败的可能性,推送可以一对一也可以一对多也可以进行重试,gather和write 是独立的行为,pull下的gather和read是一个行为。
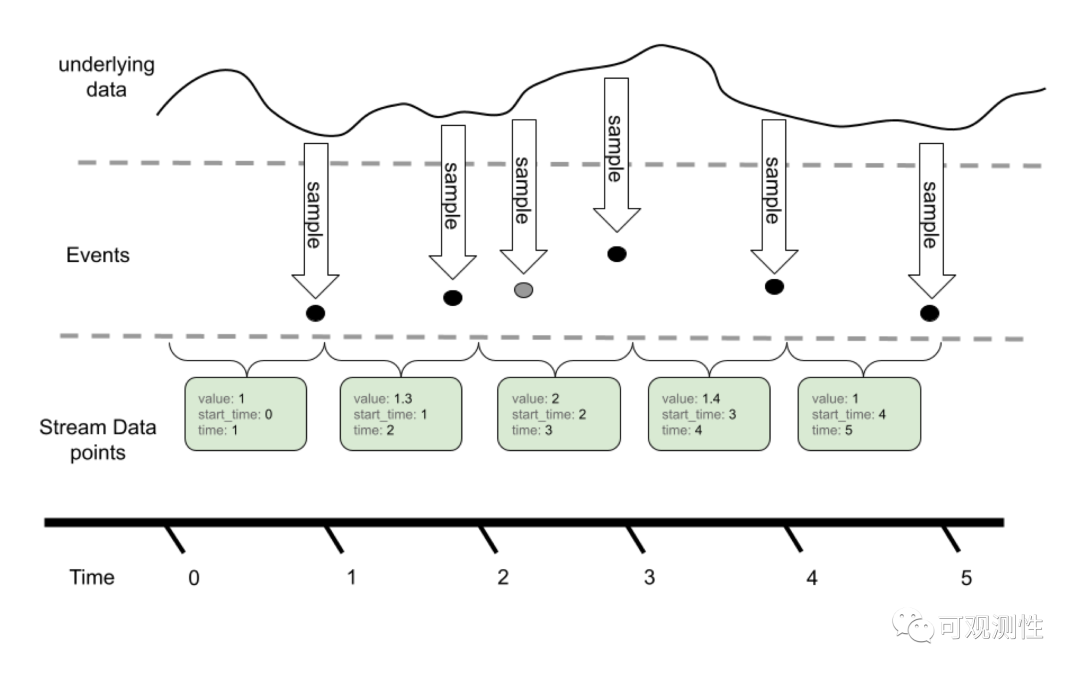
gauge的用法比较简单,典型的用途便是观测cpu、内存水位等。
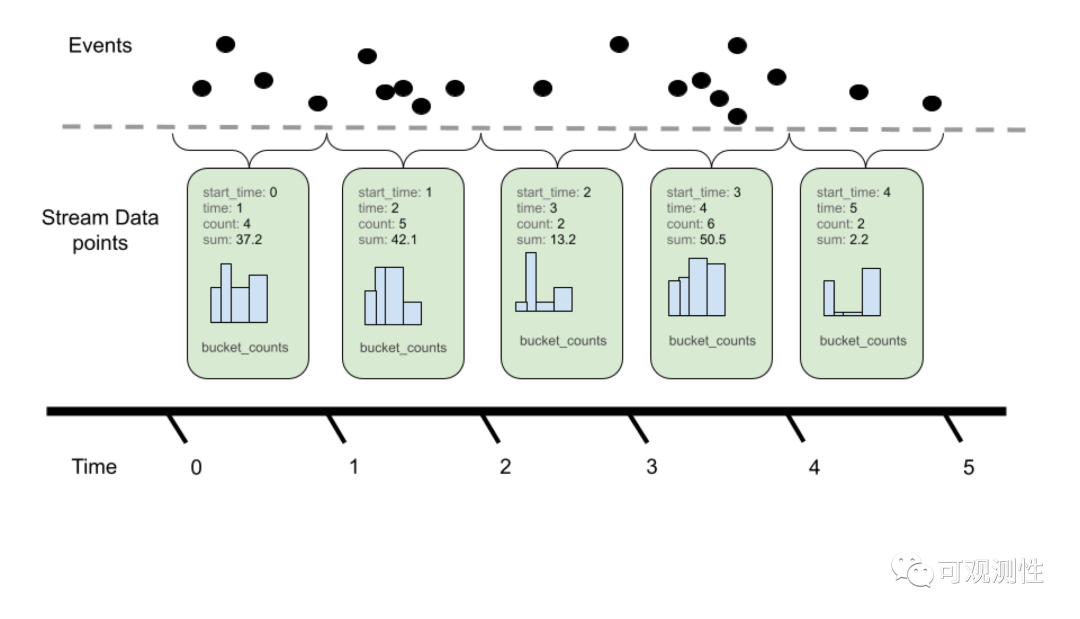
Histogram的数据结构相对其他的metric会复杂一些,它存在多个桶,每个桶存放不同的区间的数据。也区分累积性和差值型,在lindb里是delta的,在promethues里是cumulative的。上面我们说过,promethues是单值系统,histogram有多个桶,它便将Histogram的不同的桶展开到一个特殊的label上,打平成不同的时间线,每条时间线还是对应着累积性的sum型;
在lindb中,我们用的是多值系统,便可以将Histogram的不同的桶展开到不同的field上,仍然保持成一条时间线,每个field对应的是差值型的sum型;
5. 构造 Event Model 的设计范式
那么,在用户侧的SDK是如何产生埋点的呢?主要有两种典型的设计模式,一种是同步的streaming模式,每次打点时都会去构造一个Metric的数据结构,在缓冲Buffer内进行一段时间的聚合。另一种是异步的oberserve模式,预声明出metric的类型,埋点时可以直接使用CAS操作,收集线程则异步去获取注册的指标。
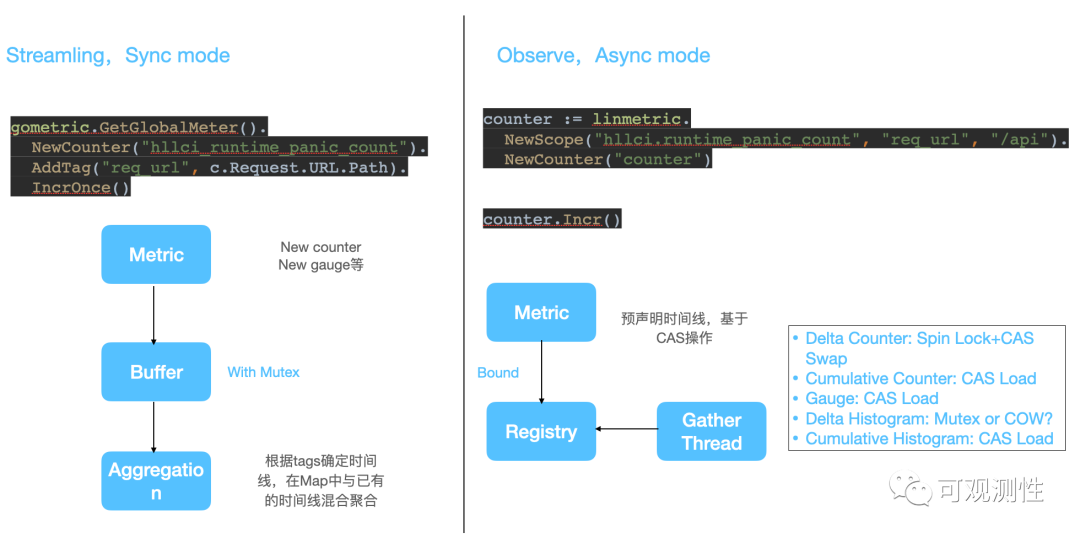
再简单的分析一下收集的成本,对于Gauge和累积性的Counter,只要原子性的读,而差值型的counter需要自旋锁+CAS swap,收集并重置delta数据。在prometheus里的histogram,累积性不仅体现在某个桶上,在桶之间也是累计求和的,这样可以做到Histogram的无锁埋点,而delta的histogram收集数据,需要加锁或者copy on write。
6. TSDB Model和数据摄取
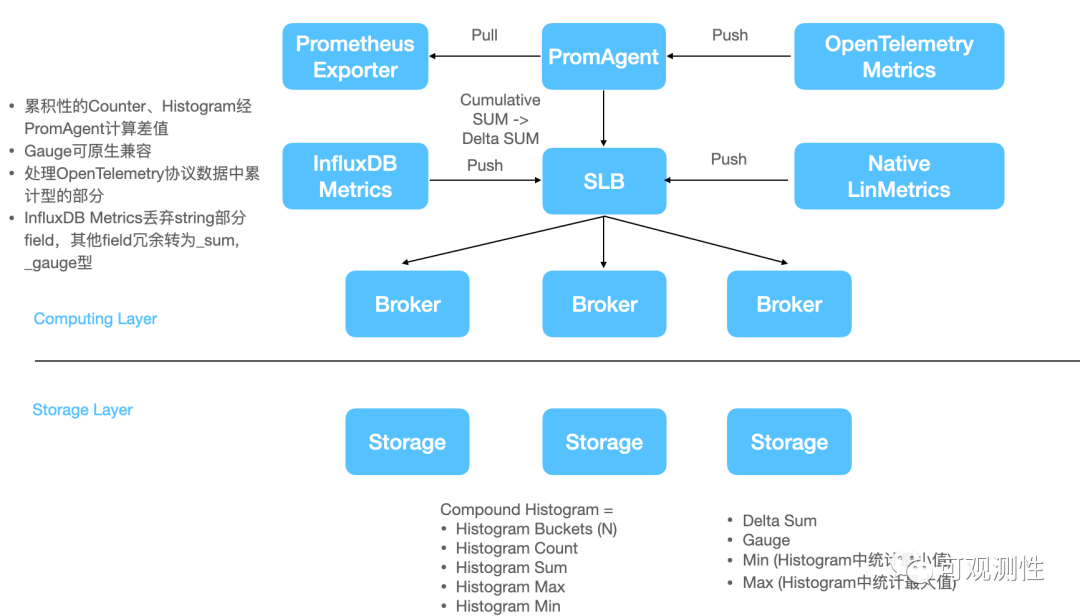
介绍完事件模型,这里讲下在LinDB中内部的数据模型和数据摄取。在LinDB中,支持的是四种聚合类型,差值型的sum,min, max, gauge。
在存储的时候histogram会展开成 不同bucket的 sum,sum型的count来记录埋点次数,sum型的total来记录总和,min max分别记录最小值和最大值,对应着sdk timer里的最小和最大耗时,以补偿特殊情况下p99的不足。
为了自监控,也得开发了一套原生的Lin-metrics的sdk,来实现多值metric的埋点。
然而现在InfluxDB有TICK生态,prometheus也有自己的生态,opentsdb也有自己的协议,open telemetry同样弄了自己的传输协议。轮子很多,兼容也是比较头疼的问题。
因此,除了broker 和storage两种节点角色,我们还引入了prom agent来做Prometheus的格式转化,用来将累积性的counter和histogram进行delta换算,而opentelemetry格式的metric则选择性的做格式转换。但是,QL层面的兼容也是个很费劲的问题。
兼容Influxdb的数据更加暴力一些,对于数值型的数据,可以冗余的存放多种聚合类型。
7. DTO Model,传输协议的抉择
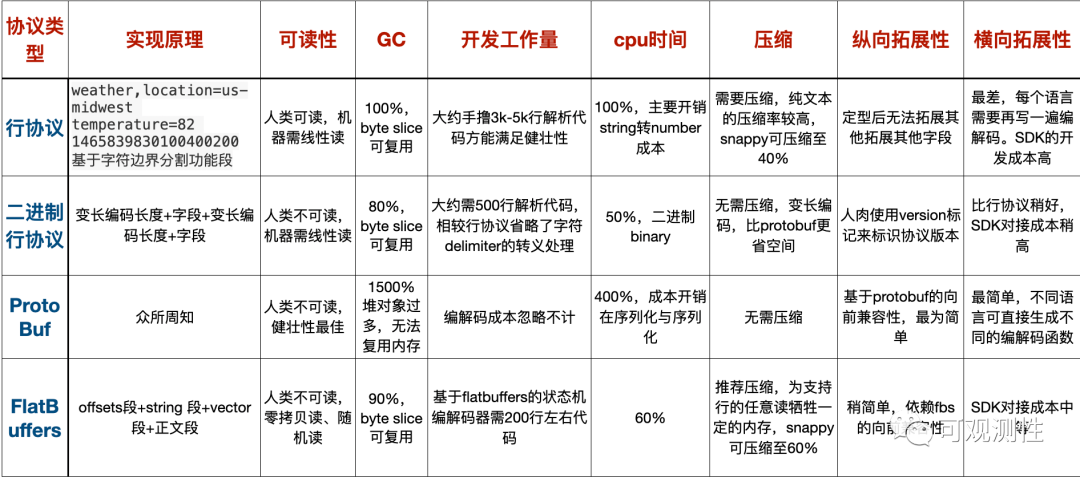
有了事件模型和TSDB模型,数据又要以什么形式在网络上进行传输呢?我觉得最好的方案还是文本的行协议,这也是influxdb 和prometheus都在使用的方案,用户方便抓包和排障,GC友好,在LinDB里实现的却是FlatBuffer。
在Java版本时,LinDB 使用的是更极端的二进制行协议,即一行 Metric 数据里是按固定的顺序来分别写不同的类型,比如 metricname+ tagkey 长度+ tagkey + tagvalue 长度+ tagvalue等等,二进制行协议可以最大化节约空间占用和数据转换的开销。
protobuf 是压缩率最高的方式,同样也具有最好的向前兼容性,拓展到多语言也很简单,但却是性能最差的传输形式,海量的数据在TSDB层面进行解码,会产生大量的堆对象,带来额外的GC成本。
最终没有使用文本行协议,主要还是基于拓展性的考虑,在行协议中很难进行字段拓展,一旦添加一个字段,行协议就得重新进行大量的开发和测试工作,也没有比较好的思路去拓展支持Exemplars。
最后选择了一个比较小众的方案 FlatBuffer 来编码指标数据,用在 SDK->计算层 和 计算层->存储层 的传输上。FlatBuffer相对于行协议有几个优势,可以进行任意读,比如在文本行协议读Field需要从头读到尾,文本行协议的分隔符需要考虑复杂的转义和有效性检测。
以上的方案,除了protobuf都可以比较简单的基于byte slice进行内存复用。
8. LinSQL的设计
作为一个数据库,CRUD是少不了的。
首先,时序数据没理由用Insert 进行插入,效率太低,也不符合传输时的模型结构。时序数据也不需要考虑 update ,这些应当在 tsdb 内部进行处理。如,influxdb里相同时间线相同的时间戳的多个点,新值会覆盖旧值,在lindb里,则根据对应的时间槽位基于聚合类型进行聚合。
PromQL被设计为只有查的功能,这是因为prometheus或vm都不存在database或shard的概念,influxdb的ql则设计的比较完备,支持create database、 create shard,select , drop、delete等操作。lindb的sql和influxdb的ql则更像。这和promql是两种不同设计理念的定位。
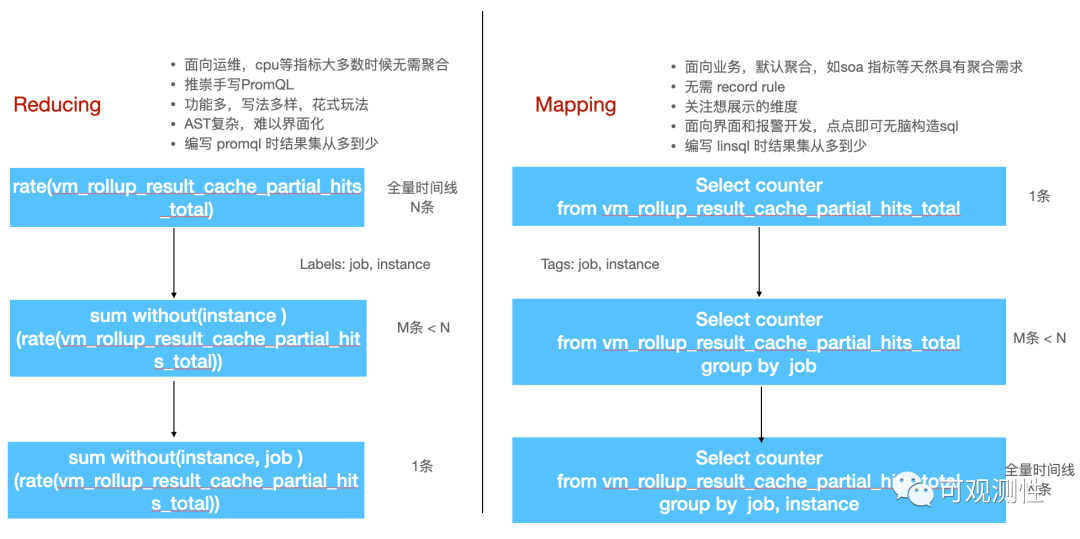
promql的设计是面向运维的,推崇的是手写ql,功能和玩法都很丰富。但是带来的缺点就是语法树很复杂,想要界面化很困难。我司目前探索了前端的函数式配置,但也只能满足大多数普通的场景。编写Promql时,选择一个Metric,首先会给出所有的时间线,然后关注想要的label,逐一聚合,是不是很像一个reducing的过程?
linsql的设计则是面向业务的,查询metric时默认会聚合所有数据,也尽量不会让用户去手写ql,而是借助界面下拉点击来构造sql,用户只需要关注自己想要的tags,进行grouping 分组,便能得到预期的结果集,这个与promql相反的过程有点mapping的味道了。
statement : statementList EOF;statementList : showDatabaseStmt| showNameSpacesStmt| showMetricsStmt| showFieldsStmt| showTagKeysStmt| showTagValuesStmt| queryStmt;queryStmt : T_EXPLAIN? selectExpr(T_ON namespace)? fromClausewhereClause? groupByClause?orderByClause? limitClause?T_WITH_VALUE?;selectExpr : T_SELECT fields;fields : field ( T_COMMA field )* ;field : fieldExpr alias? ;alias : T_AS ident ;fromClause : T_FROM metricName ;whereClause : T_WHERE conditionExpr;……
这个是linsql用antlr编写的语法。
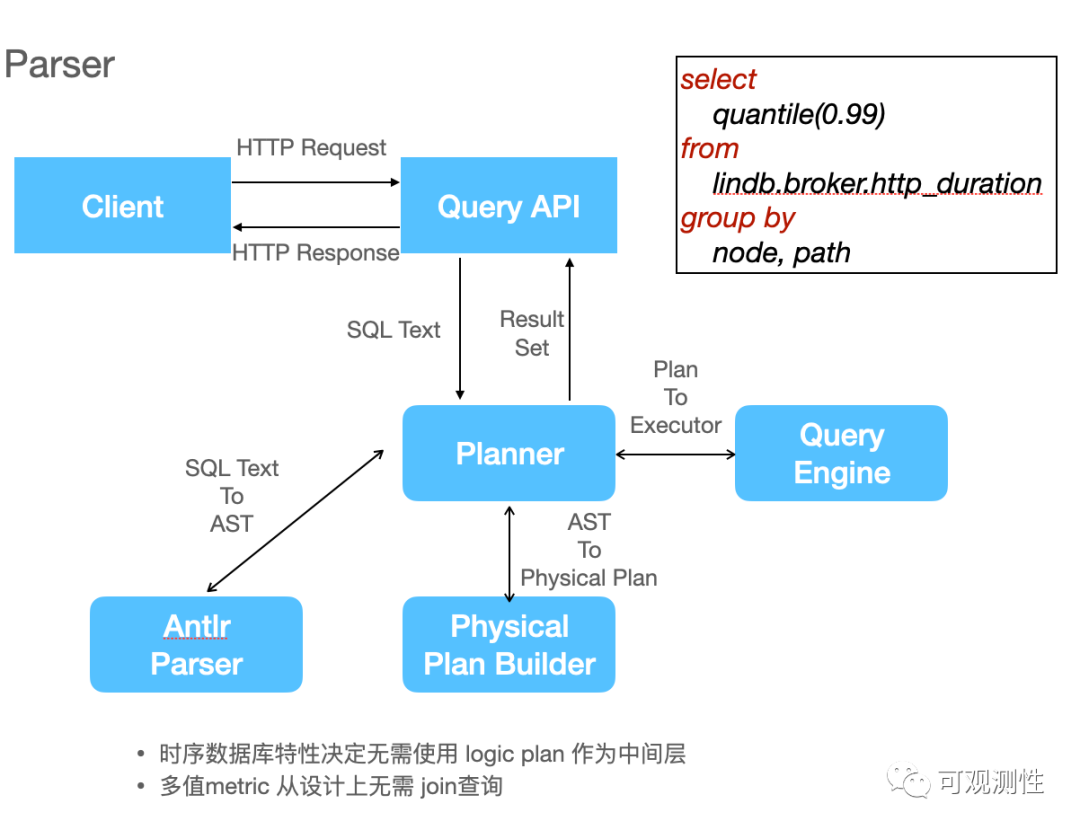
这是一次通过LinSQL查询的执行流程。http_duration是一个Histogram型指标,用户想要查询p99的曲线,planner是查询计划生成器,sql 的文本经过antlr的parser解析后会得到一个抽象语法树即AST(如下图)。对大数据系统或分布式数据库有一些了解的同学可能知道,查询计划一般由逻辑计划和物理计划,中间还需要进行比较复杂的优化,比如谓语下推、列裁剪啊等等策略。
但时序数据库的特性决定了这些都不需要,因此便可以省略掉逻辑计划这一个层次,直接去构建物理计划。生成物理计划后,便可以传递给查询引擎去进行查询了。

9. 分布式查询
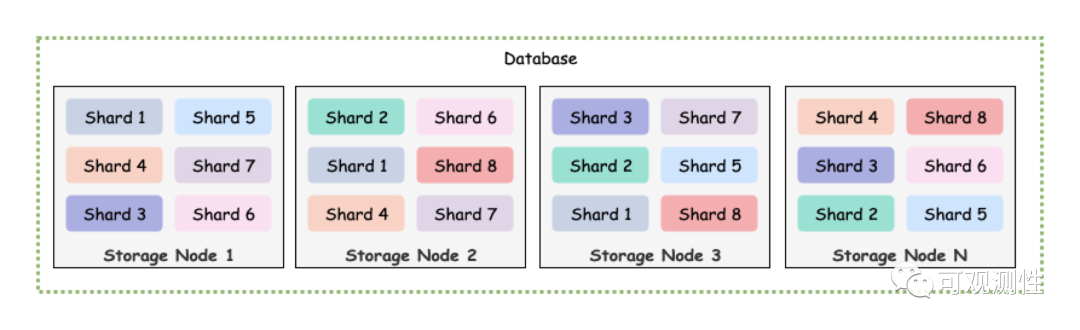
在介绍查询前,先介绍一下lindb里的存储结构。lindb里创建数据库时需要预先声明分片的数量,一个数据库的数据在写入时会打散到不同的分片上,一个节点可能会存在一个数据库的多个分片,一个分片也可能有多个副本。每个分片具有自己的memdb和文件存储,分片使用单线程写入,每秒大概50万到100万tps,这里的tps指的是field粒度的写入速率。在Prometheus的实现里,没有数据库和分片的概念。
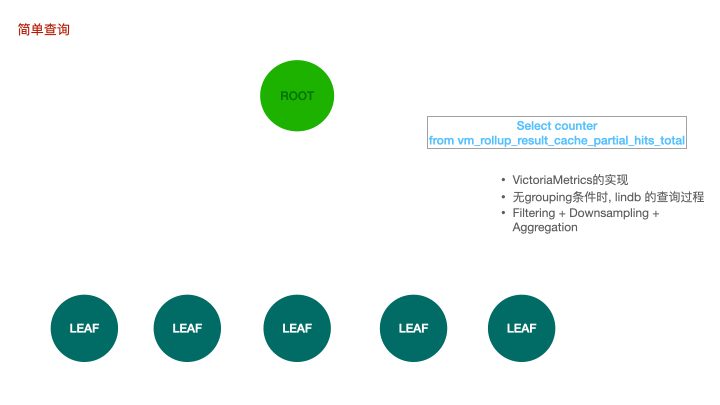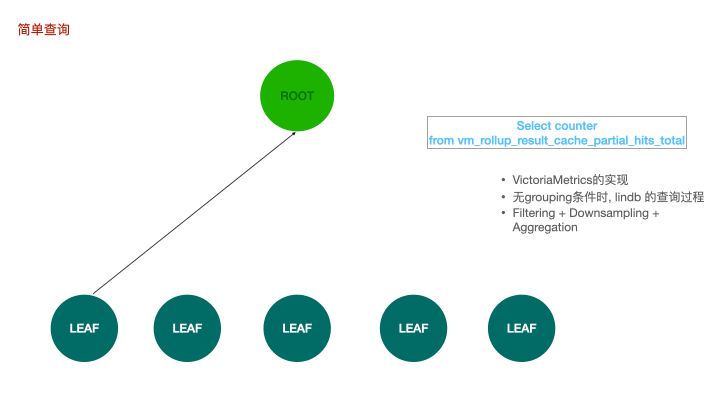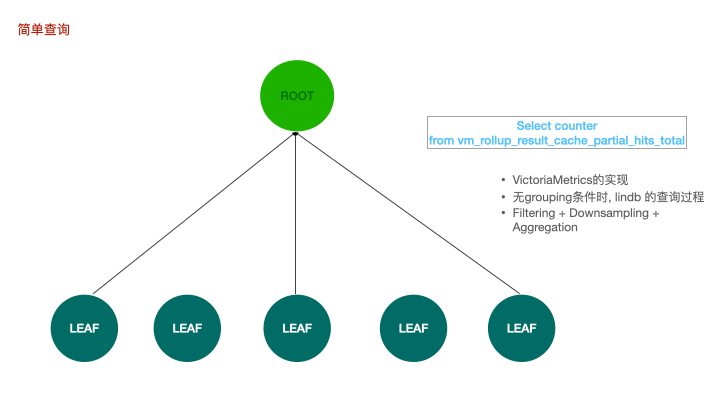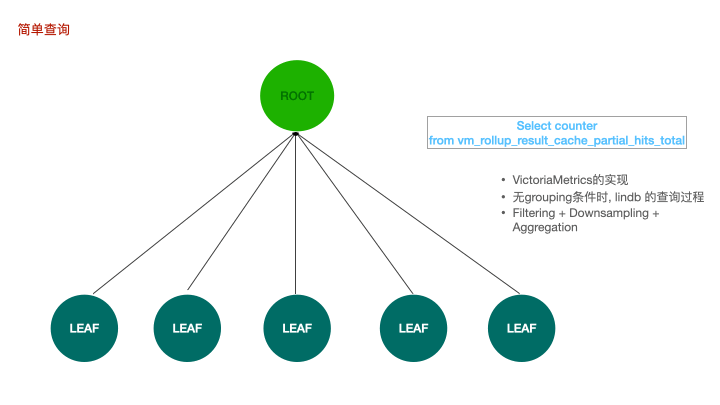
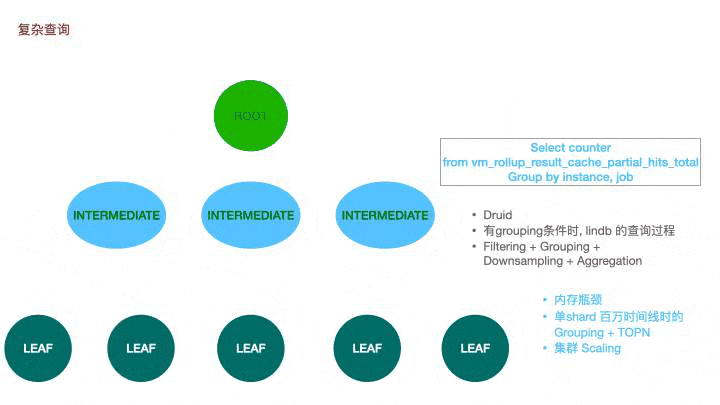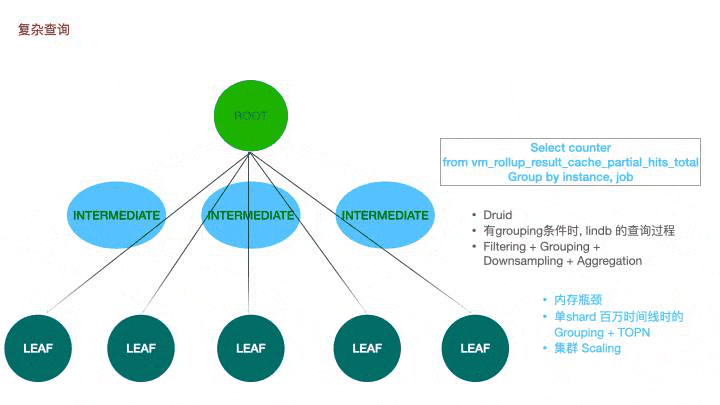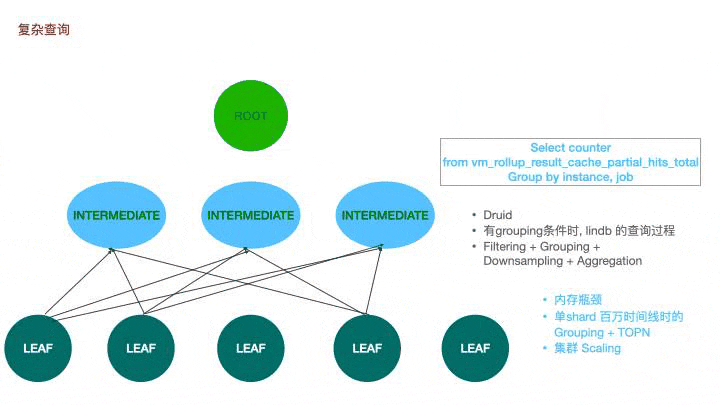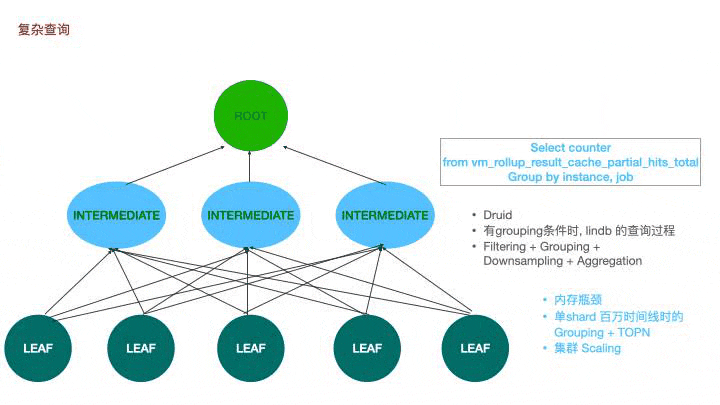
LinDB里的查询分为三种:简单查询,复杂查询和跨数据中心的查询;
简单查询是一个两层的结构,对于lindb来说,Root节点是一个计算节点,leaf是存储层上的不同shard。root节点向当前数据库的所有shard发送查询rpc请求,叶子节点收到请求后捞取数并进行返回,root节点等待并聚合所有叶子节点的数据。在没有grouping条件时,lindb选择使用简单查询。这也是 VictoriaMetrics 的实现,对应的是vmselect到所有vmstorage节点间的查询。
简单查询其实足以满足绝大多数的查询场景,但部分情况下可能存在性能瓶颈。当单shard存在百万时间线时,grouping后再求topn短时需要大量的内存,如果所有数据都由一个根节点去承担,很有可能导致内存不足。在victoria metrics上,我们也存在极个别的大指标查询导致vmselect oom的现象。借鉴druid,我们引入了一个中间的查询层,根节点会在计算层根据并行度挑选特定的几个节点去辅助查询。先推送任务到中间节点,待中间节点建立任务后再发送任务到叶子节点,叶子节点查询后会将数据通过hash分组,分别返回到不同的中间节点上,中间节点再将聚合后的数据返回到根节点。
跨数据中心的查询,类似prometheus的集群联邦,适合多活和多数据中心场景,在大多数场景下用不到,这里就不介绍了。
10. 复制与WAL
讲完查询后,再介绍一下复制与Write Ahead Log。
WAL是数据库事件的顺序日志,Storage在将写入到LSM树中时,需要先将数据记录到WAL中,然后再进行写入操作。因为机器或进程总是会崩溃的,LSM树上的内存部分的生存时间可能有几十分钟或小时级,直到flush到磁盘前这些数据都是不安全的。当数据库崩溃时,需要通过wal进行重放来恢复一致性。
LSM树全称log structured merge tree,日志合并树。近年来,又开始流行更简化的merge tree 合并树的结构,在click house中得到了推广。顾名思义,省略了日志和memtable,当然,现在的clickhouse最后也将WAL添加了回来。
lindb的复制,指的是两个层级,计算层的复制和存储层的复制。计算层无状态的将数据复制到多个副本上,存储层则基于WAL进行主从复制。victoria metrics没有WAL,副本的复制只有vminsert到vmstorage的复制机制;
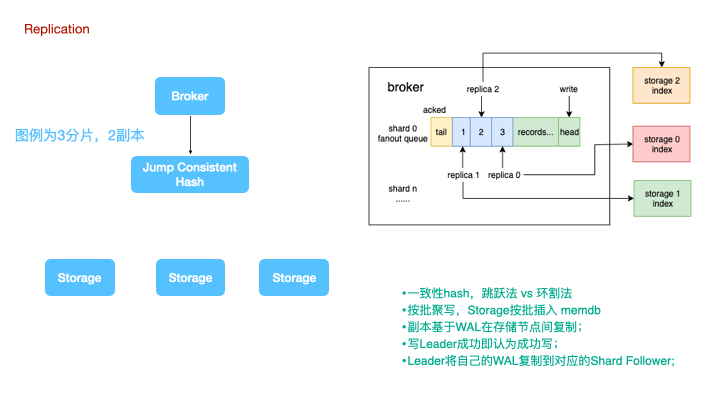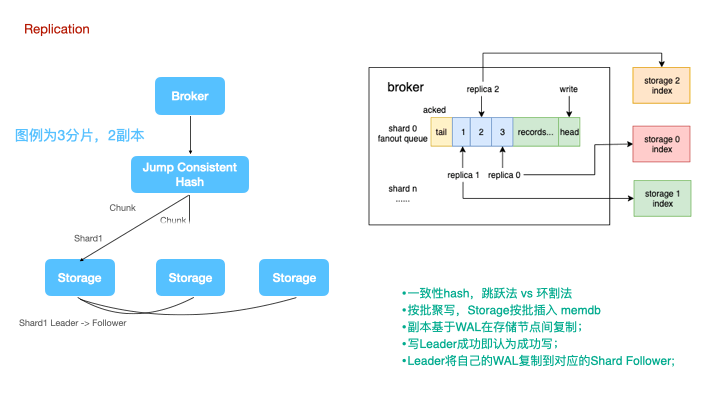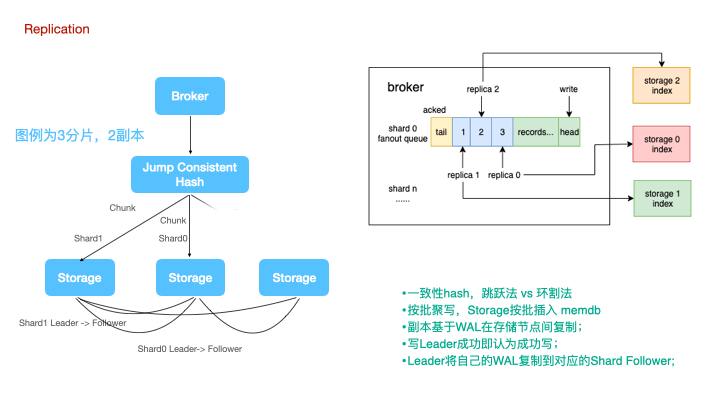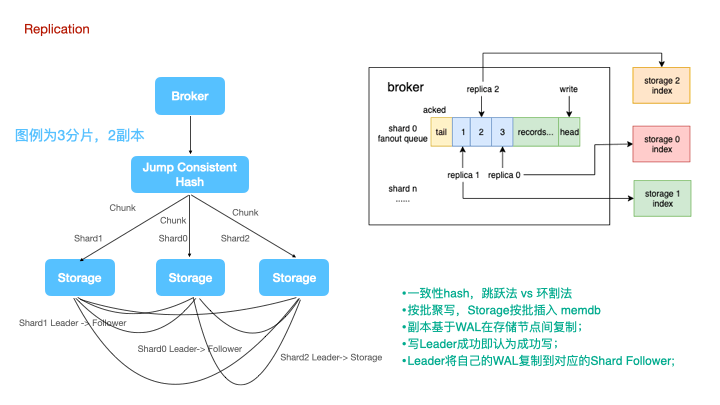
图例是一个3分片,2副本的集群架构图。
时序数据的分布式写,永远是牺牲一致性来实现可用性和分区容忍性。一种朴素的思想是认为分布式写大多数节点成功则写入成功,比如TDEngine,但这种设计无疑会显著的降低系统吞吐量。LinDB在时序复制上做的更加激进一些,数据写到Leader即可认为写成功,Leader再将自己的WAL复制到对应的Follower上。
计算节点写数据时,使用jump consistent hash来对tags做sharding。对于一致性hash,大家可能都对环割法比较熟悉,或者在环状的一致性hash上增加一个中间映射层。而跳跃法的使用更为简单,无需额外的内存占用。
对于Leader宕机的边缘场景,LinDB使用了一种多通道的协议来补偿数据丢失的情况。
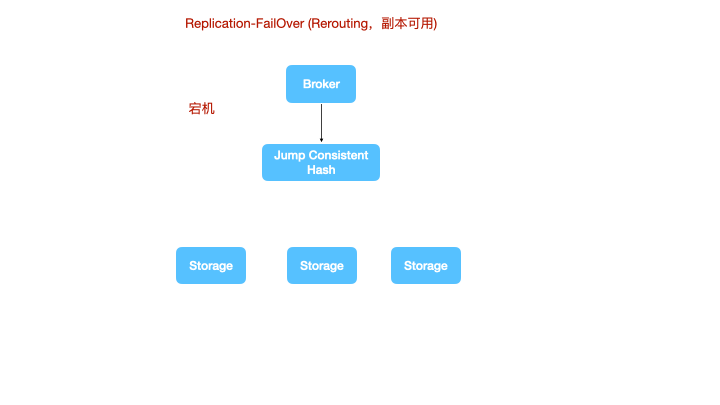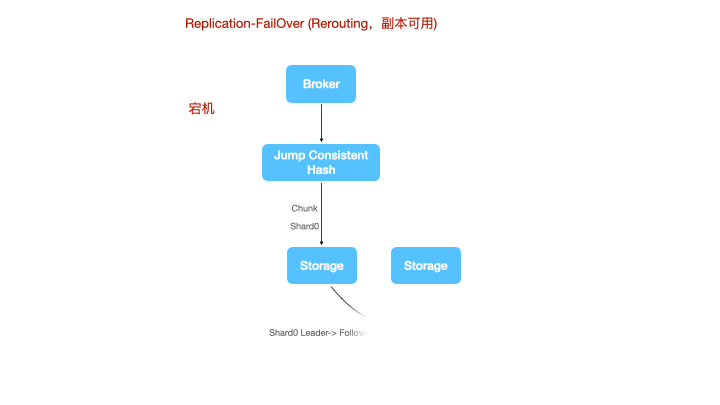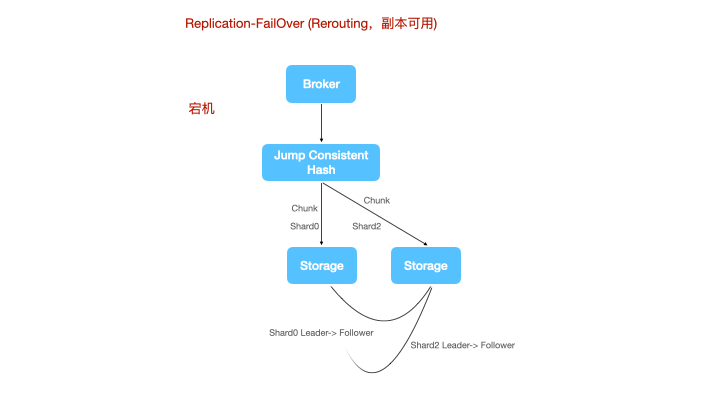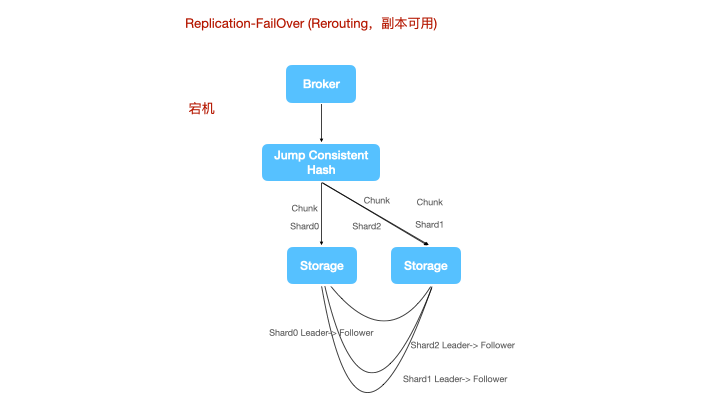
上图是一个节点宕机的情况,shard1丢失了leader,计算节点将数据重新路由到一个新的leader上进行写。
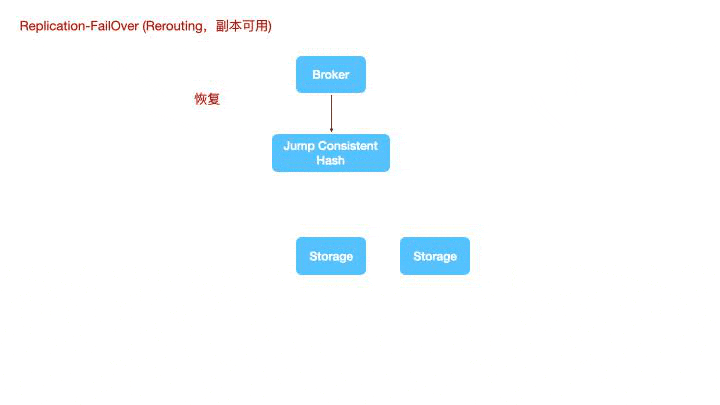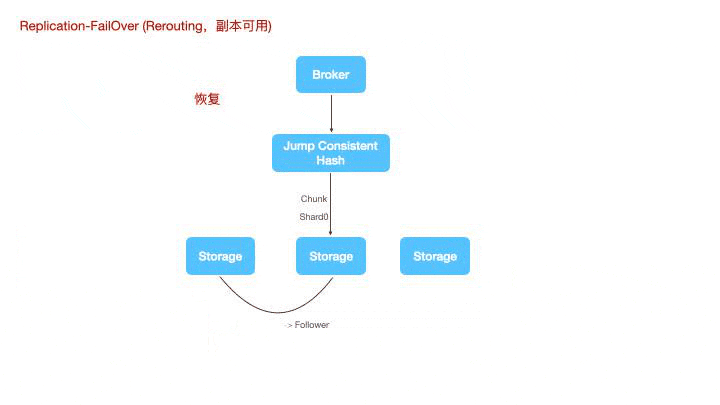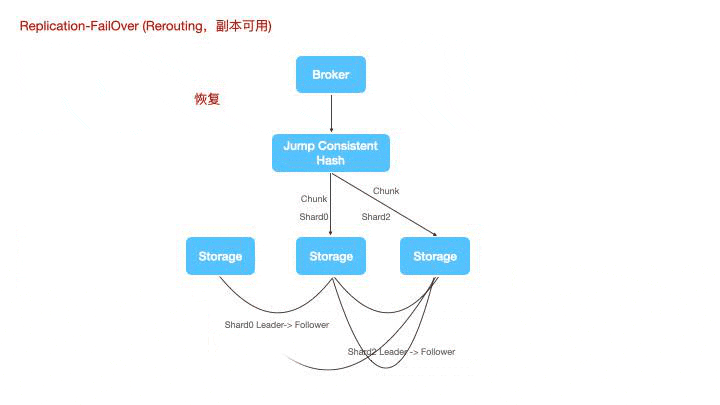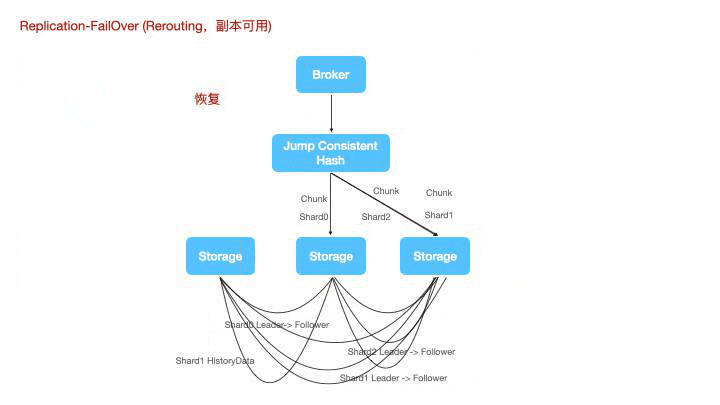
存储节点重新上线时,shard0 shard1 shard2 会将自己的 WAL 复制给重新上线的 storage 节点,而新上线的 storage节点存在部分未复制给 shard0 的数据,也会在原有的通道上,将宕机前还未来得及发送给其他 fowllower 的 WAL 重新补偿发送,来实现一种最终一致性。
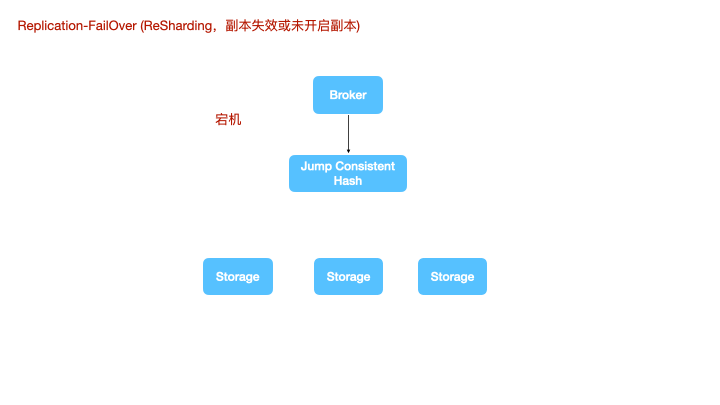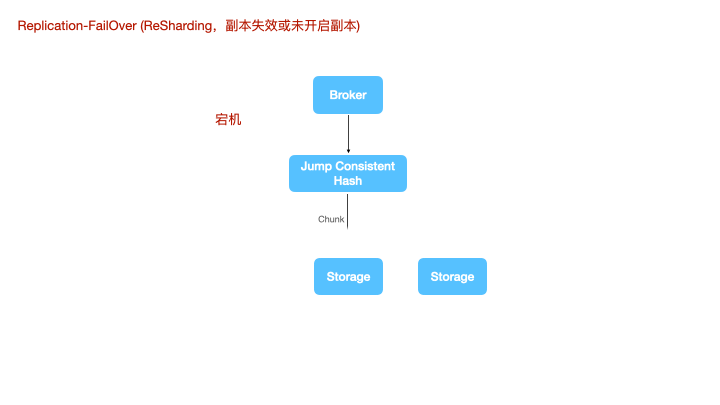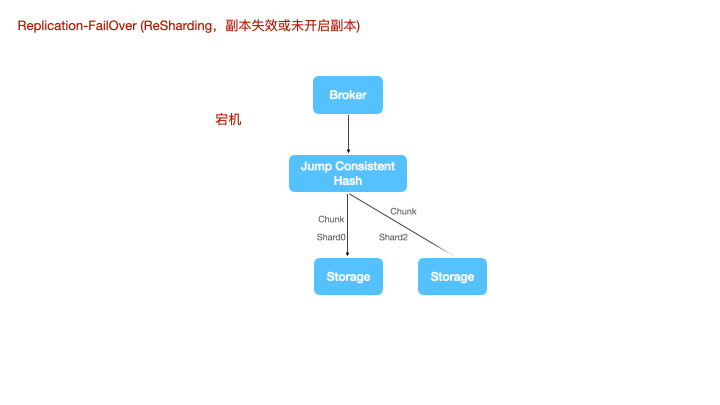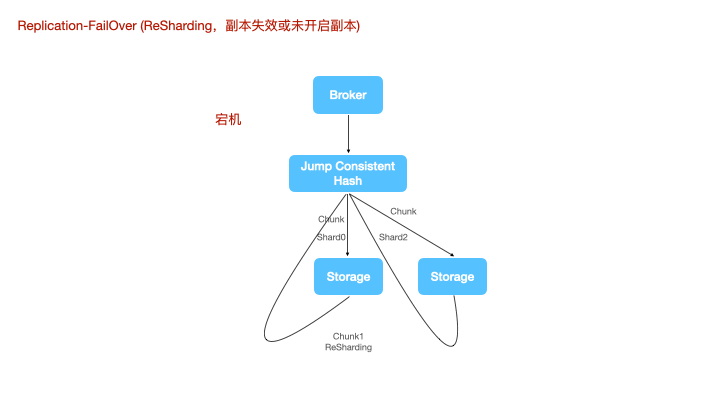
在没有开启副本或某个shard副本完全失效的情况下,计算节点没法对数据重新路由了,就需要二次sharding了,数据会根据一致性hash重新分布到新的shard空间上进行写入。
11. Sorted Number Table(SNT)
这一页介绍一个特殊的工具,roaring bitmap,位图结构在大数据系统中比较常见。在LinDB用于构建倒排和正排索引,用于构建kv和memdb,玩法比较花哨;
它的思想就是对uint32的地址空间进行分桶,针对稀疏数据和稠密数据进行不同形式的处理;
高16位和低16位分桶;
在磁盘上unmarshal + read 300ns左右
使用Array Container, Bitmap Container, Run container;
Array Container 针对稀疏数据,有序二分查找;
Bitmap Container 针对稠密数据,8KB一个,uint16的地址空间;桶元素数量 > 4096时切换;
Run Container使用RLE压缩,适用于连续数据
基于roaring bitmap,lindb构建了一种特殊的文件类型,sorted number table。
针对时序数据的特性,metric name,tag key等都可以通过发号器映射到不同的id上。这是一个snt的查找过程,每一个key都是uint32型的数据,
如图所示,若想要查询key6,可以先通过bitmap获取到对应的offset,然后通过offset去读取这个key的offset,实现O(1)的定位。这种思想不仅可以用于构建snt文件的一级索引,也可以用于二级索引,时间线级的定位。
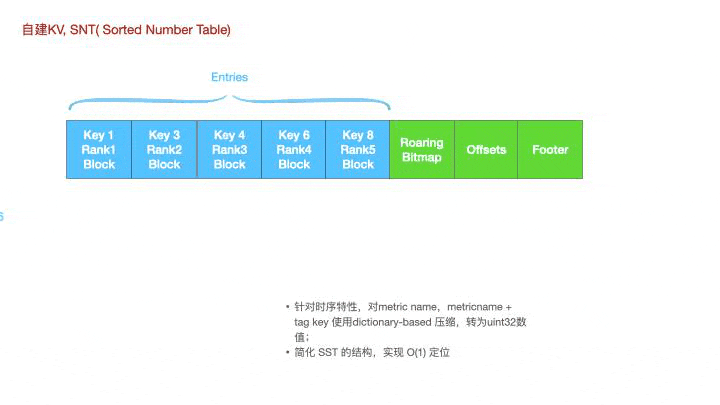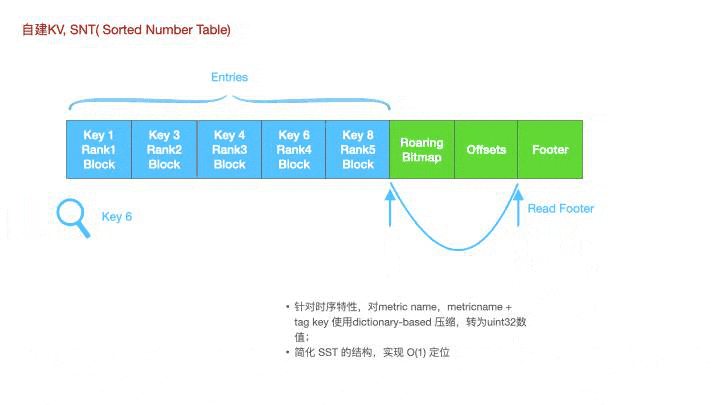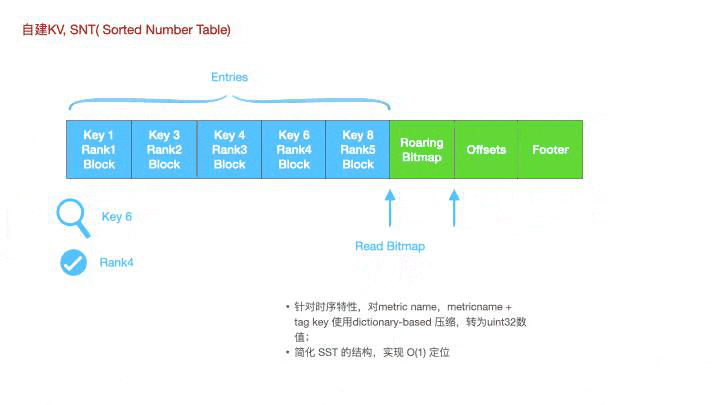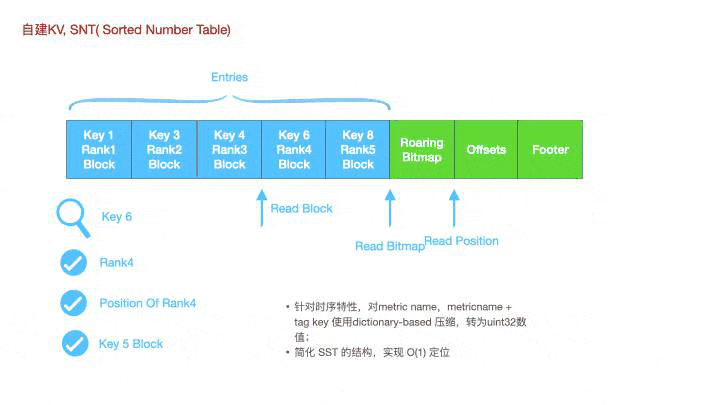
为什么Lindb要做一个snt的kv呢?leveldb rocksdb等都是使用的sorted string table,扩展到时序数据上就是先通过二分查找定位到对应的sst文件,文件内先通过稀疏索引定位到对应的Block上,然后再通过稠密索引二分定位到对应的Metric block上。
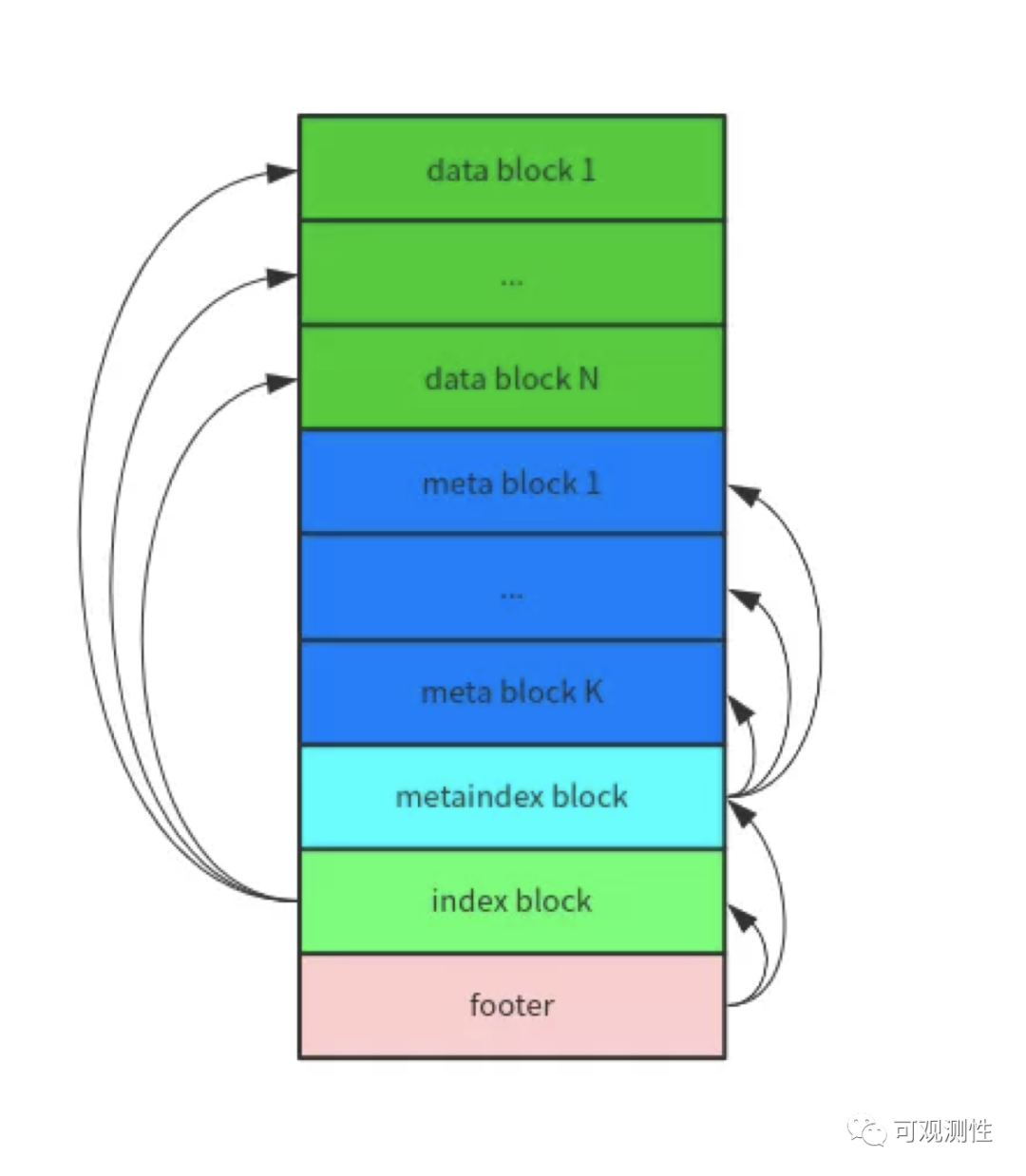
除了一层的Metric的block定位,二层的时间线也需要进行二分查找。
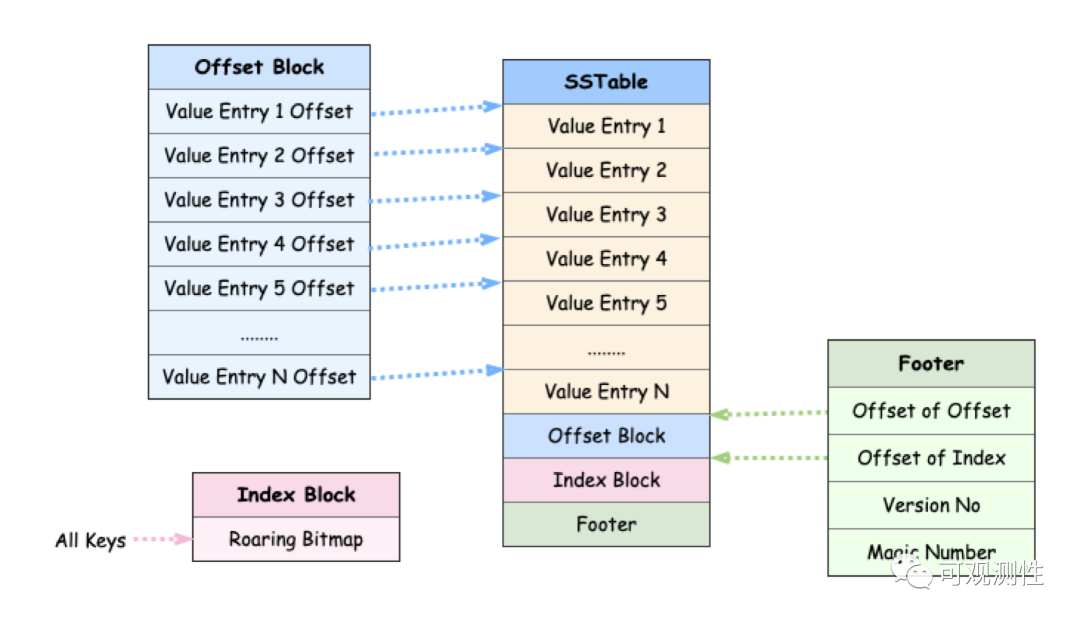
而lindb的snt,通过对文本进行数值编码后可以降低大量的页读取,二级索引占据的空间很少,对于缓存也比较友好,扫描过程可以减少很多的缺页中断。
12. 基于SNT的倒排索引与数据表
基于SNT这个工具,lindb衍生了三种表,tagkey元数据表,对应的tag key下的所有tagvalue和对应的tag value id。
倒排索引,tag key下不同tagvalue对应的bitmap
数据表,metric-id->seriesid->fieldid->数据块
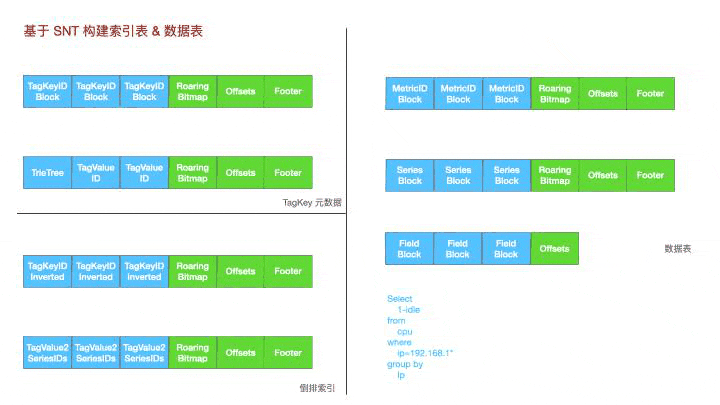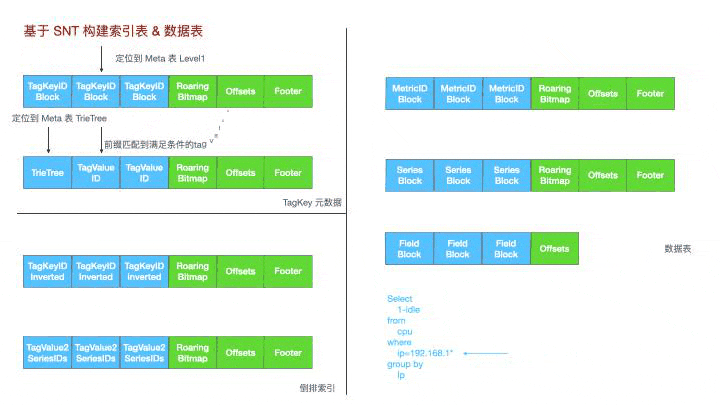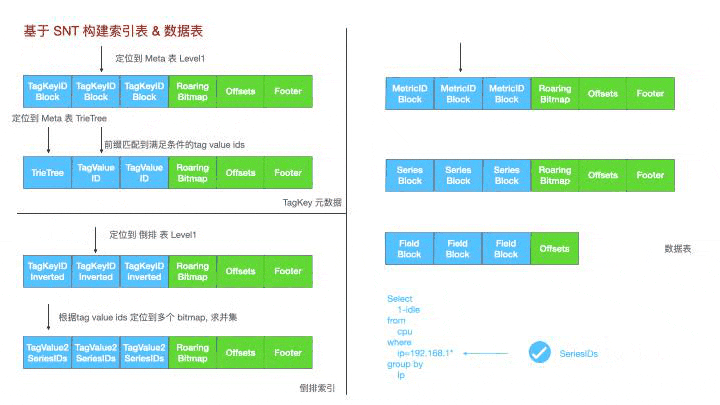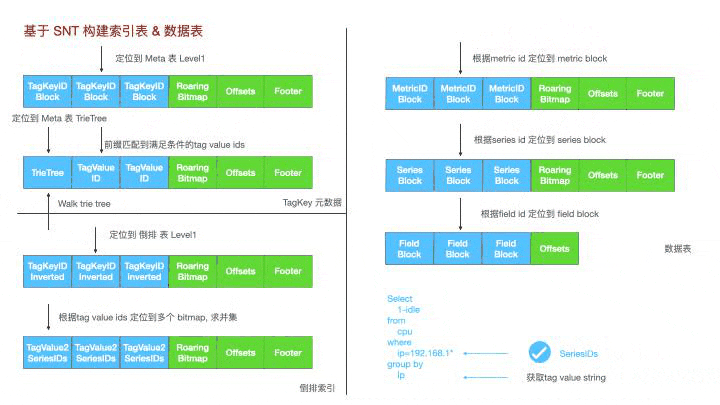
对于这样一个cpu使用率的查询,
第一步,先到meta表中过滤得到192.168.1.前缀的tag value id集合;
第二步,再到倒排索引表内找到这些tag value id对应到时间线id的bitmap集合并求并集,得到满足条件的所有时间线;
第三步,去数据表里扫描对应Id的数据;
第四步,到meta表找到对应的ip字符串;
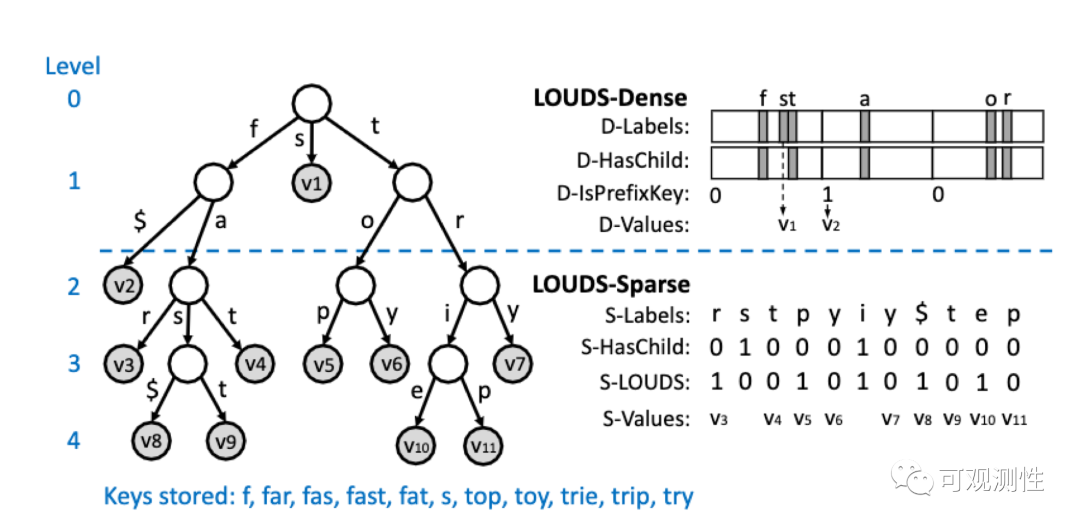
Lindb里使用trie tree(源自Surf,Fast Succinct Tries)来压缩tag key下的tag value,这个数据结构来自于Surf ,这是一种succincint的编码方式,压缩率很好,读取时缓存友好。
LOUDS (Level-Ordered Unary Degree Sequenc), Select / Rank 原语;
提供 string-> byte slice的查询,用于 tagvalue到series id & tag value id的映射
压缩率很好,相较于B+ 非常节约空间;
数据结构紧凑,以immutable的Byte slice存在,cpu 缓存友好,且充分利用磁盘预读特性;
65 万 tag values,迭代大约11ms,迭代+取key、value 35ms;
Cpu 密集性;
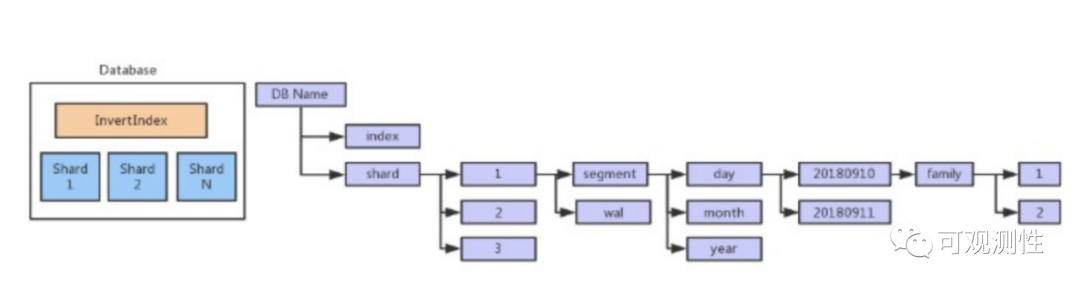
如上是数据在一台 Storage 节点上面的存储目录结构,以单个数据库在单节点上的数据结构为例:
index: 存储所有的 metadata 和 index
metadata: 是数据库级别的,即所有的 shard 共享这些数据
index: 每个 Shard 都会有自己的正排 和 倒排 数据
shard: 一个数据库在单节点上会存在多个 shard
所有的数据根据数据库的 Interval 来计算按时间片来存储具体的数据。
经典的LSM树是多个层级的,一般由6或7层,每层向下compact。由于时序数据具有天然的时间边界,因此将数据按时间段分片存放,只需要两层即可,可以有效的避免数据合并的写放大。每次minor compaction即将memtable里的数据写入到磁盘的level0上,然后level0则进行compact或rollup到level1。
13. 基于B+的全局发号器
有些tsdb的索引会选择索引和数据共同存放,这会大大简化数据过期的策略,比如influxdb的shard对应的是一个时间段的数据。在lindb中,使用的是一个类似全局发号器的索引,来关联多个分片。
这主要是基于几个因素后进行的设计。
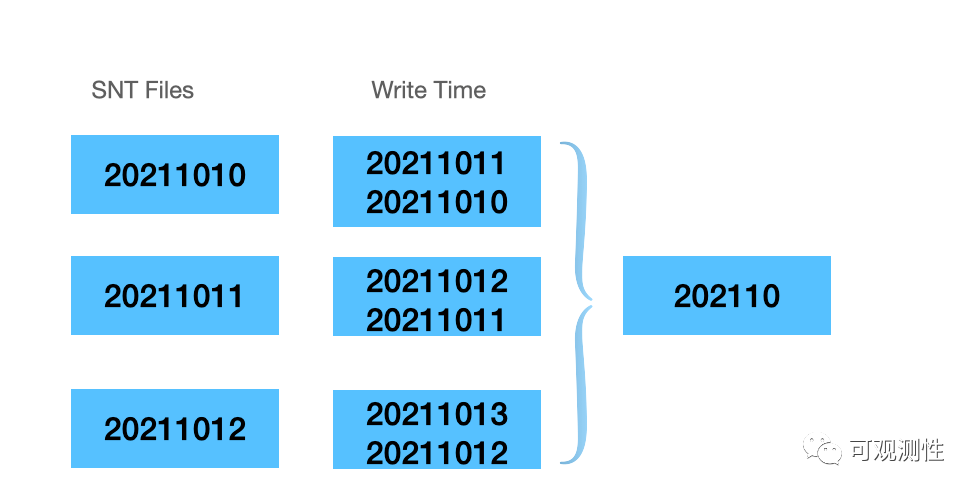
1. push机制下的时间戳和写时间戳可能存在较大的偏移,用户可以乱序写(如下图10月10日的数据可能在10月11日写入),如果使用metric的时间来进行数据驱逐可能会导致错误的过期;
2. 在lindb中,没有influxdb的contionus query以及prometheus的record rule机制,而是实现了一套隐式的Rollup机制,数据会定时将数据聚合成更粗的粒度。这必然会导致不同时间点的数据交叉,若再次以时间对发号器进行分段,不同时间段的分配的id不一致,会导致极其复杂的compaction过程;
3. Metric->id, tags->id的索引映射占用的空间比较大,全局索引可以更好的压缩空间,仅保留一份数据,充分的利用索引多读少写的特性;
之前介绍的是sorted number table,这种文件类型存在一个无法解决的缺陷,就是没有string->id的映射关系,而SST则天然可实现string->数据块。如果再构建一套sst的lsm树来存放这种关系便属于杀鸡用牛刀,写放大过于严重。而B+树则天然的匹配这种场景。
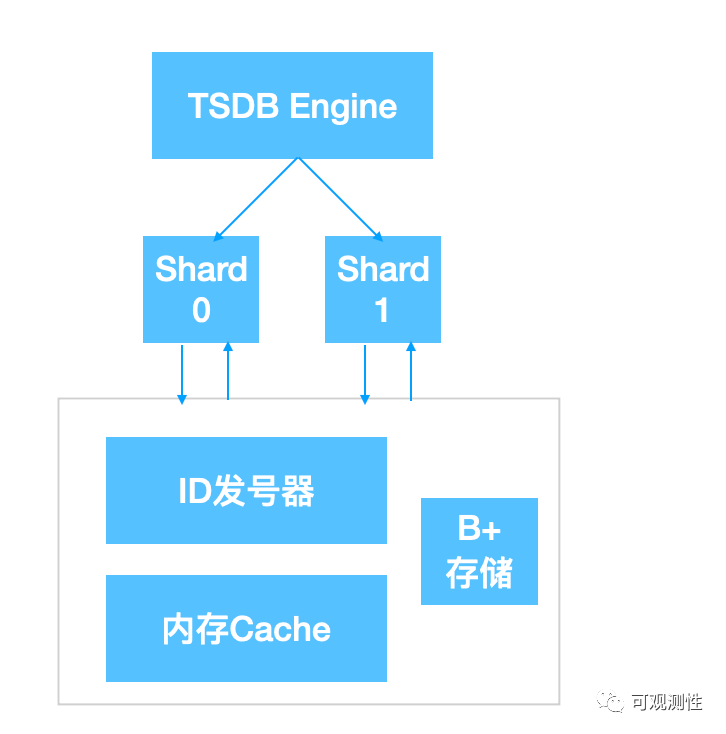
lindb里映射string 到id的机制类似一个Id发号器,前置一层缓存减少磁盘读写,新数据会定时以批的形式刷写回 b+ 进行更新。映射关系有这几种:
metric name -> metric id
metric name+tags -> series id
metric name + tag key -> tag key id
metric name + field name -> field id
14. Minor Compaction
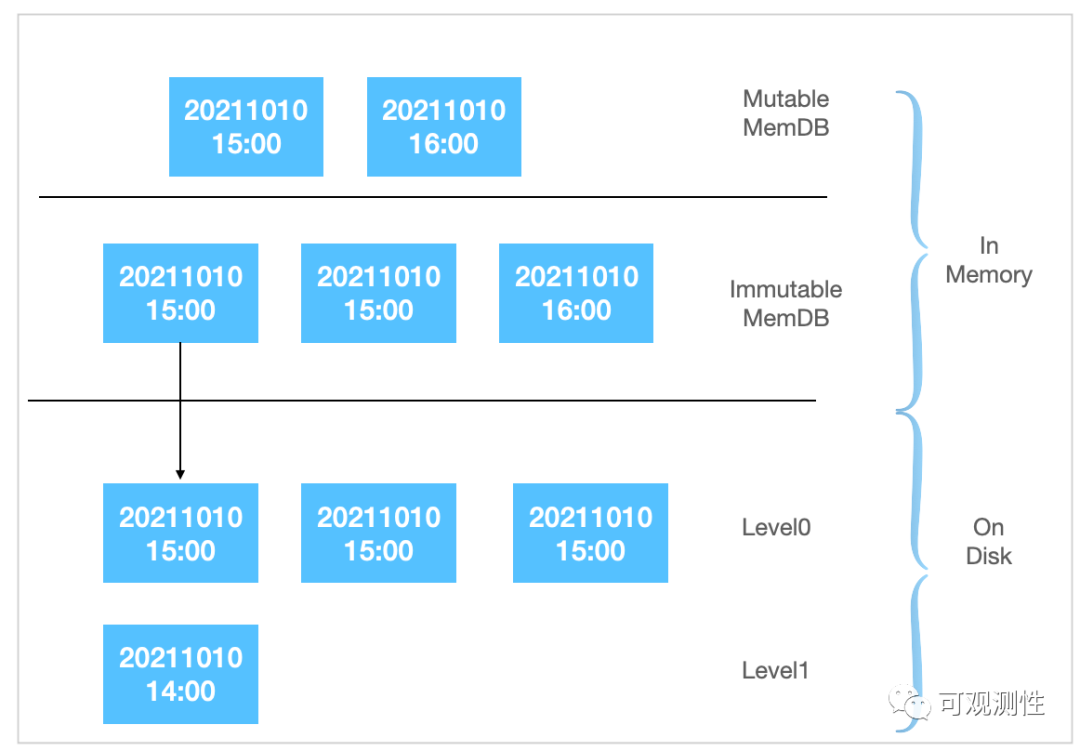
最后介绍一下minor compaction,基本策略也类似leveldb,内存中用链表存放可变和不可变的memtable,当memtable内存占用超限时,会将其置为不可读,然后再进行flush动作。
而针对时序的特性,在 Memtable的list中,则需要根据时间进行分组。图中,可写的memtable同时存在多个时间片,只读的memtable在满足过期时间和数量限制时,会刷写到磁盘的level0上。在查询过程中,需要联合进行查询,同时扫描多个满足条件的memtable和磁盘文件。
Flush策略与LevelDB类似(MemDB大小控制,数量控制,水位控制,外部控制);
