




近两年分布式数据库技术取得非常大的发展,尤其是在当下信创背景下,金融等关键行业的核心系统都采用分布式系统,从最初的怀疑到最终的接受,分布式数据库不断在生产实践中证明自己。今天我们就聊聊分布式数据库的发展变迁。
主从架构
传统的单机数据库,受限于关系型数据库模型的限制,在 ①持久化 ②事务隔离 ③⾼性能 三者之间存在着天然的冲突,因此也被网友称为“单机数据库不可能三角”。持久化和事务隔离是强需求,不支持事务、不能做到持久化的数据库注定不能成为核心,因此在这三个要求中,大多数据库的设计上都选择牺牲一部分性能,或者说通过各种缓存加队列等架构上的优化,在三者之间取得更好的平衡。
但架构设计上优化终究是有上限的,所以单机数据库的瓶颈始终是存在的,尤其是在当前数据量暴增的背景下,这种瓶颈会显得更加突出。
现代数据库都支持主从架构,这种架构的出现基于一个非常朴素的想法,当主库损坏时能够及时切换到从库继续提供服务。但主库损坏的概率其实非常低,从库除了增加运维的工作量,从业务的角度看存在感非常低。主库不断增加的压力,加上从库闲置的投资,架构设计人员开始考虑将部分查询业务分散到从库上。
主从架构算不上是分布式系统,但是基于主从进行读写分离架构设计时,需要从业务层面将两种操作区分开来,分别去调用不同的数据库。为了尽量减少架构变化对业务的侵入,架构设计人员将调用多个数据库的代码抽象出来作为单独的一层,形成了数据库中间件的雏形。
第一代分布式数据库 -- DB Proxy
随着数据量的不断增加,单表的数据量和单库的处理能力逐步达到瓶颈,互联网公司开始对数据库和表进行拆分,比如按地市、按区域将数据存放在两个独立的数据库中。和主从架构的多库调用类似,分库分表之后应用也需要调用多个数据库进行数据更新及查询,因此随着分库分表架构的流行,数据库中间件技术也在不断成熟。最初的数据库中间件是和应用系统部署在一起的,这会给应用维护带来额外的成本,因此这部分被逐步拆分出来形成了独立的产品。
数据库中间件的主要起到代理的作用,应用直接和代理中间件连接,SQL语句通过代理被拆分和重定向,发送到多个数据库,完成操作后再将结果聚合并返回给应用。对于事务来说,还要在多个分库中实现事务的ACID。
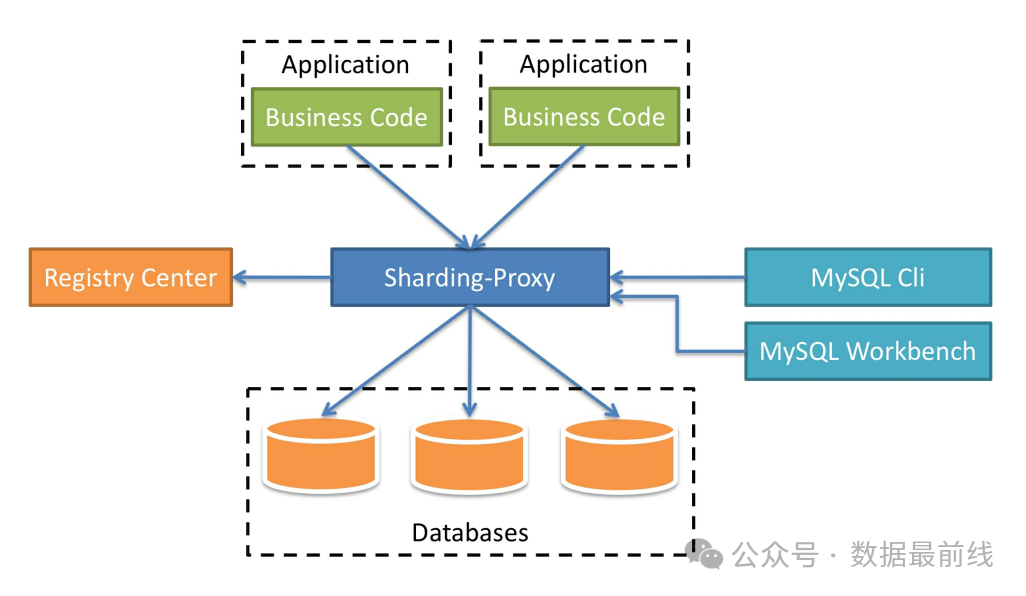
数据库中间件虽然看起来是能满足分布式数据的需求,但其实它只能理解预定好的规则,哪张表需要分表查询,对应的查询需要拆分到哪些库,具体对哪张表、哪个字段进行拆分这些都需要提前配置到代理中间件。所以这其实并不是一个通用的数据库产品,而是一套和业务系统紧耦合的解决方案,每次有新的系统或业务模块投产,都需要结合分库分表规则进行配置。
为了将代码层面的数据规划、逻辑判断同数据库分库分表进行解耦,将这部分工作交由数据库来完成,形成了新一代的分布式数据库。
第二代分布式数据库 -- 键值数据库
第⼆代分布式数据库的出现是由离散数据需求推动的,诞⽣了键值对(Key-Value)型分布式数据库。
键值数据库在经典的事务理论ACID基础上有所取舍,比如HBASE提供行级数据一致性,但放弃了事务;Redis如果要实现和关系型数据库一样严格的持久化,性能也会下降一大截。所以键值数据库结构简单,虽然性能优异、扩展性无敌,但只能作为核心数据库的高性能补充,关键的核心领域,还得是关系型数据库。
第三代分布式数据库 -- NewSQL
NewSQL兴起于Google的Spanner论文,Spanner是谷歌公司设计、开发和部署的可扩展、全球分布式数据库,支持分布式事务和强一致性。之所以能够带动分布式NewSQL的兴起,Spanner实现了两个分布式数据库中的难点:1.提供外部一致性的读取和写入,2.基于特定时间点的跨库全局一致性读。这些特性使得Spanner支持全球范围内一致的备份、MapReduce执行和原子模式变更,即使有事务在执行也不受影响。
即使是分布式事务,Spanner也能为这些事务分配全局有意义的提交时间戳,通过时间戳来反映事务执行顺序,是Spanner保证全局数据一致性的关键。Google生产中心部署的Spanner,采用GPS授时+2台原子钟+4台时间服务器,基于TrueTime服务,可以让分布在全球多个数据中心的Spanner集群时间差能够控制在10ms之内。当然这种需求绝无仅有,如果只是在一个数据中心部署,时间差可以轻松控制在1ms以内。
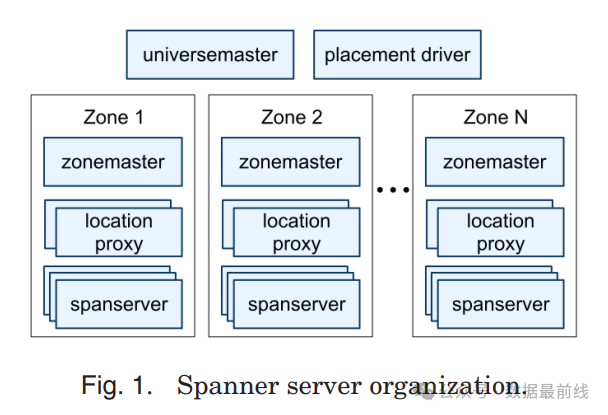
CAP理论告诉我们:⼀个分布式系统最多只能同时满⾜⼀致性(Consistency)、可⽤性(Availability)和分区容错性(Partition tolerance)这三项中的两项。 对于Spanner来说,分区容错性是必须满足的基础要求,强一致性是Spanner的核心价值,所以Spanner满足了一致性和分区容错性,而放弃了可用性。
Google Spanner带火了基于分布式技术的NewSQL数据库,NewSQL最大的特点是使用非B树磁盘存储结构,在上面构建一个兼容SQL语法和事务的兼容层,既可能满足大规模集群带来的扩展性和高性能,也可以尽量减少对应用系统的改造。
总结
如果说关系型数据库是一位中年男人,低调而沉稳,并不喜欢宣扬自己,但是在关键的场合还是会挑起大梁;分布式则是一位积极向上的青壮年,他们不断的进化自己,在多个细分的领域发挥自己的强项。而这两年随着NewSQL技术的发展,分布式数据库也在强化自己的事务能力,逐渐模糊了NewSQL和关系型数据库之间的边界,国产的OceanBase和TiDB等新兴的数据库产品已经在多个行业向关系型数据库发起挑战,未来的NewSQL将会在更多的领域取得更大的成就。
